

There is a lot of talk these days around the AWS Fargate. AWS describes Fargate as a serverless compute engine to run containers without having to manage the underlying server infrastructure or EC2 instances. As such, AWS Fargate can be a good candidate for deployments that need container orchestration, with more advanced features than a simple docker-compose, and less complex than the Kubernetes world. Another potential reason could be that the engineers don’t have time to manage the required EC2 instances for Elastic Container Service. In this blog, we will go through the necessary steps to deploy Nautobot with ECS using AWS Fargate.
AWS ECS/Fargate Components
- ECS Cluster: A platform to run containers. Serves as a logical entity to group tasks and services together and to isolate applications.
- Task definitions: A JSON file to describe container(s) for your application along with the necessary information, like open ports, volumes, etc.
- Tasks: A Task is the instantiation of a task definition within a cluster. It is created when you run a Task directly and launches the container(s) defined in the specified Task definition.
- Services: Service is the orchestration of the above. It is responsible for creating Tasks and guaranteeing that you always have Tasks running. If something goes wrong and a container in a Task fails, the Service is responsible for launching another instance based on the Task definition. Sounds like deployments in Kubernetes, right?
Architecture
Bear in mind that Services or Tasks are running in specific subnets of a VPC, therefore you have to define at which subnets the Fargate components will run. Also, in order to load balance the traffic between containers, an Application or Network Load Balancer is going to be needed. Furthermore, Nautobot requires a database back end (PostgreSQL or MySQL) and a Redis in-memory data store to operate. Since we are deploying in AWS, managed services will be used: Amazon RDS for PostgreSQL and Amazon ElastiCache for Redis. Deployment of those two components is out of the scope of this post, but remember to create a database (named nautobot) before moving on with this post.
As for Nautobot itself, we would need three Services and the respective Task definitions: Nautobot Application, Nautobot Worker, and Nautobot Scheduler. At this point we should mention that you should deploy only one instance of Nautobot Scheduler and one or more of the other Services (based on your traffic), as shown in the diagram below.
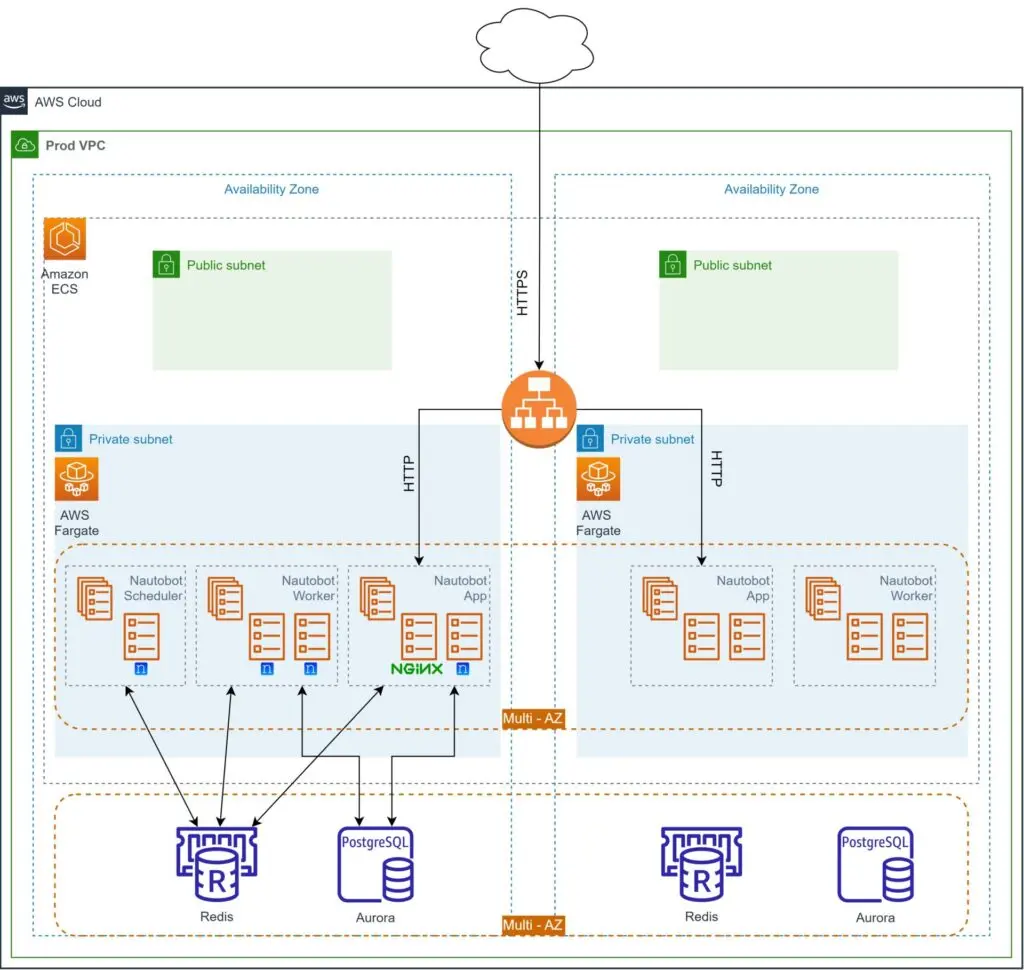
You will notice that there is an Nginx container alongside the Nautobot application. As a best practice, you should have a proper web server in front of the uWSGI server. For more detailed information about the Nautobot architecture, take a look at the official documentation.
Deployment
Load Balancer
The first item you need to deploy in this topology is the Application Load Balancer that will serve the requests to the back end. In order to do that, deploy a Load Balancer with a target group type IP with no targets for now. There are a lot of resources out there on how to do that, so we won’t enter into much detail.
ECS Cluster
As for the Fargate deployment, we will start by deploying the ECS cluster.
- Sign in to the AWS console and search for ECS (Elastic Container Service).
- Go to cluster and click on Create Cluster.
- In the Configuration section, enter the cluster name (i.e.,
nautobot-cluster) and choose the VPC and subnets that will host your cluster. - In the Infrastructure section, you’ll notice that the AWS Fargate is pre-selected for you. Leave it like that and click Create.
Nginx
Before we move forward, Nginx needs a configuration file to operate. You have two solutions around that: use either an external volume to mount the config file or build a new pre-configured Container Image as presented here.
The configuration of Nginx should just pass traffic to localhost on port 8080, and we will expose port 80 (http) for the Nginx container. A simple basic example may be found below for the nginx.conf and the Dockerfile.
# nginx.conf
events {
worker_connections 1024;
}
http {
resolver 127.0.0.1;
upstream docker-nautobot-http {
server 127.0.0.1:8080;
}
server {
listen 80;
access_log off;
location / {
proxy_pass http://docker-nautobot-http;
proxy_set_header X-Forwarded-Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Proto $scheme;
add_header P3P 'CP="ALL DSP COR PSAa PSDa OUR NOR ONL UNI COM NAV"';
}
}
}
# Dockerfile for Nginx
FROM nginx:stable
COPY nginx.conf /etc/nginx/nginx.conf
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
If you are using a private Amazon Elastic Container Registry (ECR), be sure to log in.
aws ecr get-login-password --region | docker login --username AWS --password-stdin .dkr.ecr..amazonaws.com
Then we build, tag, and push the container image to a private ECR repository.
docker build -t .dkr.ecr..amazonaws.com/nginx:nautobot .
docker push .dkr.ecr..amazonaws.com/nginx:nautobot
Nautobot App Task Definition
Next, back in the ECS console, go to Task definitions on the left in order to create the three task definitions that are needed (Nautobot App, Nautobot Worker, and Nautobot Scheduler).
For the Nautobot App task definition:
- Click Create new task definition.
- Add a name for the task definition family (i.e.,
nautobot-app-definition). - Give a container name
nautobotandnetworktocode/nautobot:1.5-py3.9as the image URI. Please check the Nautobot documentation for versions, etc. Also, keep checking for the Nautobot 2.0 release. 😉 - Configure port 8080 as a container port in the port mappings section.
- Then we should add the environmental variables that Nautobot needs; in order to simplify the process, you can take them from a file (stored in an S3 bucket) as we did here, which allowed us to use
Add environment file. The sensitive ones (e.g., passwords) may be retrieved from AWS Secrets Manager or AWS Systems Manager by using theValueFromoption. More information can be found in ECS developer guides for passing environment variables and retrieving secrets. As a minimum, the below values are essential. Make sure to change these values to match your infra!
# General settings
NAUTOBOT_ALLOWED_HOSTS=*
NAUTOBOT_BANNER_TOP="Local Production"
NAUTOBOT_SECRET_KEY=<random_key>
NAUTOBOT_LOG_LEVEL=INFO
NAUTOBOT_METRICS_ENABLED=True
# Database settings
NAUTOBOT_DB_NAME=nautobot
NAUTOBOT_DB_PASSWORD=<db_password>
NAUTOBOT_DB_HOST=<rds_host_endpoint>
# Redis settings
NAUTOBOT_REDIS_HOST=<elasticache_host_endpoint>
NAUTOBOT_REDIS_PORT=6379
# Napalm settings
NAUTOBOT_NAPALM_USERNAME=<napalm_username>
NAUTOBOT_NAPALM_PASSWORD=<napalm_password>
NAUTOBOT_NAPALM_TIMEOUT=5
# Superuser settings
NAUTOBOT_CREATE_SUPERUSER=true
NAUTOBOT_SUPERUSER_NAME=admin
NAUTOBOT_SUPERUSER_EMAIL=admin@example.com
NAUTOBOT_SUPERUSER_PASSWORD=admin
NAUTOBOT_SUPERUSER_API_TOKEN=0123456789abcdef0123456789abcdef01234567- For Health Check, it is good to add the below configuration in the respective fields.
Command: CMD-SHELL, curl -f http://localhost/health || exit 1
Interval: 30
Timeout: 10
StartPeriod: 60
Retries: 5- Press Add more containers to configure the Nginx container. Configure name (nginx) and image URI (what we used to push to ECR previously), and choose Yes in essential.
- For the port mappings part, map port 80 (http).
- On the next page, leave Fargate as the selected App environment; set the OS to
Linux/x86_64; and give 2vCPU and 4 GB of RAM as size. - Select the necessary AWS roles for the execution (i.e.,
ecsTaskExecutionRole) based on your environment (more details here). - Create the Task Definition.
Because we are a Network Automation company, seriously it would be a shame to go through all these steps. Instead, you could have just clicked “Create a new task definition from JSON” in step 1, copy paste the below JSON, change the <variables>, and click the big orange button. This is the approach that we will take for the subsequent tasks.
{
"requiresCompatibilities": [
"FARGATE"
],
"family": "nautobot-app-definition",
"containerDefinitions": [
{
"name": "nautobot",
"image": "networktocode/nautobot:1.5-py3.9",
"portMappings": [
{
"name": "nautobot-8080-tcp",
"containerPort": 8080,
"hostPort": 8080,
"protocol": "tcp",
"appProtocol": "http"
}
],
"essential": true,
"environmentFiles": [
{
"value": "arn:aws:s3:::/",
"type": "s3"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-create-group": "true",
"awslogs-group": "/ecs/nautobot-app-definition",
"awslogs-region": "",
"awslogs-stream-prefix": "ecs"
}
},
"healthCheck": {
"command": [
"CMD-SHELL",
"curl -f http://localhost/health || exit 1"
],
"interval": 30,
"timeout": 10,
"retries": 5,
"startPeriod": 60
}
},
{
"name": "nginx",
"image": ".dkr.ecr..amazonaws.com/nginx:nautobot",
"portMappings": [
{
"name": "nginx-80-tcp",
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp",
"appProtocol": "http"
}
],
"essential": true,
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-create-group": "true",
"awslogs-group": "/ecs/nautobot-app-definition",
"awslogs-region": "",
"awslogs-stream-prefix": "ecs"
}
}
}
],
"networkMode": "awsvpc",
"cpu": "2048",
"memory": "4096",
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
},
"executionRoleArn": "arn:aws:iam:::role/ecsTaskExecutionRole"
}
Nautobot Worker Task Definition
For the Nautobot Worker definition, repeat the same steps as above (either from console or by using JSON) to create another Task definition, with the below changes:
- Make sure to change the task definition family (i.e.,
nautobot-worker-definition). - Only configure the nautobot container as
nautobot-worker, ignore/remove the Nginx one. - Remove port mappings (not needed).
- Add the Docker configuration command
nautobot-server,celery,worker; this is the comma-separated representation of equivalentnautobot-server celery worker. If you are using JSON, it should look like the following, nested undercontainerDefinitions.
"command": [
"nautobot-server",
"celery",
"worker"
],- Change the container Health checks to match the following:
"healthCheck": {
"command": ["CMD", "bash", "-c", "nautobot-server celery inspect ping --destination celery@$HOSTNAME"],
"interval": 30,
"timeout": 10,
"retries": 5,
"startPeriod": 60
}Nautobot Scheduler Task Definition
For the Nautobot Scheduler definition, the config will be the same as Nautobot Worker with some changes:
- Change the task definition family name (i.e.,
nautobot-scheduler-definition). - Again only Nautobot container. Haven’t you seen the architecture design yet?!
- Again, we do not need port mappings; so remove them.
- And the Docker config command should be
nautobot-server,celery,beat. If you are using JSON, it should look like the following.
"command": [
"nautobot-server",
"celery",
"beat"
],- Don’t add any container health check.
All the other config should be the same as the worker.
Nautobot App Service
Now for the fun part. Let’s create services in order to run all those tasks we defined previously. As you can imagine, we need three services, one for each task.
First, let’s create the Nautobot App service.
- Go to your ECS cluster and click Create on the services list at the bottom.
- Specify Launch type Fargate.
- Choose a Service as Application type.
- Choose the Nautobot App task definition family from before.
- Specify a Service Name (i.e.,
nautobot-app-service). - Choose Replica as the service type and define the number of desired tasks (replicas).
- In the Networking tab, VPC and subnets that the ECS Cluster is deployed on should already be populated, but no harm to check.
- Then specify your Load Balancer from
Load balancingoptions. You will notice that you can create a new one, or use an existing one if you already provisioned it. For theContainer to load balance, choose Nginx with port 80. And onTarget Groupparameters, set the “Health check grace period” to 60s and the path to/health/. - Click Create and wait for the Service to spin up the Task. 🙂
Again, instead of jumping through all these clickety hoops, you could change the <variables> and use the below JSON file.
{
"serviceName": "nautobot-app-service",
"cluster": "nautobot-cluster",
"loadBalancers": [
{
"targetGroupArn": "",
"containerName": "nginx",
"containerPort": 80
}
],
"healthCheckGracePeriodSeconds": 60,
"desiredCount": 1,
"launchType": "FARGATE",
"platformVersion": "LATEST",
"taskDefinition": "nautobot-app-definition",
"networkConfiguration": {
"awsvpcConfiguration": {
"subnets": [
"",
"",
""
],
"securityGroups": [
""
],
"assignPublicIp": "ENABLED"
}
},
"schedulingStrategy": "REPLICA",
"deploymentController": {
"type": "ECS"
}
}
Save the file locally and run.
aws ecs create-service --cli-input-json file:///tmp/nautobot-app-service.json
Nautobot Worker and Scheduler Services
Repeat the above steps for the Nautobot Worker and Nautobot Scheduler services (nautobot-worker-service, nautobot-scheduler-service), without configuring a Load Balancer this time. Nautobot Worker and Scheduler communicate directly with the database and Redis to execute tasks. Remember, Nautobot Scheduler must have only one replica (instance). For the other two, it depends on your traffic/load. We would suggest exploring Auto-scaling based on CPU and memory load and the usage of the application.
Conclusion
At this point (or 5 to 10 minutes later), if everything has gone according to the plan, you should be able to see this in your ECS Cluster:
ECS Cluster Services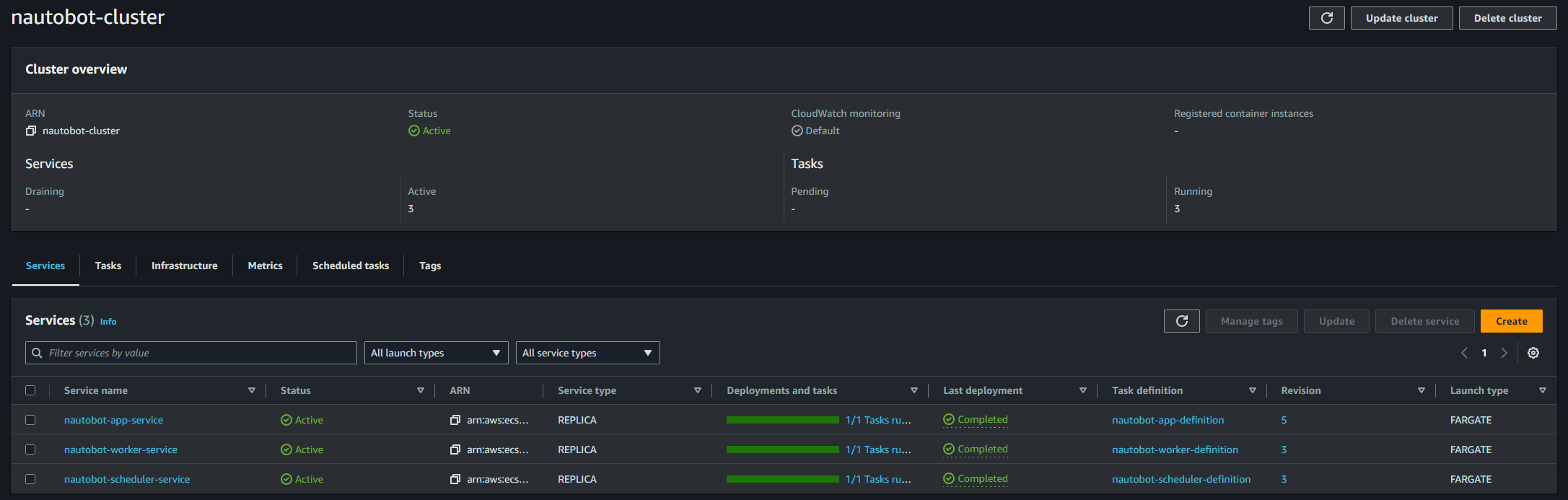
ECS Cluster Tasks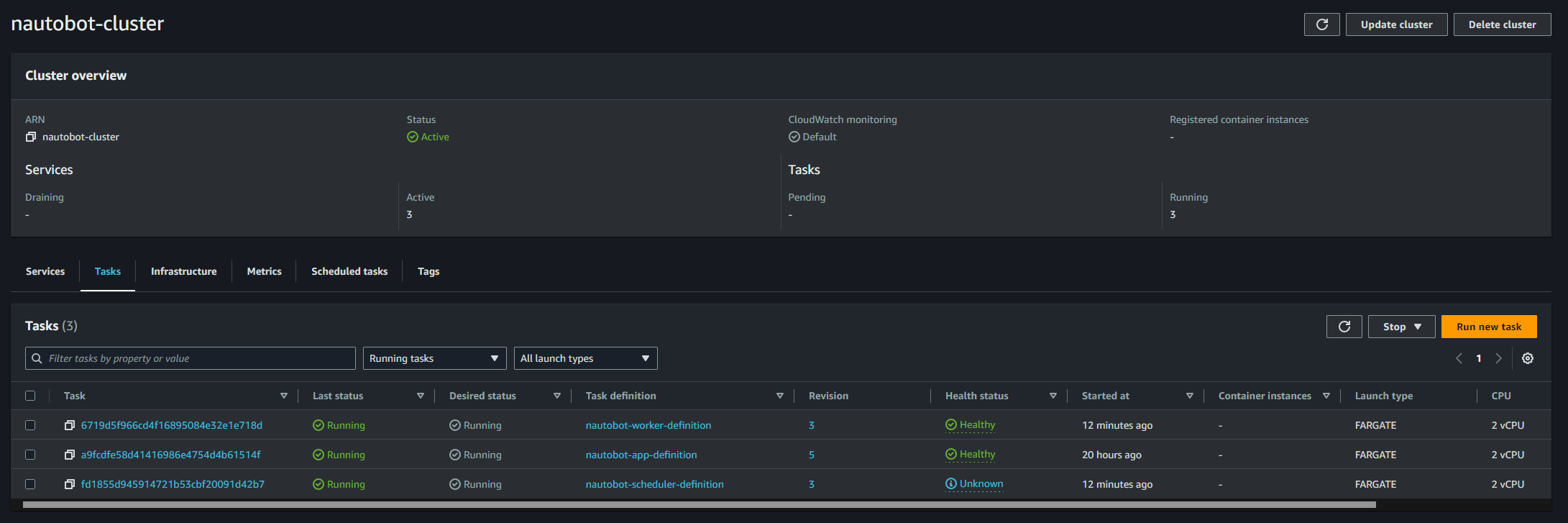
In order to verify that Nautobot works end-to-end, go back to the Load Balancer, copy the DNS name URL, and open it in your favorite browser. With just a little bit of luck, you should be able to see Nautobot home view.
Note: In the context of things, this whole deployment ideally would be part of an Infrastructure as Code approach. Classical candidates for this would be Terraform and Cloudformation. If, on the other hand, you prefer to have the full power of a programming language, CDKTF or Pulumi are your friends. 😉
In case something is not working as expected, don’t fret—there are a lot prerequisites in achieving this deployment. We would suggest to consult with your SREs and/or cloud engineers—the usual suspects are Security Groups and IAM. 🙂 Feel free to ping us in NTC Slack for anything you may need. Cheers!
-Gerasimos
Tags :
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!