Blog Detail


In large-scale network automation, memory management can make or break your workflows when dealing with hundreds or thousands of devices. This post dives into how Python generators can help you handle data more efficiently by processing it on-the-fly instead of loading everything into memory. With examples from real-world network automation tasks and tips for identifying and optimizing memory-heavy code, you’ll see how generators can make your automation code more scalable and robust.
The Challenge of Memory Usage in Large-Scale Automation
When prototyping network automation solutions in Python, it’s not uncommon to develop against a small set of devices—only to find that the code doesn’t scale well when used in large production environments. This is often due to the memory overhead of storing large amounts of data in memory, which can lead to performance issues and even crashes. A common approach to fetching data for multiple devices is to use loops or list comprehensions, which can quickly consume memory when dealing with large datasets.
How Python Generators Can Help
Generators in Python are a special type of iterable, similar to a function that returns a list. But instead of returning all the values at once, they yield one value at a time, allowing for lazy evaluation. This means that the values are generated on-the-fly and only when needed, which can be more memory efficient for large environments.
Example of a Typical Network Automation Task
A common use case for network automation is to retrieve data from a remote system, for example a CMDB (Configuration Management Database) or a network SOT (Source of Truth) such as Nautobot. Let’s consider a scenario where we need to fetch device data using Nautobot’s REST API. A traditional approach might involve fetching all the data at once and storing it in a list, like this:
import requests
TEST_API_HEADERS = {
"Accept": "application/json",
"Authorization": "Token aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa",
}
def get_nautobot_devices():
data = requests.get(
"https://demo.nautobot.com/api/dcim/devices",
headers=TEST_API_HEADERS,
timeout=60,
).json()
devices = data["results"]
while data["next"]:
data = requests.get(data["next"], headers=TEST_API_HEADERS, timeout=60).json()
devices.extend(data["results"])
return devices
for device in get_nautobot_devices():
print(device["name"], device["url"])In this example, Nautobot will return a paginated list of devices, and we’re fetching all of the data for all devices and storing it in a list. Here’s a sample of the data that’s returned for just one device:
{
"id": "89b2ac3b-1853-4eeb-9ea6-6a081999bd3c",
"object_type": "dcim.device",
"display": "ams01-dist-01",
"url": "https://demo.nautobot.com/api/dcim/devices/89b2ac3b-1853-4eeb-9ea6-6a081999bd3c/",
"natural_slug": "ams01-dist-01_nautobot-airports_ams01_netherlands_europe_89b2",
"face": null,
"local_config_context_data": null,
"local_config_context_data_owner_object_id": null,
"name": "ams01-dist-01",
"serial": "",
"asset_tag": null,
"position": null,
"device_redundancy_group_priority": null,
"vc_position": null,
"vc_priority": null,
"comments": "",
"local_config_context_schema": null,
"local_config_context_data_owner_content_type": null,
"device_type": {
"id": "4bf23e23-4eb1-4fae-961c-edd6f8cbaaf1",
"object_type": "dcim.devicetype",
"url": "https://demo.nautobot.com/api/dcim/device-types/4bf23e23-4eb1-4fae-961c-edd6f8cbaaf1/"
},
"status": {
"id": "9f38bab4-4b47-4e77-b50c-fda62817b2db",
"object_type": "extras.status",
"url": "https://demo.nautobot.com/api/extras/statuses/9f38bab4-4b47-4e77-b50c-fda62817b2db/"
},
"role": {
"id": "40567487-6328-4dac-b7b5-b789d1154bf0",
"object_type": "extras.role",
"url": "https://demo.nautobot.com/api/extras/roles/40567487-6328-4dac-b7b5-b789d1154bf0/"
},
"tenant": {
"id": "1f7fbd07-111a-4091-81d0-f34db26d961d",
"object_type": "tenancy.tenant",
"url": "https://demo.nautobot.com/api/tenancy/tenants/1f7fbd07-111a-4091-81d0-f34db26d961d/"
},
"platform": {
"id": "aa07ca99-b973-4870-9b44-e1ea48c23cc9",
"object_type": "dcim.platform",
"url": "https://demo.nautobot.com/api/dcim/platforms/aa07ca99-b973-4870-9b44-e1ea48c23cc9/"
},
"location": {
"id": "9e39051b-e968-4016-b0cf-63a5607375de",
"object_type": "dcim.location",
"url": "https://demo.nautobot.com/api/dcim/locations/9e39051b-e968-4016-b0cf-63a5607375de/"
},
"rack": null,
"primary_ip4": null,
"primary_ip6": null,
"cluster": null,
"virtual_chassis": null,
"device_redundancy_group": null,
"software_version": null,
"secrets_group": null,
"controller_managed_device_group": null,
"software_image_files": [],
"created": "2023-09-21T00:00:00Z",
"last_updated": "2024-09-24T15:20:12.443339Z",
"notes_url": "https://demo.nautobot.com/api/dcim/devices/89b2ac3b-1853-4eeb-9ea6-6a081999bd3c/notes/",
"custom_fields": {
"demo_custom_field": null
},
"tags": [],
"parent_bay": null
}If we only needed to retrieve the name and URL for each device, we could modify the get_nautobot_devices function to discard all of the other data. But then we wouldn’t be able to reuse this function for other use cases where we might need a different set of fields. This is a perfect opportunity to convert get_nautobot_devices into a generator.
Example: Scalable Network Data Collection
To turn our example get_nautobot_devices function into a generator, we can simply remove the return statement and add yield statements instead. This will allow us to iterate over the devices one chunk at a time, without storing all of the data in memory at once. Note that since we are yielding from another iterable (a list of “results” in this case), we must use the yield from statement. The yield from statement tells Python to yield all of the values in the provided iterable one by one. In this case, the Nautobot API is returning pages of 50 devices at a time so we are storing the data for at most 50 devices in memory at once. The chunk size may need to be adjusted based on individual use cases.
def get_nautobot_devices():
data = requests.get(
"https://demo.nautobot.com/api/dcim/devices",
headers=TEST_API_HEADERS,
timeout=60,
).json()
yield from data["results"] # <-- Yield the first set of devices
while data["next"]:
data = requests.get(data["next"], headers=TEST_API_HEADERS, timeout=60).json()
yield from data["results"] # <-- Yield the next set of devices
for device in get_nautobot_devices():
print(device["name"], device["url"])Comparison
This example was tested against a Nautobot instance with 900 devices. The function that compiled a list of all devices consumed around 5MB of memory, while the generator consumed only 1MB. The generator will generally use the same amount of memory regardless of the number of devices, while the memory consumption of the list will increase linearly with the number of devices.
Code Execution Diagrams
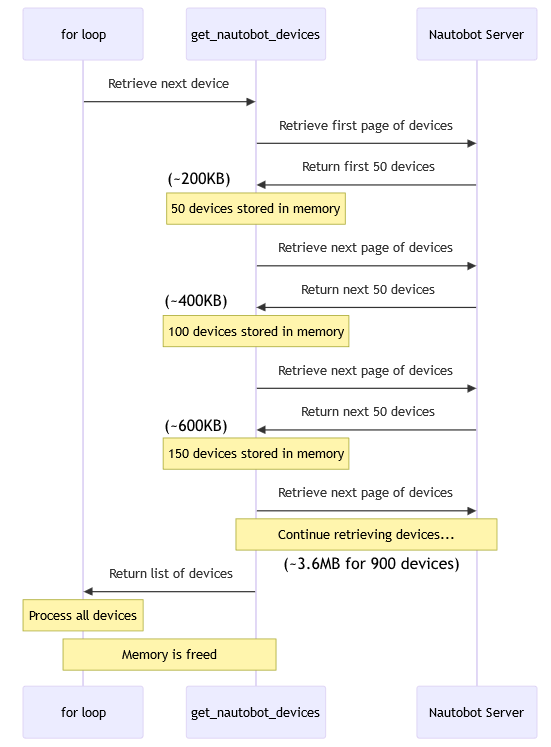
This first diagram illustrates how a “for loop” interacts with the function that returns a list. The list is created once and then the “for loop” iterates over the devices one at a time, fetching the next device from the list each time. You can see how this example has to compile the entire list of devices before the loop can start iterating over them.
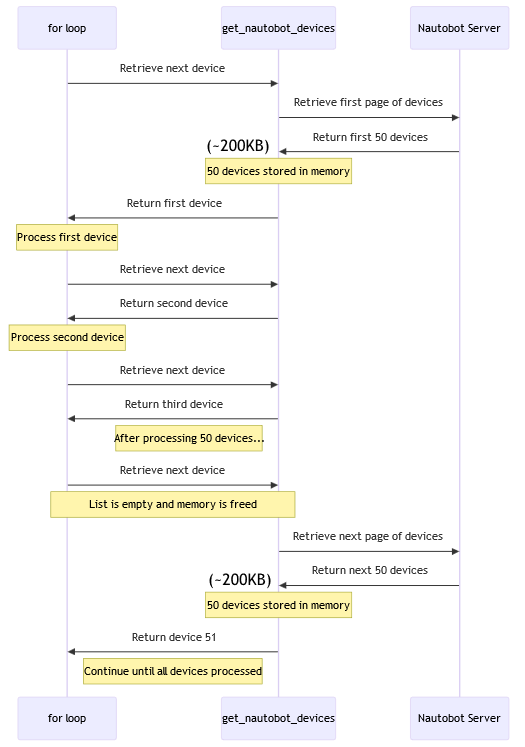
The next diagram illustrates how the loop interacts with the generator. The code switches back and forth between the generator and the “for loop” as it iterates over the devices.
Conclusion
In large-scale network automation, memory management is crucial to maintaining performance and avoiding system crashes. By leveraging Python generators, we can significantly reduce memory consumption when dealing with large datasets, making our automation code more scalable and efficient. The example with Nautobot’s REST API clearly illustrates how generators yield memory savings by fetching data lazily, one page at a time, instead of storing everything in memory.
Identifying Memory-Heavy Code
Before optimizing with generators, it’s important to identify areas of the code that may be causing memory issues. A good starting point is to look for large data structures that are fully loaded into memory, such as lists or dictionaries, especially in loops or recursive calls.
You can use tools like grep to scan the codebase for common patterns that may be good candidates for optimization. For example:
Find loops that call functions: If the called function returns a list, it could potentially be converted into a generator.
grep -rn "^ *for.*():" /path/to/your/codeFind append, extend, or update operations in loops: This is a common pattern where a list or dictionary is incrementally built up, possibly consuming a lot of memory.
grep -rn "\(append\|extend\|update\)(" /path/to/your/codePitfalls to Avoid
When using generators, be aware of the following pitfalls:
- Don’t call the generator multiple times: Each time you call a generator, it will start from the beginning. Calling the generator multiple times will increase the processing time, which may not be necessary.
- Don’t store the generator’s output in a variable: If you store the output of the generator in a variable (
devices = list(get_nautobot_devices())), Python will loop through the entire generator and store its output in a list, negating any potential memory savings. Instead, use the generator directly in a loop or comprehension.
Next Steps
If you identify any memory-heavy areas in your code, consider refactoring functions that return large datasets into generators. This will allow you to process large amounts of data in a more memory-efficient way, as demonstrated in the Nautobot API example.
Incorporating generators into your network automation tools can ensure that your code scales efficiently, even in environments with hundreds or thousands of devices. Consider applying this approach to your own projects and experience firsthand the performance benefits.
Additional Resources
- PEP 289 – Generator Expressions
- PEP 255 – Simple Generators
- Python Documentation: Generators
- Python Documentation: Yield expressions
- Real Python: Python Generators 101
-Gary
Tags :
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!