Blog Detail


Nautobot v2.0 was recently released, and we’re excited to share the new features and important changes it brings to the network automation community! We’re currently hard at work on the next release (v2.1), and by the end of 2023 we will provide some insight into what it and the rest of the v2 release train will bring.
IPAM Enhancements
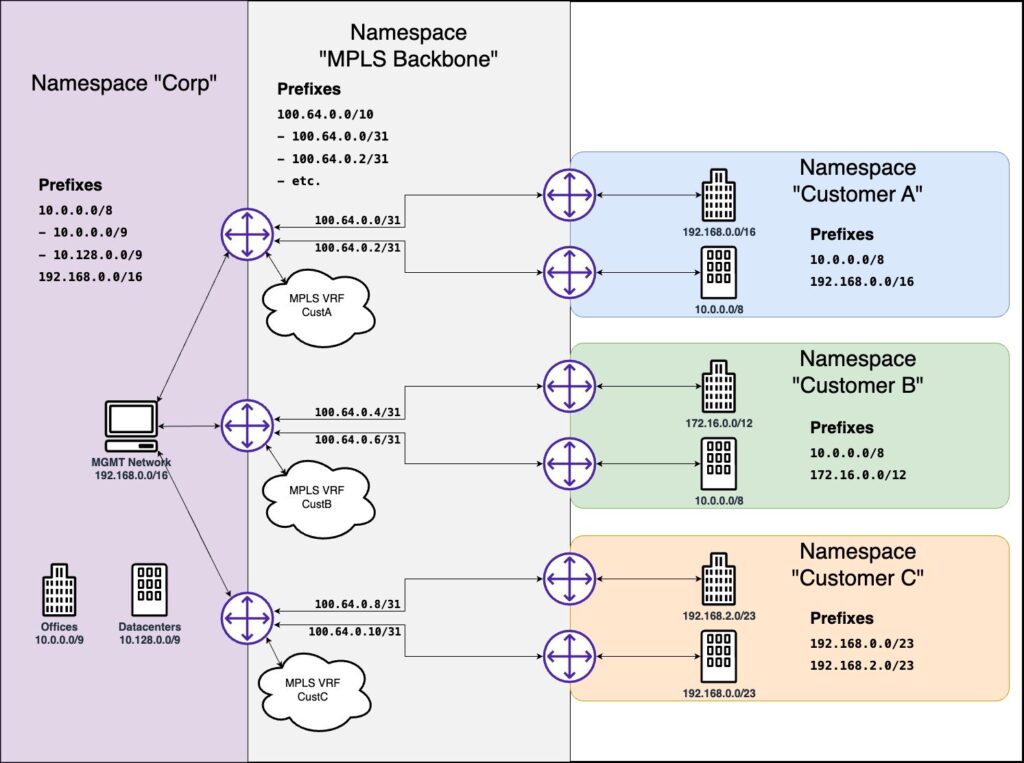
- Namespaces: Namespaces have been introduced to provide unambiguous uniqueness boundaries to the IPAM data model. Prefixes and VRFs are now assigned to Namespaces, which allows for a variety of data tracking use cases, but primarily targets overlapping or duplicate address space needs.
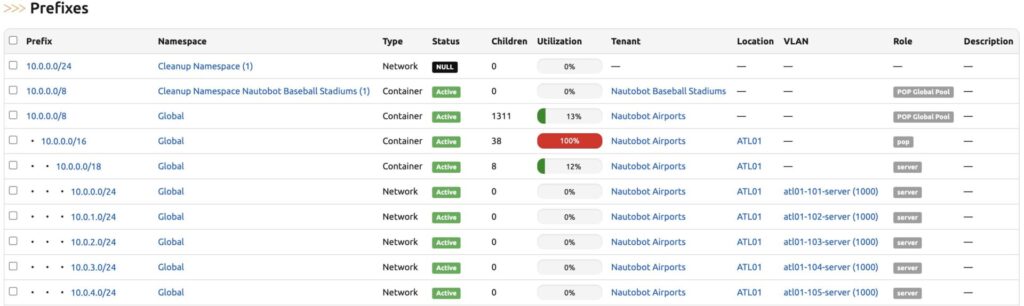
- Prefix and IP Address Relationships: In Nautobot v2, the Prefix and IP Address hierarchy now relies on concrete parent/child relationships. In Nautobot v1, these relationships were calculated dynamically and often led to inconsistent or confusing hierarchies, especially with overlapping address space. This change ensures an always consistent data set and offers several performance improvements in the UI and API.
- IP Address Interface Assignments: Stemming from the other data model changes, IP Addresses can now be assigned to multiple interfaces to more easily track topologies where this is required. In the past, there were special concessions for Anycast needs; but in v2, you can now intuitively deal with other situations like duplicate loopback addresses or cookie-cutter network segment deployments.
Unified Role Model
The new release consolidates existing role models into a singular, streamlined approach, akin to the handling of Statuses. This change simplifies the management of user-defined roles across DCIM, IPAM, and other areas of the network data model. Like Statuses, users now define the roles they want and which models those roles apply to, in one central location.
Location Model Consolidation
Nautobot v2 phases out the Site and Region models, integrating their functionalities into the Location model. This consolidation streamlines data management and reduces complexity. The Location model allows users to define a hierarchy of Location Types that is specific to their organization. Location Types also define what types of objects can be assigned to those parts of the hierarchy, such as Devices or Racks. The consolidated Location model allows for modeling physical, logical, or a mix of both types of entities. Examples might be tracking countries with assets, or defining logical areas in a data center DMZ.

CSV Import/Export
Updates to CSV functionality include consistent headers across different modules and more relevant data for managing relationships, making data import/export tasks more intuitive and efficient. Nautobot v2.1 will move export operations (CSV and Export Templates) to a system-provided background Job, which will mean users can export large data sets without worry that the operation might timeout.
REST API Improvements
- Depth Control: This provides enhanced control over query depth in the REST API, which allows API consumers to specify the amount of data and context they need in a given request. This replaces the
?briefquery parameter in the API. - Version Defaults: New Nautobot v2 installs will now default to the latest version of the REST API, which means consumers can always take advantage of new features by default. Administrators retain the ability to specify a specific version, where required.
Application Development APIs
- Code Namespace Consolidation: The apps code namespace has been reorganized for better clarity and manageability. Most app development dependencies can now be imported from the
nautobot.appsmodule. - Code Reorganization: As part of cleaning up the apps namespace, many items related to apps and in the core project have been relocated, but most things app developers need can be found in the
nautobot.appsmodule. - Developer Documentation: We have made several improvements to the overall structure of the developer documentation and will continue to put significant effort into this area throughout the v2 release train and beyond.
Jobs Updates
- Logging Control: Logging statements in Jobs have changed to offer authors better flexibility and control. Most notably, logging is achieved with the Python standard logging facilities, with special arguments to specify whether the log message should be saved to the JobResult (displayed in the UI) or simply logged to the console.
- Atomic Transaction Changes: In Nautobot v2, Jobs are no longer run inside an atomic transaction context manager. This means authors now have the choice to make their Job atomic or not, by implementing the context manager themselves. A common dry-run interface is provided, but it is up to the author to implement support, much like Ansible modules.
- State Management: Similar to the atomic transaction changes, Job authors now have full control over the state of job executions. This means authors are now responsible for explicitly failing a Job, based on their desired logic.
- File Output and Downloads: Nautobot v2.1 will introduce the capability to generate and output files from Jobs and allow users to download those files in the JobResult’s UI. This capability, built to support the export functionality explained earlier, will be offered to Job authors as an official API.
Revamped User Interface
Nautobot v2.1 will see a facelift of the Nautobot web UI to align with a more modern look and feel. We also hope you will enjoy the navigation moving to a sidebar.
Looking Beyond 2.0
While we have touched on a few important features in the upcoming v2.1 release, the entire v2 release train will remain focused on several network data model enhancements and exciting new automation features. Some of the things we have planned include:
- More device metadata like software and hardware family
- Cloud Networking models
- Device modules
- Breakout cables
- External Integrations configuration management
- Jobs workflows
Conclusion
We hope you are as excited as we are about the future of Nautobot and invite you to try it out in our demo environments. demo.nautobot.com is the current stable release (v2.0, as of this publication) and next.demo.nautobot.com is the next release we are working on (v2.1, as of this publication).
-John Anderson (@lampwins)
Tags :
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!