Blog Detail


Our managed services team is responsible for running and managing applications for our customers. We need to run these applications efficiently and reliably as we work with multiple organizations. While there are many tools available to deploy applications and manage them efficiently, we believe Kubernetes is the right platform for our use case.
So we are deploying all our applications to Kubernetes, and Nautobot is no exception. This blog post is the first one in the series where I will try to explain on a high level how we are managing Nautobot deployments for our customers.
Deploying applications to Kubernetes can be complex, especially for beginners, as every application deployment consists of many Kubernetes objects, such as Deployments, ConfigMaps, Secrets, ServiceAccount, etc. In this first post, I will explain how you can easily use Helm charts to deploy Nautobot using a few commands. We developed Nautobot Helm charts to deploy Nautobot following best practices gathered with experience running Nautobot in production. That is why using Helm charts for deployment is recommended.
I will lead you through the process of bringing up the development Kubernetes cluster using minikube. Then I will explain how to install Helm charts, and finally, I will show you how easily you can deploy Nautobot.
Start minikube Cluster
Deploying a production-ready Kubernetes cluster can be pretty challenging, which usually requires a team to deploy and manage. Luckily we have minikube. It is a development Kubernetes implementation that you can deploy with a single command on your laptop.
To run a minikube cluster, you must first install minikube. minikube installation is outside the scope of this blog post, but it is easy enough to follow the steps on the official minikube webpage.
I already have minikube installed, so I can go ahead and start a cluster. Let’s do that first. I will use the minikube start command to create and start a cluster.
➜ ~ minikube start
😄 minikube v1.22.0 on Darwin 12.5.1
✨ Using the hyperkit driver based on user configuration
👍 Starting control plane node minikube in cluster minikube
🔥 Creating hyperkit VM (CPUs=4, Memory=12000MB, Disk=20000MB) ...
📦 Preparing Kubernetes v1.21.2 on containerd 1.4.4 ...
▪ Generating certificates and keys ...
▪ Booting up control plane ...
▪ Configuring RBAC rules ...
🔗 Configuring bridge CNI (Container Networking Interface) ...
🔎 Verifying Kubernetes components...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🌟 Enabled addons: storage-provisioner, default-storageclass
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by default
I have a local development Kubernetes cluster up and running in a few minutes.
Nautobot Helm Charts
Now that I have the cluster, I can start the process of deploying a Nautobot instance. As I already mentioned, using Nautobot Helm charts is the recommended way to deploy Nautobot to Kubernetes.
Helm charts are a packaging format for Kubernetes, consisting of a collection of files (or templates) for Kubernetes objects. A chart typically accepts a list of input parameters (commonly referred to as values) that are translated to Kubernetes object definitions in a YAML format. These files are then directly deployed to Kubernetes. The advantage of using Helm charts is that charts hide deployment complexity from you. Templates are typically created to deploy an application with minimal input parameters using best practices.
We released 1.0 Nautobot Helm charts back in October 2021. You can read the official announcement in a blog post. We are hosting Nautobot Helm charts in a GitHub repository.
As mentioned, a Helm chart usually accepts many input parameters; some can be mandatory and others optional. There is usually a file called values.yaml containing all available parameters with default values. After the documentation, this file is a good source if you want to explore which parameters are available and what are the default values. Before using Helm charts to deploy Nautobot, it is a good practice to go through some parameters to get more familiar with what is available. For Nautobot Helm charts, you can find the list in the documentation or in the values.yaml.
Deploy Nautobot Helm Charts
Now that I’ve explained the basics, I can show you how to deploy Nautobot quickly using Helm charts.
To use Helm charts, you must install Helm software on your local machine. It is out of the scope of this blog post to show you how to install Helm, but again, it should be fairly easy to install Helm following the official documentation.
Once Helm is installed, the first step is deploying the Nautobot Helm repository. You can do this with the helm repo add command. Let me do that now:
➜ ~ helm repo add nautobot https://nautobot.github.io/helm-charts/
"nautobot" has been added to your repositories
➜ ~ helm repo list
NAME URL
nautobot https://nautobot.github.io/helm-charts/
Each repo contains multiple Helm charts versions. Run the helm search repo command to see the default version.
➜ ~ helm search repo nautobot
NAME CHART VERSION APP VERSION DESCRIPTION
nautobot/nautobot 1.3.12 1.3.5 Nautobot is a Network Source of Truth and Netwo...
The output above shows the name, the chart version, the application version, and the description. The output shows a default version, but you can also see the application version. In this case, the chart version 1.3.12 is bound to the Nautobot version 1.3.5, meaning that deploying the chart version 1.3.12 will deploy the Nautobot version 1.3.5 by default.
You can use the -l option to see all versions available.
➜ ~ helm search repo nautobot -l
NAME CHART VERSION APP VERSION DESCRIPTION
nautobot/nautobot 1.3.12 1.3.5 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.11 1.3.4 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.10 1.3.3 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.9 1.3.2 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.8 1.3.1 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.7 1.2.11 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.6 1.2.10 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.5 1.2.9 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.4 1.2.9 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.3 1.2.8 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.2 1.2.7 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.1 1.2.7 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.3.0 1.2.5 Nautobot is a Network Source of Truth and Netwo...
nautobot/nautobot 1.2.4 1.2.5 Nautobot is a Network Source of Truth and Netwo...
<... Output omitted ...>
So after deploying the Nautobot Helm charts, I can proceed to the next step, deploying Nautobot itself using the newly installed Helm repository.
Deploy Nautobot
As discussed, you can use all sorts of parameters for Nautobot deployment. In this example, I will show you how to deploy Nautobot with minimal parameters. The default settings deploy a small Nautobot deployment, suitable for development or testing. This small deployment consists of two Nautobot instances, one Celery beat instance, two Celery worker instances, a PostgreSQL database, and Redis. The default configuration can be customized to deploy a full production deployment of Nautobot.
As part of the default Nautobot deployment, Helm charts deploy PostgreSQL and Redis instances. Under the hood, this is just a pass-through to Bitnami’s PostgreSQL and Redis Helm charts. Every parameter available for these two charts is also available in the Nautobot Helm charts. Of course, you can omit deploying a PostgreSQL database and Redis instance and deploy them yourself, in which case, you must correctly define DB and Redis parameters to use external instances.
So, let’s get back to the Nautobot deployment. As I already mentioned, input parameters can be mandatory or optional. However, there are two required parameters in Nautobot Helm charts:
- A PostgreSQL password
- A Redis password
Installing Helm charts is done with the helm install command. You can specify input parameters inline with the --set option, or you can create a YAML file containing all your parameters and use the --values option with the path to the YAML file.
In my example, I will specify input parameters inline, but you would usually want to create a file and store parameters there. It is just much easier to change a parameter in a file and rerun the helm command.
But anyway, let’s deploy Nautobot by passing the parameters inline.
➜ ~ helm install nautobot nautobot/nautobot \
--set postgresql.postgresqlPassword=SuperSecret123 \
--set redis.auth.password=SuperSecret456
NAME: nautobot
LAST DEPLOYED: Tue Sep 6 10:34:48 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
*********************************************************************
*** PLEASE BE PATIENT: Nautobot may take a few minutes to install ***
*********************************************************************
1. Get the Nautobot URL:
echo "Nautobot URL: http://127.0.0.1:8080/"
kubectl port-forward --namespace default svc/nautobot 8080:80
2. Get your Nautobot login admin credentials by running:
echo Username: admin
echo Password: $(kubectl get secret --namespace default nautobot-env -o jsonpath="{.data.NAUTOBOT_SUPERUSER_PASSWORD}" | base64 --decode)
echo api-token: $(kubectl get secret --namespace default nautobot-env -o jsonpath="{.data.NAUTOBOT_SUPERUSER_API_TOKEN}" | base64 --decode)
Make sure you take note of your Nautobot `NAUTOBOT_SECRET_KEY` by running:
echo Secret Key: $(kubectl get secret --namespace default nautobot-env -o jsonpath="{.data.NAUTOBOT_SECRET_KEY}" | base64 --decode)
To take a backup of the database run:
export POSTGRES_PASSWORD=$(kubectl get secret --namespace default nautobot-postgresql -o jsonpath="{.data.postgresql-password}" | base64 --decode)
echo $POSTGRES_PASSWORD | kubectl exec -itn default statefulset.apps/nautobot-postgresql -- pg_dump --username nautobot --clean --if-exists nautobot > backup.sql
After I applied the command, I needed to wait for a few minutes before the deployment was ready. After that, I should see all Kubernetes Pods up and running:
➜ ~ kubectl get pods
NAME READY STATUS RESTARTS AGE
nautobot-5648dd987d-8rkcw 1/1 Running 1 5m30s
nautobot-5648dd987d-jz9qf 1/1 Running 1 5m30s
nautobot-celery-beat-ccc96f8c9-ljhzr 1/1 Running 3 5m30s
nautobot-celery-worker-5d6597f5d9-2lf2h 1/1 Running 2 5m30s
nautobot-celery-worker-5d6597f5d9-5bgjz 1/1 Running 2 5m30s
nautobot-postgresql-0 1/1 Running 0 5m30s
nautobot-redis-master-0 1/1 Running 0 5m30s
As you can see, this default configuration deploys two Nautobot instances, a Celery beat instance, two Celery workers, a PostgreSQL instance, and a Redis instance.
I can now test whether I can connect to my deployment. Some basic instructions on how to connect to Nautobot are already provided in the output of the helm install command.
I will first extract the admin password.
➜ ~ echo Password: $(kubectl get secret --namespace default nautobot-env -o jsonpath="{.data.NAUTOBOT_SUPERUSER_PASSWORD}" | base64 --decode)
Password: R@kUT_ZW6l@KAb@k@J8x@6@_K@@@I5PtL@QO7ABu_fa@_@@@gsV7A@f@@s@@@3f@
Now that I have the admin password, I can enable port forwarding. Normally, you would create an ingress that would allow you to connect to your instance using a hostname. But since this is just for the demo purposes, and I don’t have any ingress controller enabled, I will just enable port forwarding and connect to my instance through the tunnel.
➜ ~ kubectl port-forward --namespace default svc/nautobot 8080:80
Forwarding from 127.0.0.1:8080 -> 8080
Forwarding from [::1]:8080 -> 8080
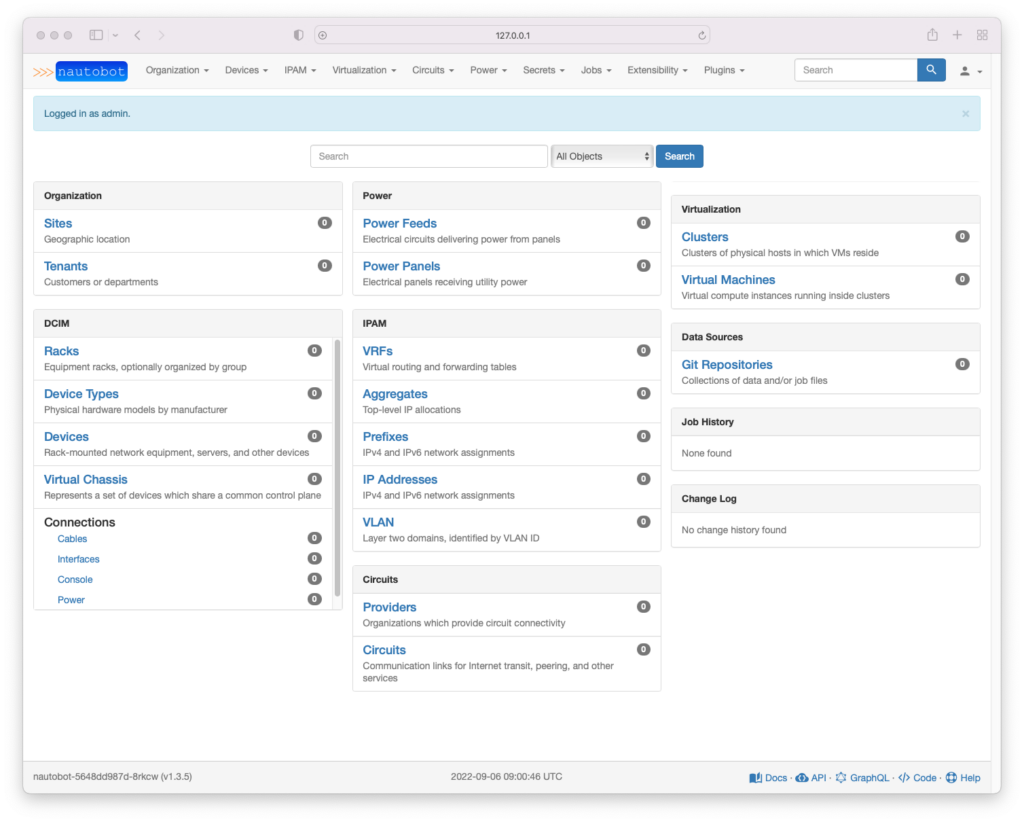
I can now go to my browser and connect to http://127.0.0.1:8080 to access the Nautobot instance. I will use the username admin and the password extracted in the previous step to log in to the instance.
Voila, I can access my Nautobot instance deployed to Kubernetes.
Conclusion
Deploying all required Kubernetes objects can be challenging, especially if you don’t fully understand all components needed for deploying an application. Luckily we have a tool called Helm, which comes with a packaging format called Helm charts. Helm charts can hide much complexity from a developer.
Nautobot Helm charts are actively maintained; so whenever you want to deploy Nautobot to Kubernetes, you should take a quicker route and deploy the application using Helm charts.
~ Uros
Tags :
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!