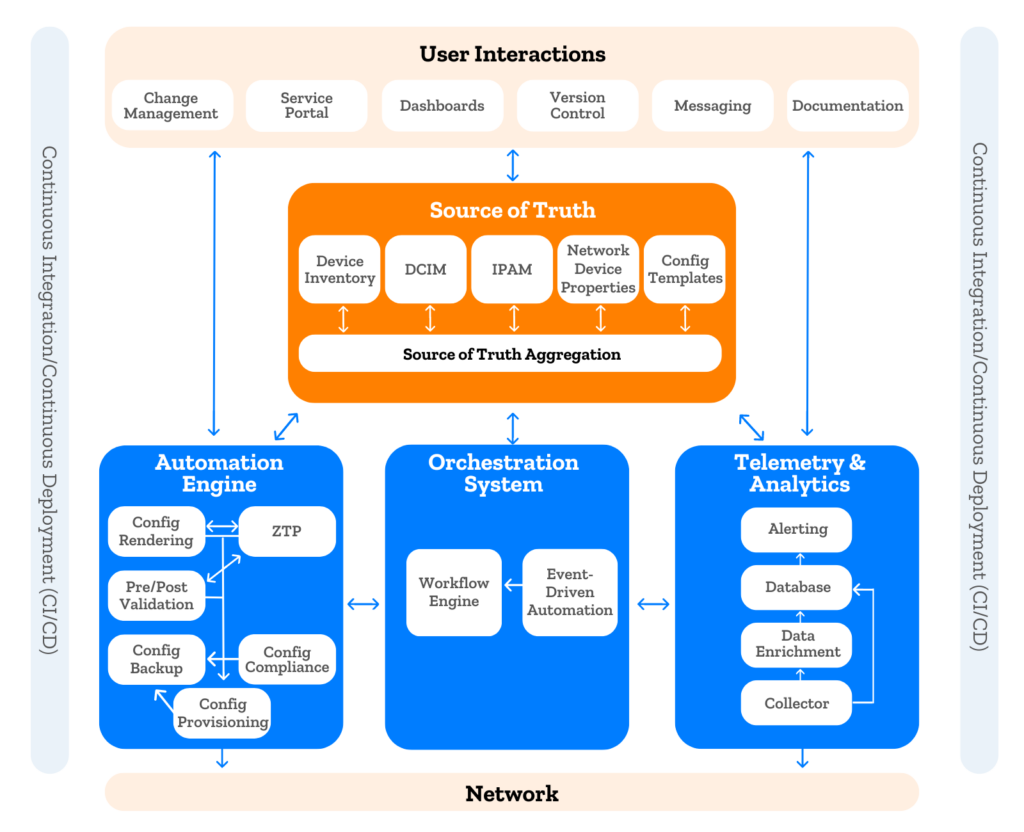
This is Part 3 of the series on Django QuerySet annotations. In Part 1 we talked about what the annotations are and why you would want to use them. In Part 2 we looked at subqueries and more annotation examples.
In this post, we’ll learn how to use annotations spanning multiple tables, and we will go through more advanced use cases.
In the first part of this series we looked at examples of using Count aggregator with annotations to count the number of related objects. We took advantage of reverse relationships1 created by Django and used value of the related_name argument for accessing related objects.
However, not all related objects have a reverse relationship. When a model is defined, it’s possible to explicitly disable the reverse relationship by using the value + (plus sign) for the related_name. Or perhaps our models are indirectly related, i.e., there is no ForeignKey pointing directly from one model to another.
In these cases we have to use subqueries2 in our annotations to process related objects. The resulting queries tend to be a bit more complex; but once you get the hang of it, it all starts to make sense.
Let’s go back to the example where we counted number of circuits for each provider. We’ll try to build an equivalent query that doesn’t use the explicit relationship but uses a subquery instead. This subquery will leverage the fact that the Circuit model has ForeignKey pointing to the Provider model.
This is the query we used previously:
from django.db.models import Count
providers = Provider.objects.annotate(circuit_count=Count("circuits"))
Let’s modify it. First, we build the skeleton of the outer query:
from django.db.models import Subquery, OuterRef
Provider.objects.annotate(circuit_count=Subquery(...))
We keep the same annotation field name but instead of using the Count aggregator we insert a result returned by the subquery.
We now need to focus on building that subquery:
circuits = Circuit.objects \
.filter(provider=OuterRef("pk")) \
.values("provider") \
.order_by() \
.annotate(c=Count("provider")) \
.values("c")
That’s a bit more complex than using Count aggregator, but sometimes this is the only available option.
Before we combine the subquery and the outer query to get our final result, let’s have a closer look at all of the components of the subquerry to make sure we understand what they do.
filter(provider=OuterRef("pk")) — We want only Circuit objects with provider equal to the provider in the outer query. Field pk in OuterRef3 refers to the primary key of the Provider model.values("provider") — Using values clause before annotation will trigger grouping behavior of the annotation as discussed in Part 2 of this series. We will count number of circuits for given provider, so we specify provider field here.order_by() — We clear the default ordering to ensure grouping operation returns correct results.annotate(c=Count("provider")) — Now we apply our annotation with the Count aggregator. New field, named c, will hold number of circuits for each provider group. We applied filtering at the beginning, so there will be only one such group.values("c") — Finally, we specify that only one column is returned, which is the column added by the annotation.
Our subquery must return only one row and one column so that it can be used in the subsequent annotation. This is why we had to use values("c"); otherwise two columns would be returned, and we would get an error.
In this particular subquery only one row will be returned because of the filtering we applied. That won’t always be the case, so we will talk later about how to explicitly force subquery to return one row only.
We built the subquery and talked through how it works. We now need to use it in the main query to get circuit count for each of the providers:
providers = Provider.objects \
.annotate(circuit_count=Subquery(circuits)) \
.values("name", "circuit_count")
That’s it. This should have done the job. Let’s investigate the resulting values:
>>> pprint(list(providers))
[{'circuit_count': None, 'name': 'AT&T'},
{'circuit_count': None, 'name': 'Cogent'},
{'circuit_count': None, 'name': 'Deutsche Telekom'},
{'circuit_count': None, 'name': 'GTT'},
{'circuit_count': None, 'name': 'Liberty Global'},
{'circuit_count': None, 'name': 'Lumen Technologies'},
{'circuit_count': 40, 'name': 'NTT'},
{'circuit_count': None, 'name': 'Orange'},
{'circuit_count': None, 'name': 'PCCW Global'},
{'circuit_count': None, 'name': 'Sprint'},
{'circuit_count': None, 'name': 'Tata Communications'},
{'circuit_count': None, 'name': 'Telecom Italia'},
{'circuit_count': 40, 'name': 'Telia Carrier'},
{'circuit_count': None, 'name': 'Telxius'},
{'circuit_count': None, 'name': 'Verizon'},
{'circuit_count': None, 'name': 'Zayo'}]
Something is not quite right here. Why is None showing up for some of the providers? When we used Count with reverse relationships, the value 0 was shown for the providers that don’t have circuits.
We get None here because when the subquery doesn’t return any results for given provider, a value of None will be used when annotating the Provider objects.
Fortunately, Django provides a function that can help us fix this. We’ll look at it now.
Coalesce Function
We saw that when subquery does not return anything, the value assigned to the annotation field is None. This is generally not what we want. If subquery doesn’t return anything, we would like to define a default value that is assigned to a field instead.
It so happens that Django provides a function that does exactly that. It’s a function named Coalesce4. Imagine it working like a dictionary get() method in Python, with default return value provided.
Coalesce accepts a list of at least two field names or expressions and returns the first non-null value. This means we could use multiple subqueries and wrap them in the Coalesce function. The first non-empty result from the ones returned by subqueries will be used. The caveat here is that the arguments must be of similar type. You can’t mix numbers with text, for example.
So now we know we have to use Coalesce function to fix our query. Let’s go ahead and feed it the subquery we created and an integer 0, which will be our default value.
from django.db.models.functions import Coalesce
providers = Provider.objects \
.annotate(
circuit_count=Coalesce(Subquery(circuits), 0)
) \
.values("name", "circuit_count")
Let’s investigate the resulting values:
>>> pprint(list(providers))
[{'circuit_count': 0, 'name': 'AT&T'},
{'circuit_count': 0, 'name': 'Cogent'},
{'circuit_count': 0, 'name': 'Deutsche Telekom'},
{'circuit_count': 0, 'name': 'GTT'},
{'circuit_count': 0, 'name': 'Liberty Global'},
{'circuit_count': 0, 'name': 'Lumen Technologies'},
{'circuit_count': 40, 'name': 'NTT'},
{'circuit_count': 0, 'name': 'Orange'},
{'circuit_count': 0, 'name': 'PCCW Global'},
{'circuit_count': 0, 'name': 'Sprint'},
{'circuit_count': 0, 'name': 'Tata Communications'},
{'circuit_count': 0, 'name': 'Telecom Italia'},
{'circuit_count': 40, 'name': 'Telia Carrier'},
{'circuit_count': 0, 'name': 'Telxius'},
{'circuit_count': 0, 'name': 'Verizon'},
{'circuit_count': 0, 'name': 'Zayo'}]
Great! We fixed our problem, and now providers that don’t have any circuits have the value of the field circuit_count set to 0.
Limiting Subquery Results to One Column and One Row
As I mentioned in the previous example, a subquery will often return more than one row and column, which cannot be used in some annotations.
Consider the below example of annotating Location objects with the name of the most recently added device within each location:
recently_added = Device.objects \
.filter(location=OuterRef("pk")) \
.order_by("-last_updated") \
.values("name")
locations = Location.objects \
.annotate(newest_device=Subquery(recently_added))
>>> print(locations)
Traceback (most recent call last):
File "<console>", line 1, in <module>
... (cut for brevity)
django.db.utils.ProgrammingError: more than one row returned by a subquery used as an expression
We defined subquery recently_added, which returns devices located in a given location, ordered by the date they were last updated.
When we try to use this subquery in an annotation, we get an error. Django helpfully tells us that subquery returned too many rows. This happens because there could be multiple devices located in any given location, and each row contains device record.
To fix this, we use one element slice [:1] on the QuerySet returned by the subquery. Subquery expects to receive a QuerySet that produces one row, which is why we are using a slice. Note that we cannot use [0] index or first() function here, as these return a single instance of an object, or a dictionary when used with values.
recently_added = Device.objects \
.filter(location=OuterRef("pk")) \
.order_by("-last_updated") \
.values("name")[:1]
locations = Location.objects \
.annotate(newest_device=Subquery(recently_added)) \
.values("name", "newest_device")
>>> pprint(list(locations))
[{'name': 'Jersey City', 'newest_device': 'jcy-spine-02.infra.ntc.com'},
{'name': 'New York City', 'newest_device': 'nyc-spine-02.infra.ntc.com'},
{'name': 'ams', 'newest_device': 'ams-leaf-08'},
{'name': 'atl', 'newest_device': 'atl-leaf-08'},
{'name': 'bkk', 'newest_device': 'bkk-leaf-08'},
{'name': 'can', 'newest_device': 'can-leaf-08'},
{'name': 'cdg', 'newest_device': 'cdg-leaf-08'},
{'name': 'del', 'newest_device': 'del-leaf-10'},
{'name': 'den', 'newest_device': 'den-leaf-08'},
{'name': 'dfw', 'newest_device': 'dfw-leaf-08'},
{'name': 'dxb', 'newest_device': 'dxb-leaf-08'},
{'name': 'fra', 'newest_device': 'fra-leaf-08'},
{'name': 'hkg', 'newest_device': 'hkg-leaf-08'},
{'name': 'hnd', 'newest_device': 'hnd-leaf-08'},
{'name': 'icn', 'newest_device': 'icn-leaf-04'},
{'name': 'jfk', 'newest_device': 'jfk-leaf-08'},
{'name': 'lax', 'newest_device': 'lax-leaf-10'},
{'name': 'lhr', 'newest_device': 'lhr-leaf-08'},
{'name': 'ord', 'newest_device': 'ord-leaf-08'},
{'name': 'pek', 'newest_device': 'pek-leaf-08'},
{'name': 'pvg', 'newest_device': 'pvg-leaf-04'},
{'name': 'sin', 'newest_device': 'sin-leaf-08'}]
And there you have it — our annotation is now working as expected.
Annotations Across Many Tables
A word of warning when using annotations across more than two tables: Due to the way Django translates queries with annotations to underlying SQL, using aggregator functions like Count or Avg across multiple tables will give incorrect results.
For instance, if we try annotating Location records with the count of related prefixes and the count of related devices, we get incorrect numbers:
>>> locations = Location.objects.annotate(pfx_count=Count("prefixes"))
>>> locations.get(name="lax").pfx_count
5
>>> locations = Location.objects.annotate(device_count=Count("devices"))
>>> locations.get(name="lax").device_count
12
>>> locations = Location.objects.annotate(pfx_count=Count("prefixes"), device_count=Count("devices"))
>>> locations.get(name="lax").device_count
60
>>> locations.get(name="lax").pfx_count
60
As you can see above, when using a single annotation with Count, we get correct results. But when we try to annotate Location objects with related Prefix and Device objects in a single query, we get back an incorrect value for both fields5.
Note that the in the case of Count, we can address this problem by providing argument distinct=True when invoking Count. However, this will not work for other aggregation functions.
>>> locations = Location.objects \
.annotate(
pfx_count=Count("prefixes", distinct=True),
device_count=Count("devices", distinct=True)
)
>>> locations.get(name="lax").device_count
12
>>> locations.get(name="lax").pfx_count
5
We will see how we can solve this problem for the generic case by using our trusty subqueries. In the example below, each of the subqueries will be run independently behind the scenes, and the results of each will be assigned to the given field.
from django.db.models import Subquery, OuterRef
pfx_count_sq = Location.objects \
.filter(pk=OuterRef("pk")) \
.annotate(c=Count("prefixes")) \
.values("c")
device_count_sq = Location.objects \
.filter(pk=OuterRef("pk")) \
.annotate(c=Count("devices")) \
.values("c")
locations = Location.objects \
.annotate(
pfx_count=Subquery(pfx_count_sq), \
device_count=Subquery(device_count_sq) \
)
>>> locations.get(name="lax").pfx_count
5
>>> locations.get(name="lax").device_count
12
First, we defined two subqueries, pfx_count_sq and device_count_sq. These could be included directly inside of the annotate() method but defining them separately makes the code easier to read.
In each of the subqueries, we used OuterRef class, which allows us to use the pk field from the outer Location object when Subquery is run.
Each subquery uses annotation with a Count aggregator. We use values("c") here to return just one column c, otherwise we could not use the result of the subquery in the outer query annotation.
You also need to ensure only one row is returned. In our case, we are guaranteed to have only one match. If your subquery returns more than one row, you’d have to use slice [:1] to get back only one item.
Lastly, we wrap subqueries in SubQuery class and plug them into the annotate() method in the main query to get the final result.
As you can see, the resulting values now match the numbers we got when using two separate Count annotations.
Note that using Count and other Django aggregation functions is usually more performant than using subqueries because of the underlying database optimizations. However, subqueries are generally preferable to expressing the equivalent logic in Python code. In case of complex subqueries, you should profile underlying database queries to ensure their performance is acceptable.
More Examples
We’ll now have a look at some more examples of annotations, using different Django functions.
Using Length Function
Let’s compute the length of each of the device names and sort the results in descending order.
from django.db.models import F
from django.db.models.functions import Length
devices = Device.objects \
.annotate(name_len=Length(F("name"))) \
.order_by("-name_len")
>>> pprint(list(devices)[:20])
[<Device: jcy-spine-02.infra.ntc.com>,
<Device: nyc-spine-01.infra.ntc.com>,
<Device: jcy-spine-01.infra.ntc.com>,
<Device: nyc-spine-02.infra.ntc.com>,
<Device: nyc-leaf-02.infra.ntc.com>,
<Device: nyc-leaf-01.infra.ntc.com>,
<Device: jcy-rtr-01.infra.ntc.com>,
<Device: nyc-rtr-01.infra.ntc.com>,
<Device: jcy-rtr-02.infra.ntc.com>,
<Device: nyc-rtr-02.infra.ntc.com>,
<Device: jcy-bb-01.infra.ntc.com>,
<Device: nyc-bb-01.infra.ntc.com>,
<Device: den-leaf-02>,
<Device: dfw-leaf-05>,
<Device: dxb-leaf-02>,
<Device: dxb-leaf-05>,
<Device: fra-leaf-04>,
<Device: fra-leaf-08>,
<Device: hkg-edge-01>,
<Device: hkg-leaf-06>]
We made use of Length6 function and F7 object. F object is used to pass value of the device’s name field to the Length function. Length function will return number of characters in the passed argument.
Filtering Values of the Annotation Field
In the below example, we use Count in the annotation. Then, we filter the values in the annotation field vlans_count to get back only locations that have at least one VLAN assigned to them.
locations = Location.objects \
.annotate(vlans_count=Count("vlans")) \
.filter(vlans_count__gt=1) \
.values("name", "vlans_count")
>>> pprint(list(locations))
[{'name': 'ams', 'vlans_count': 16},
{'name': 'atl', 'vlans_count': 16},
{'name': 'bkk', 'vlans_count': 16},
{'name': 'can', 'vlans_count': 16},
{'name': 'cdg', 'vlans_count': 16},
{'name': 'del', 'vlans_count': 20},
{'name': 'den', 'vlans_count': 16},
{'name': 'dfw', 'vlans_count': 16},
{'name': 'dxb', 'vlans_count': 16},
{'name': 'fra', 'vlans_count': 16},
{'name': 'hkg', 'vlans_count': 16},
{'name': 'hnd', 'vlans_count': 16},
{'name': 'icn', 'vlans_count': 8},
{'name': 'jfk', 'vlans_count': 16},
{'name': 'lax', 'vlans_count': 20},
{'name': 'lhr', 'vlans_count': 16},
{'name': 'ord', 'vlans_count': 16},
{'name': 'pek', 'vlans_count': 16},
{'name': 'pvg', 'vlans_count': 8},
{'name': 'sin', 'vlans_count': 16}]
Using Exists Subquery
We can use Exists8 subquery subclass to get back a boolean True if subquery returns results or False if it doesn’t. For instance, we might want to check whether a given location has devices that are assigned edge role.
from django.db.models import Exists, OuterRef
edge_dev_sq = Subquery(
Device.objects \
.filter(
location=OuterRef("pk"),
device_role__slug="edge"
)
)
locs_w_edge_dev = Location.objects \
.annotate(has_edge_devices=Exists(edge_dev_sq)) \
.values("name", "has_edge_devices")
>>> pprint(list(locs_w_edge_dev))
[{'has_edge_devices': False, 'name': 'Jersey City'},
{'has_edge_devices': False, 'name': 'New York City'},
{'has_edge_devices': True, 'name': 'ams'},
{'has_edge_devices': True, 'name': 'atl'},
{'has_edge_devices': True, 'name': 'bkk'},
{'has_edge_devices': True, 'name': 'can'},
{'has_edge_devices': True, 'name': 'cdg'},
{'has_edge_devices': True, 'name': 'del'},
{'has_edge_devices': True, 'name': 'den'},
{'has_edge_devices': True, 'name': 'dfw'},
{'has_edge_devices': True, 'name': 'dxb'},
{'has_edge_devices': True, 'name': 'fra'},
{'has_edge_devices': True, 'name': 'hkg'},
{'has_edge_devices': True, 'name': 'hnd'},
{'has_edge_devices': True, 'name': 'icn'},
{'has_edge_devices': True, 'name': 'jfk'},
{'has_edge_devices': True, 'name': 'lax'},
{'has_edge_devices': True, 'name': 'lhr'},
{'has_edge_devices': True, 'name': 'ord'},
{'has_edge_devices': True, 'name': 'pek'},
{'has_edge_devices': True, 'name': 'pvg'},
{'has_edge_devices': True, 'name': 'sin'}]
Using Python Expressions in Annotations
You can also use Python expressions in your annotations. We’ve seen an example of that in Part 2, where we computed percentage of free interfaces on devices. Here is an example that shows how to annotate Device objects with the time elapsed since the object was created.
import datetime
today = datetime.date.today()
devices = Device.objects \
.annotate(
created_delta=today - F("created")
)
>>> devices[0].created_delta
datetime.timedelta(days=47)
>>> devices[0].created_delta.days
47
We use datetime.datetime.date.today() to get today’s date. Then, we use this value in the annotation to subtract the date the object was created from today’s date. The result is a datetime.timedelta object, which we can query for the number of days since the device was created.
Count distinct Argument
In our final example we will use Count’s distinct argument to compute number of distinct device roles used by devices in each location.
When we use distinct=True, we’re telling Count to compute number of unique values for the given argument. Here, we’re giving it devices__device_role, which will access device role for the devices in each of the locations.
locations = Location.objects \
.annotate(
devrole_count=Count(
"devices__device_role", distinct=True
)
) \
.values("name", "devrole_count")
>>> pprint(list(locations))
[{'devrole_count': 3, 'name': 'Jersey City'},
{'devrole_count': 4, 'name': 'New York City'},
{'devrole_count': 2, 'name': 'ams'},
{'devrole_count': 2, 'name': 'atl'},
{'devrole_count': 2, 'name': 'bkk'},
{'devrole_count': 2, 'name': 'can'},
{'devrole_count': 2, 'name': 'cdg'},
{'devrole_count': 2, 'name': 'del'},
{'devrole_count': 2, 'name': 'den'},
{'devrole_count': 2, 'name': 'dfw'},
{'devrole_count': 2, 'name': 'dxb'},
{'devrole_count': 2, 'name': 'fra'},
{'devrole_count': 2, 'name': 'hkg'},
{'devrole_count': 2, 'name': 'hnd'},
{'devrole_count': 2, 'name': 'icn'},
{'devrole_count': 2, 'name': 'jfk'},
{'devrole_count': 2, 'name': 'lax'},
{'devrole_count': 2, 'name': 'lhr'},
{'devrole_count': 2, 'name': 'ord'},
{'devrole_count': 2, 'name': 'pek'},
{'devrole_count': 2, 'name': 'pvg'},
{'devrole_count': 2, 'name': 'sin'}]
References
- Django docs – Related objects reference ↩
- Django docs – Query Expressions –
SubQuery ↩
- Django docs – Query Expressions –
OuterRef ↩
- Django docs – Database Functions –
Coalesce ↩
- Django docs – Aggregation – Combining multiple aggregations ↩
- Django docs – Database Functions –
Length ↩
- Django docs – Query Expressions –
F ↩
- Django docs – Query Expressions –
Exists ↩