In every automated workflow there should (read “must”) be at least one stage where the outcome of the changes applied to a target system are what we really expected to see. There are multiple ways to do that: for example, compare the actual state of our system against a predefined intended state, generate a difference between pre- and post-change, or simply do some operational checks. In Network to Code we put a lot of focus on this stage, as we believe it is the crucial bit that makes automation trustworthy. However, looking around the community, either open-source or commercial, we could not find any valuable solution that could cover the rich array of cases that we work with. So, we decided to have some fun and build our own open-source product. One of the most relevant requirements was to have a library that was not only Network Automation oriented but that could be used in different sectors, such as DevOps, software development, and others. After some work we finally released jdiff!
What jdiff Is
jdiff is a lightweight Python library allowing you to examine structured data. Since JSON is the most common format around the IT world, jdiff provides an interface to intelligently compare, via key presense/absense and value comparison, JSON data objects. The library heavily relies on JMESPath for traversing the JSON object and finding the values to be evaluated.
Use Cases
jdiff has been developed around diffing and testing structured data returned from Network APIs and libraries (such as TextFSM) but is equally useful when working or dealing with data returned from APIs. In short, if it’s in JSON format, we can work with it!
Our primary use case is the examination of structured data returned from networking devices, such as:
- Compare the operational state of network devices pre and post change.
- Compare operational state of a device vs a “known healthy” state.
- Compare state of similar devices, such as a pair of leafs or a pair of backbone routers.
- Compare operational state of a component (interface, vrf, bgp peering, etc.) migrated from one device to another.
However, we found the library fits other use cases where structured data needs to be operated on, and it’s especially useful when working or dealing with data returned from APIs.
Intelligent Comparison
The library provides the ability to ask more intelligent questions of a given data structure. Comparisons of data such as “Is my pre change state the same as my post change state”, is not that interesting of a comparison. The library intends to ask intelligent questions like:
- Is the route table within 10% of routes before and after a change?
- Is all of the interfaces that were up before the change, still up?
- Are there at least 10k sessions of traffic on my firewall?
- Is there there at least 2 interfaces up within lldp neighbors?
Check Types
As stated above, we wanted to cover the most common cases of pre- and post-change checks. Based on the experience made across several customer engagements, we came up with five check types:
exact_match: the keys and values must match exactly between two objects.tolerance: the keys must match and the values can differ according to the ‘tolerance’ value provided.parameter_match: a reference key and value is provided and its presence (or absence) is checked in the provided object.regex: a reference regex pattern is provided and is used to find a match in the provided object.operator: similar to parameter match, but the reference includes several different possible operators: ‘in’, ‘bool’, ‘string’, and numerical comparison with ‘int’ and ‘float’ to check against.
More information regarding the check types can be found here.
Workflow
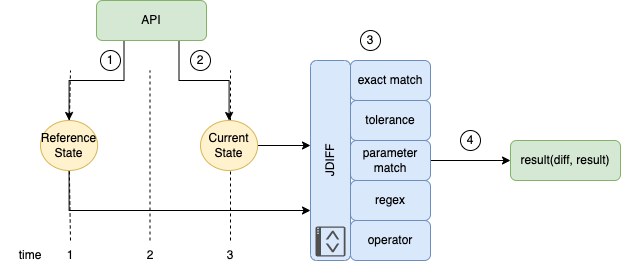
Taking as an example a network configuration change through automation, jdiff will follow the below workflow:
- A reference state object is retrieved or assembled from the network device. The structured data may be from an API, another Python module/library, retrieved from a saved file, or constructed programmatically.
- Some time passes where some change to the network device might occur (configuration change, for example). A new set of data is retrieved or assembled, often using a similar process used to get the reference state.
- The reference state is then compared to the current state via the
jdiff library using one of the CheckTypes.
- The
evaluate method is called on the check object, and the result is returned.
Comparison and testing of the data structures in jdiff is performed through one of the built-in CheckType type objects, which are listed above. A jdiffCheckType accepts two Python dictionaries as input: the reference object and the comparison object. The reference object is used as the intended or accepted state and its keys and values are compared against the key-value pairs in the comparison object.
It’s worth pointing out that jdiff is focused on the comparison of the two objects and the testing of the values, not retrieving the data from the external system. However, we’ve also included a method of extracting portions of the data for comparison. In many cases in data comparison, we aren’t interested in the whole piece of data. We’ve provided extract_data_from_json utility to extract subsets of a larger data object.
As an example, in this case of the object below, we are only interested in comparing the value of a single key-value pair from each item in the interfaces dictionary contained within the response.
>>> from jdiff import extract_data_from_json
>>> reference_data = {
"jsonrpc": "2.0",
"id": "EapiExplorer-1",
"result": [
{
"interfaces": {
"Management1": {
"lastStatusChangeTimestamp": 1626247820.0720868,
"lanes": 0,
"name": "Management1",
"interfaceStatus": "connected",
"autoNegotiate": "success",
"burnedInAddress": "08:00:27:e6:b2:f8",
"loopbackMode": "loopbackNone",
"interfaceStatistics": {
"inBitsRate": 3582.5323982177174,
"inPktsRate": 3.972702352461616,
"outBitsRate": 17327.65267220522,
"updateInterval": 300,
"outPktsRate": 2.216220664406746
}
}
}
}
]
}
After getting the response data from an external system, we’ll create a query (based on a customized version of JMESPath syntax) to extract the key-value pair that we want to use for comparison. With the query and the data, we can call extract_data_from_json to get the subset of data we are interested in using.
>>> my_jmspath = "result[*].interfaces.*.[$name$,interfaceStatus]"
>>> reference_value = extract_data_from_json(reference_data, my_jmspath)
>>> reference_value
[{'Management1': {'interfaceStatus': 'connected'}}]
This type of logic to extract keys and value from the object is called anchor logic and in our expression is delimited by $ character. In the example above we want to anchor the interfaceStatus to its own interface name, hence we need to anchor name on our expression.
CheckTypes Explained
exact_match
Check type exact_match is concerned with the value of the elements within the data structure. The key-value pairs should match between the reference and comparison data. A diff is generated between the two data sets and tested to see whether all the keys and values match.
As some outputs might be too verbose or include fields that constantly change (e.g., interface counter), it is possible to exclude a portion of data traversed by JMESPath by defining a list of excluded keys.
Examples:
>>> from jdiff import CheckType
>>> reference_data = {
"jsonrpc": "2.0",
"id": "EapiExplorer-1",
"result": [
{
"interfaces": {
"Management1": {
"lastStatusChangeTimestamp": 1626247820.0720868,
"lanes": 0,
"name": "Management1",
"interfaceStatus": "connected",
"autoNegotiate": "success",
"burnedInAddress": "08:00:27:e6:b2:f8",
"loopbackMode": "loopbackNone",
"interfaceStatistics": {
"inBitsRate": 3582.5323982177174,
"inPktsRate": 3.972702352461616,
"outBitsRate": 17327.65267220522,
"updateInterval": 300,
"outPktsRate": 2.216220664406746
}
}
}
}
]
}
>>> comparison_data = {
"jsonrpc": "2.0",
"id": "EapiExplorer-1",
"result": [
{
"interfaces": {
"Management1": {
"lastStatusChangeTimestamp": 1626247821.123456,
"lanes": 0,
"name": "Management1",
"interfaceStatus": "down",
"autoNegotiate": "success",
"burnedInAddress": "08:00:27:e6:b2:f8",
"loopbackMode": "loopbackNone",
"interfaceStatistics": {
"inBitsRate": 3403.4362520883615,
"inPktsRate": 3.7424095978179257,
"outBitsRate": 16249.69114419833,
"updateInterval": 300,
"outPktsRate": 2.1111866059750692
}
}
}
}
]
}
Create an instance of CheckType object with exact_match as check-type argument.
<span role="button" tabindex="0" data-code=">>> my_check = CheckType.create(check_type="exact_match")
>>> my_check
>>>
>>> my_check = CheckType.create(check_type="exact_match")
>>> my_check
>>> <jdiff.check_types.ExactMatchType object at 0x10ac00f10>
Use the evaluate method to return the result.
>>> result = my_check.evaluate(reference_data, comparison_data)
>>> result
>>> ({'result': {'interfaces': {'Management1': {'lastStatusChangeTimestamp': {'new_value': 1626247821.123456,
'old_value': 1626247820.0720868},
'interfaceStatus': {'new_value': 'down', 'old_value': 'connected'},
'interfaceStatistics': {'inBitsRate': {'new_value': 3403.4362520883615,
'old_value': 3582.5323982177174},
'inPktsRate': {'new_value': 3.7424095978179257,
'old_value': 3.972702352461616},
'outBitsRate': {'new_value': 16249.69114419833,
'old_value': 17327.65267220522},
'outPktsRate': {'new_value': 2.1111866059750692,
'old_value': 2.216220664406746}}}}}},
False)
As we can see, we return a tuple containing a diff between the pre and post data as well as a boolean for the overall test result. In this case a difference has been found, so the result of the test is False.
Let’s see a better way to run exact_match for this specific case. Because there are a lot of extra key-value pairs, some of which change all the time, we are interested only in interfaceStatus. In this case we can use the extract_data_from_json utility, to extract only the value from the keys we are interested in and discard the rest.
>>> my_jmspath = "result[*].interfaces.*.[$name$,interfaceStatus]"
>>> reference_value = extract_data_from_json(reference_data, my_jmspath)
>>> reference_value
[{'Management1': {'interfaceStatus': 'connected'}}]
>>> comparison_value = extract_data_from_json(comparison_data, my_jmspath)
>>> comparison_value
[{'Management1': {'interfaceStatus': 'down'}}]
>>> result = my_check.evaluate(reference_value, comparison_value)
>>> result
({'Management1': {'interfaceStatus': {'new_value': 'down',
'old_value': 'connected'}}},
False)
In this case, we only want to compare the value of a single key, the interfaceStatus key. So we define the expression to take the name and the interfaceStatus values from all the interface objects in the data object.
Tolerance
The tolerance test checks for the deviation between the value or count of the reference and comparison values. A tolerance is defined and passed to the check along with the comparison and reference values.
The tolerance argument must be a float > 0. The calculation is percentage based, and the test of the values may be +/- the tolerance percentage.
This check can test whether the difference between two values is within a specified tolerance percentage. It could be useful in cases where values like route metrics or optical power levels fluctuate by a small amount. It might be desirable to treat these values as equal if the deviation is within a given range. You can pass in the result of len() to count the number of objects returned within your data.
Let’s have a look at a couple of examples:
>>> reference_data = {
... "global": {
... "peers": {
... "10.1.0.0": {
... "address_family": {
... "ipv4": {
... "accepted_prefixes": 900,
... "received_prefixes": 999,
... "sent_prefixes": 1011
... },
... "ipv6": {
... "accepted_prefixes": 1000,
... "received_prefixes": 1000,
... "sent_prefixes": 1000
... }
... },
... "description": "",
... "is_enabled": True,
... "is_up": True,
... "local_as": 4268360780,
... "remote_as": 67890,
... "remote_id": "0.0.0.0",
... "uptime": 1783
... }
... }
... }
... }
>>> comparison_data = {
... "global": {
... "peers": {
... "10.1.0.0": {
... "address_family": {
... "ipv4": {
... "accepted_prefixes": 500,
... "received_prefixes": 599,
... "sent_prefixes": 511
... },
... "ipv6": {
... "accepted_prefixes": 1000,
... "received_prefixes": 1000,
... "sent_prefixes": 1000
... }
... },
... "description": "",
... "is_enabled": True,
... "is_up": True,
... "local_as": 4268360780,
... "remote_as": 67890,
... "remote_id": "0.0.0.0",
... "uptime": 1783
... }
... }
... }
... }
>>> my_check = CheckType.create("tolerance")
We will define an expression for the values we want to test and extract from the reference and comparison objects.
>>> my_jmspath = "global.$peers$.*.*.ipv4.[accepted_prefixes,received_prefixes,sent_prefixes]"
>>> reference_value = extract_data_from_json(reference_data, my_jmspath)
>>> reference_value
[{'10.1.0.0': {'accepted_prefixes': 900,
'received_prefixes': 999,
'sent_prefixes': 1011}}]
>>> comparison_value = extract_data_from_json(comparison_data, my_jmspath)
[{'10.1.0.0': {'accepted_prefixes': 500,
'received_prefixes': 599,
'sent_prefixes': 511}}]
Define a tolerance percentage.
Pass the extracted values and tolerance as arguments to the evaluate method.
>>> actual_results = my_check.evaluate(reference_value, comparison_value, tolerance=my_tolerance)
The tolerance check returns the values that differ by more than 10%.
>>> actual_results
({'10.1.0.0': {'accepted_prefixes': {'new_value': 500, 'old_value': 900},
'received_prefixes': {'new_value': 599, 'old_value': 999},
'sent_prefixes': {'new_value': 511, 'old_value': 1011}}},
False)
The last example fails, because none of the values are within 10% of the old_value.
Parameter Match
The parameter_match check provides a way to test key-value pairs against baseline values.
The check defines baseline key-value pairs in a Python dictionary. Additionally, mode is set to one of match or no-match, which specifies whether the data should match the baseline, or not.
The test fails if:
- Specified key-value pairs in the data do not match the baseline and mode is set to match.
- Specified key-value pairs in the data match the baseline and mode is set to no-match.
Any key-value pairs present in the data but not in the baseline are ignored by this check.
In data, this could be a state or status key.
For example, in network data:
>>> actual_data = {
... "jsonrpc": "2.0",
... "id": "EapiExplorer-1",
... "result": [
... {
... "interfaces": {
... "Management1": {
... "lastStatusChangeTimestamp": 1626247821.123456,
... "lanes": 0,
... "name": "Management1",
... "interfaceStatus": "down",
... "autoNegotiate": "success",
... "burnedInAddress": "08:00:27:e6:b2:f8",
... "loopbackMode": "loopbackNone",
... "interfaceStatistics": {
... "inBitsRate": 3403.4362520883615,
... "inPktsRate": 3.7424095978179257,
... "outBitsRate": 16249.69114419833,
... "updateInterval": 300,
... "outPktsRate": 2.1111866059750692
... }
... }
... }
... }
... ]
... }
>>> my_check = CheckType.create("parameter_match")
>>> my_jmspath = "result[*].interfaces.*.[$name$,interfaceStatus,autoNegotiate]"
>>> actual_value = extract_data_from_json(actual_data, my_jmspath)
This test requires a mode argument; match in this case matches the keys and values in the “params” to the keys and values in the data.
>>> intended_value = {
"interfaceStatus": "connected",
"autoNegotiate": "success"
}
>>> actual_results = my_check.evaluate(
intended_value,
actual_value,
mode = "match"
)
>>> actual_results
({'Management1': {'interfaceStatus': 'down'}}, False)
mode: no-match – returns the keys and values from the test object that do not match the keys and values provided in “params”
>>> actual_results = my_check.evaluate(
intended_value,
actual_value,
mode = "no-match",
)
>>> actual_results
({'Management1': {'autoNegotiate': 'success'}}, False
Regex
The regex check type evaluates data against a regular expression passed as an argument to the evaluate method. Similar to parameter_match check, the match and no-match modes are supported.
Let’s run an example where we want to check the burnedInAddress key has a string representing a MAC address as value.
>>> actual_data = {
... "jsonrpc": "2.0",
... "id": "EapiExplorer-1",
... "result": [
... {
... "interfaces": {
... "Management1": {
... "lastStatusChangeTimestamp": 1626247821.123456,
... "lanes": 0,
... "name": "Management1",
... "interfaceStatus": "down",
... "autoNegotiate": "success",
... "burnedInAddress": "08:00:27:e6:b2:f8",
... "loopbackMode": "loopbackNone",
... "interfaceStatistics": {
... "inBitsRate": 3403.4362520883615,
... "inPktsRate": 3.7424095978179257,
... "outBitsRate": 16249.69114419833,
... "updateInterval": 300,
... "outPktsRate": 2.1111866059750692
... }
... }
... }
... }
... ]
... }
We define the regex for matching a MAC address string. Then we define the path query to extract the data and create the check.
>>> mac_regex = "^([0-9a-fA-F]{2}:){5}([0-9a-fA-F]{2})$"
>>> path = "result[*].interfaces.*.[$name$,burnedInAddress]"
>>> check = CheckType.create(check_type="regex")
>>> actual_value = extract_data_from_json(actual_data, path)
>>> actual_value
[{'Management1': {'burnedInAddress': '08:00:27:e6:b2:f8'}}]
>>> result = check.evaluate(mac_regex, actual_value, mode="match")
>>> result
({}, True)
And for the no-match mode:
>>> result = check.evaluate(mac_regex, actual_value, mode="no-match")
>>> result
({'Management1': {'burnedInAddress': '08:00:27:e6:b2:f8'}}, False)
Operator
The operator check is a collection of more specific checks divided into categories. Only one of the specific checks can be selected and used for evaluation when defining operator. Here you can find the full list of the available operator categories and individual checks.
Example:
>> data = {
... "jsonrpc": "2.0",
... "id": "EapiExplorer-1",
... "result": [
... {
... "vrfs": {
... "default": {
... "peerList": [
... {
... "linkType": "external",
... "localAsn": "65130.1100",
... "peerAddress": "7.7.7.7",
... "lastEvent": "NoEvent",
... "bgpSoftReconfigInbound": "Default",
... "state": "Connected",
... "asn": "1.2354",
... "routerId": "0.0.0.0",
... "prefixesReceived": 101,
... "maintenance": False,
... "autoLocalAddress": "disabled",
... "lastState": "NoState",
... "establishFailHint": "Peer is not activated in any address-family mode",
... "maxTtlHops": None,
... "vrf": "default",
... "peerGroup": "EVPN-OVERLAY-SPINE",
... "idleReason": "Peer is not activated in any address-family mode",
... },
... {
... "linkType": "external",
... "localAsn": "65130.1100",
... "peerAddress": "10.1.0.0",
... "lastEvent": "Stop",
... "bgpSoftReconfigInbound": "Default",
... "state": "Idle",
... "asn": "1.2354",
... "routerId": "0.0.0.0",
... "prefixesReceived": 50,
... "maintenance": False,
... "autoLocalAddress": "disabled",
... "lastState": "Active",
... "establishFailHint": "Could not find interface for peer",
... "vrf": "default",
... "peerGroup": "IPv4-UNDERLAY-SPINE",
... "idleReason": "Could not find interface for peer",
... "localRouterId": "1.1.0.1",
... }
... ]
... }
... }
... }
... ]
... }
operator checks require a mode argument, which specifies the operator logic to apply and operator_data required for the mode defined.
>>> path = "result[0].vrfs.default.peerList[*].[$peerAddress$,peerGroup,vrf,state]"
>>> check_args = {"params": {"mode": "all-same", "operator_data": True}}
>>> check = CheckType.create("operator")
>>> value = extract_data_from_json(data, path)
>>> value
[{'7.7.7.7': {'peerGroup': 'EVPN-OVERLAY-SPINE', 'vrf': 'default', 'state': 'Connected'}}, {'10.1.0.0': {'peerGroup': 'IPv4-UNDERLAY-SPINE', 'vrf': 'default', 'state': 'Idle'}}]
>>> result = check.evaluate(check_args, value)
We are looking for peers that have the same peerGroup, vrf, and state. Return peer groups that aren’t the same.
>>> result
([{'7.7.7.7': {'peerGroup': 'EVPN-OVERLAY-SPINE',
'vrf': 'default',
'state': 'Connected'}},
{'10.1.0.0': {'peerGroup': 'IPv4-UNDERLAY-SPINE',
'vrf': 'default',
'state': 'Idle'}}],
False)
Let’s now look to an example for the in operator. Keeping the same data and class object as above:
>>> check_args = {"params": {"mode": "is-in", "operator_data": [20, 40, 50]}}
>>> path = "result[0].vrfs.default.peerList[*].[$peerAddress$,prefixesReceived]"
>>> value = extract_data_from_json(data, path)
>>> value
[{'7.7.7.7': {'prefixesReceived': 101}},
{'10.1.0.0': {'prefixesReceived': 50}}]
We are looking for prefixesReceived value in the operator_data list.
>>> result = check.evaluate(check_args, value)
>>> result
([{'7.7.7.7': {'prefixesReceived': 101}}], False)
What about str operator?
>>> path = "result[0].vrfs.default.peerList[*].[$peerAddress$,peerGroup]"
>>> check_args = {"params": {"mode": "contains", "operator_data": "EVPN"}}
>>> value = extract_data_from_json(data, path)
>>> value
[{'7.7.7.7': {'peerGroup': 'EVPN-OVERLAY-SPINE'}},
{'10.1.0.0': {'peerGroup': 'IPv4-UNDERLAY-SPINE'}}]
>>> result = check.evaluate(check_args, value)
>>> result
([{'10.1.0.0': {'peerGroup': 'IPv4-UNDERLAY-SPINE'}}], False)
Can you guess what would be the outcome for an int, float operator?
>>> path = "result[0].vrfs.default.peerList[*].[$peerAddress$,prefixesReceived]"
>>> check_args = {"params": {"mode": "is-gt", "operator_data": 20}}
>>> value = extract_data_from_json(data, path)
>>> value
[{'7.7.7.7': {'prefixesReceived': 101}},
{'10.1.0.0': {'prefixesReceived': 50}}]
>>> result = check.evaluate(check_args, value)
>>> result
([], True)
You can find a full array of examples under tests folder in the repo.