
Blog Detail


Ansible’s variable management system is fairly extensible, however the cost of that extensibility and associated design choices can cause some inefficiencies when interacting with external systems. Specifically, it can become rather time consuming to get all of the data a playbook requires at run time. Leveraging Nautobot’s GraphQL and Nautobot Ansible collection, we will explore what an optimal solution would be.
A Quick Lesson in Ansible Inventory
Initially Ansible had created an Ansible Dynamic Inventory, which was a script that would print to the terminal a JSON serializable structure in a specific format. Once Ansible 2.4 was released, there was support for Ansible Inventory Plugins, which provide a more object-oriented and Pythonic experience, as well as a separation of the configuration (generally via YAML files) from the inventory itself.
With both of these dynamic inventory types as well as any static inventory, the inventory must be compiled before the play runs. This means that all inventory and variables are collected before a playbook is run. If your playbook requires a connection to only a single device and needs a single configuration parameter, this would still require the entire inventory and variables to compile, which is the same as if the playbook had to connect to thousands of devices for dozens of variables each.
This design certainly has its advantages, such as Ansible’s use of the hostvars (not to be confused with host_vars) magic variable. Meaning, even if you need to connect to a only single device, you can still have access to another device’s variable. This would allow you to do something like:
- name: "SET SPINE_INTERFACE BY LOOKING INTO THE SPINES VARIABLE STRUCTURE"
set_fact:
spine_interface: "{{ hostvars[inventory_hostname[:5] ~ 'spine01']['interface_mappings'][inventory_hostname] }}"
However, such a requirement is not often needed, and it is perfectly valid to provide an alternative solution without such a feature, as we will explore.
The Speed Issue
It is obvious that the standard design causes a host of speed issues when not all variables are required. Within Nautobot, to collect all of the interfaces and config context of thousands of devices could literally take hours. This is because the queuing mechanism looks something like:
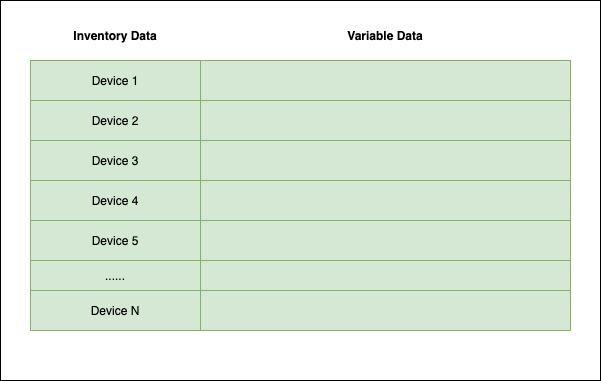
In this example, it could potentially take hundreds or even thousands of API calls before the first task runs, and all of that data needs to be stored in memory. This is true even if the only data we require actually looks like:
GraphQL to the Rescue
Recognizing the speed issues, at Network to Code we have worked with our customers for years on various work-arounds, which was one of the drivers to introducing GraphQL to Nautobot. What we have observed from dozens of engagements with our customers is:
- Playbooks rarely need access to all data
- There is generally a single “generate configuration” playbook that does need access to all data
- There are usually different ways data may need to be requested
- Managing separate inventories is complicated and leads to issues
- The primary issue is the way in which data is queued, with Ansible expecting all data to be queued beforehand
With that in mind, we looked to change the way that variables are populated; this is different from saying we looked to change how the inventory plugin works. The basic premise is to get the bare minimum inventory from the inventory plugin, then populate the data within the play itself. The direct benefit is that inventory does not require nearly the amount of data (which must be present before any task in the play is run) before starting. And we have also distributed the amount of data to be smaller API calls made while the play is running. Additionally, if we do not need all data, we simply do not need to get that data at all.
It is in that second step that GraphQL really shines. GraphQL provides a single API that can be called to send only the data that is required. There is a lookup and an Ansible module within Nautobot’s Ansible Collection. This means that we can use a single inventory setup for all of our playbooks and have specific tasks to get the data required for specific playbooks. We can also change the majority of the API calls to happen per device rather than all up front. This has a significant performance impact, as bombarding the server with hundreds or thousands of API calls at once can cause performance issues—not only for the user of Ansible, but potentially deteriorating the performance of the server for everyone else.

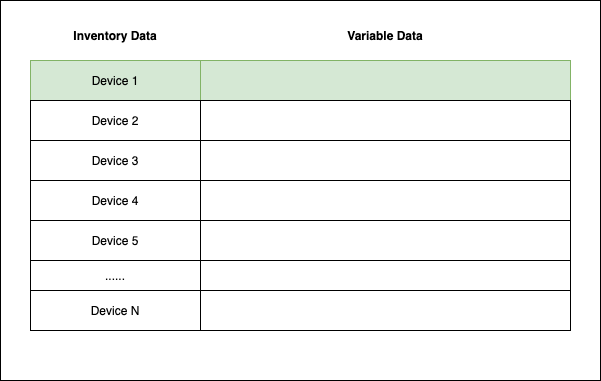
Even when you do require all of the data, it looks more like this (where time is left-to-right and scaled to your actual needs):

Note: The depicted batch size is equal to the fork size you have chosen. There are also alternative Ansible
strategiesone can explore outside the scope of this blog.
Note: The API calls shown are not meant to represent the actual amount a production instance may have, but merely to illustrate the point.
Example Playbook and Inventory
So let’s take a look at what such a playbook and inventory may look like.
plugin: networktocode.nautobot.inventory
api_endpoint: "https://demo.nautobot.com"
validate_certs: False
config_context: False
plurals: False
interfaces: False
services: False
racks: False
rack_groups: False
compose:
device_id: id
group_by:
- site
- tenant
- tag
- role
- device_type
- manufacturer
- platform
- region
- status
A playbook to obtain and populate the data could look like:
---
- name: "TEST NAUTOBOT INVENTORY"
connection: "local"
hosts: "all"
gather_facts: "no"
tasks:
- name: "SET FACT FOR QUERY"
set_fact:
query_string: |
query ($device_id: ID!) {
device(id: $device_id) {
config_context
hostname: name
position
serial
primary_ip4 {
id
primary_ip4_for {
id
name
}
}
tenant {
name
}
tags {
name
slug
}
device_role {
name
}
platform {
name
slug
manufacturer {
name
}
napalm_driver
}
site {
name
slug
vlans {
id
name
vid
}
vlan_groups {
id
}
}
interfaces {
description
mac_address
enabled
name
ip_addresses {
address
tags {
id
}
}
connected_circuit_termination {
circuit {
cid
commit_rate
provider {
name
}
}
}
tagged_vlans {
id
}
untagged_vlan {
id
}
cable {
termination_a_type
status {
name
}
color
}
tagged_vlans {
site {
name
}
id
}
tags {
id
}
}
}
}
- name: "GET DEVICE INFO FROM GRAPHQL"
networktocode.nautobot.query_graphql:
url: "{{ nautobot_url }}"
token: "{{ nautobot_token }}"
validate_certs: False
query: "{{ query_string }}"
update_hostvars: "yes"
graph_variables:
device_id: "{{ device_id }}"
The above shows update_hostvars set, which will publish the variables for any playbook task after this point. Within a playbook that starts like the above, you would have access to the data. If the playbook did not have any requirements for the above data, you would simply not include such tasks.
Life without GraphQL
Without GraphQL the same can still be accomplished. In the past at Network to Code, we have used Ansible custom modules. Within the custom module you can populate the ansible_facts key, which will actually update the data associated with a device. So if a custom Ansible module had the below code:
results = {"ansible_facts": {"ntp": ["1.1.1.1", "2.2.2.2"]}}
module.exit_json(**results)
you could have access to the data in the playbook as usual, such as:
- debug: var=ntp
Inventory Recommendations
If you will notice in the example inventory, the inventory is minimal. The basic premise is that you should disable any data not required to create groups and, generally speaking, retain only the minimum amount of information required to connect to the device, such as IP address and network OS.
Conclusion
Changing the queuing mechanism has dramatic effects on the overall speed, and Nautobot’s ecosystem was built to take advantage of these capabilities. But that is not the only way to work this, as you could build a custom module as well. When thinking about performance and scalability of the data, you should consider a lightweight inventory and more detailed data on a task level.
-Ken Celenza
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!
