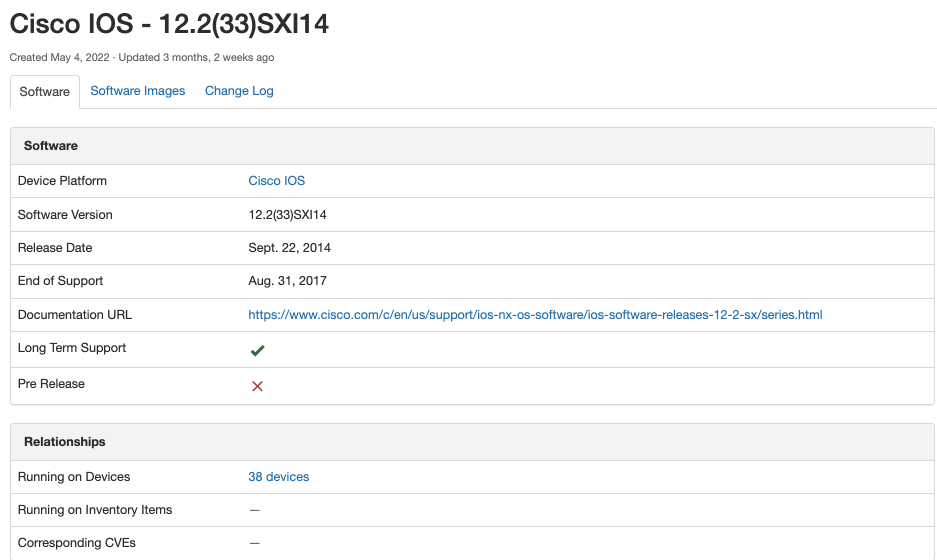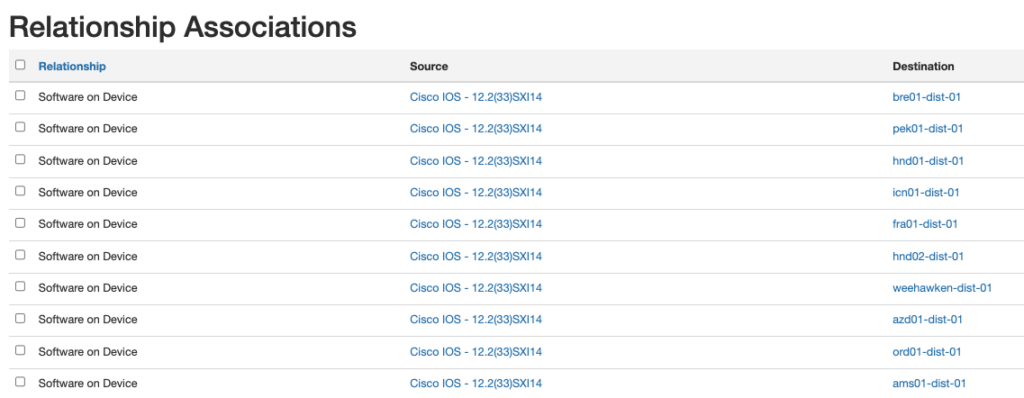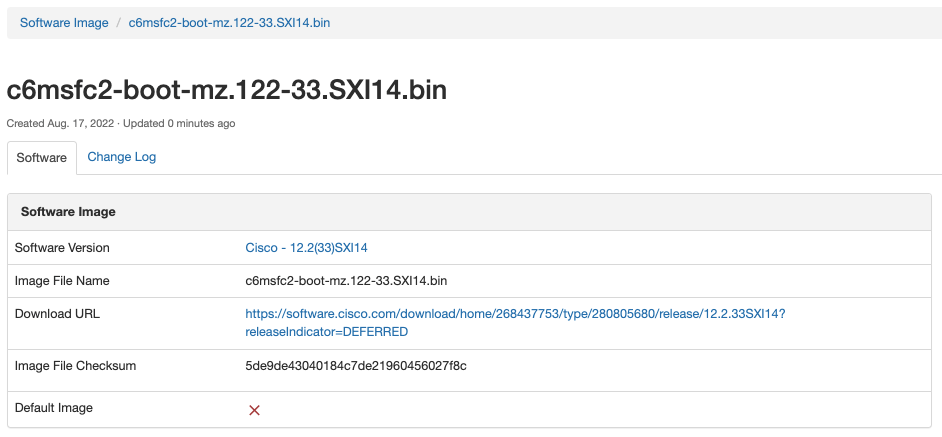
Blog Detail


Raise your hand if you still remember the first time you ever used print() for debugging your code! Perhaps it’s still the case today? Stare at the traceback, find the faulty line number, and insert a print statement just above it hoping to shed some light on the error. Although that’s a simple method, it has never been a very efficient one: the print() statement has to be moved to the next line… and the next one… and the next one… with no option to move around the code in an interactive way or play around with the imported libraries or functions. What about flooding your code in frustration with thousands of prints? There must be a better way to do it, right?
Fortunately, the community has come to our rescue with an amazing library called pdb — The Python Debugger. While you can use pdb as a regular library where you pass arguments—for an example, look at pdb.post_mortem()—we are mainly interested in the interactive debugging mode.
Let’s take a basic example using the NTC open source library—jdiff:
from jdiff import CheckType, extract_data_from_json
def pre_post_change_result(reference, comparison):
"""Evaluate pre and post network change."""
path = "result[*].interfaces.*.[$name$,interfaceStatus]"
reference_value = extract_data_from_json(reference, path)
comparison_value = extract_data_from_json(comparison, path)
my_check = CheckType.create(check_type="exact ")
return my_check.evaluate(reference_value, comparison_value)
if __name__ == "__main__":
reference = {
"result": [
{
"interfaces": {
"Management1": {
"name": "Management1",
"interfaceStatus": "connected",
}
}
}
]
}
comparison = {
"result": [
{
"interfaces": {
"Management1": {
"name": "Management1",
"interfaceStatus": "down",
}
}
}
]
}
pre_post_change_result(reference, comparison)
When I run the above code, however, I get a NotImplementedError:
Traceback (most recent call last):
File "/Users/olivierif/Desktop/test.py", line 38, in <module>
print(pre_post_change_result(reference,comparison))
File "/Users/olivierif/Desktop/test.py", line 8, in pre_post_change_result
my_check = CheckType.create(check_type="exact")
File "/usr/local/lib/python3.10/site-packages/jdiff/check_types.py", line 29, in create
raise NotImplementedError
NotImplementedError
Let’s see how we can debug the above code using pdb. My favorite way is to insert a breakpoint() line in the code, enter in debug mode, and move around from there.
New in version 3.7: The built-in breakpoint(), when called with defaults, can be used instead of import pdb; pdb.set_trace().
def pre_post_change_result(reference, comparison):
"""Evaluate pre and post network change."""
breakpoint()
path = "result[*].interfaces.*.[$name$,interfaceStatus]"
reference_value = extract_data_from_json(reference, path)
comparison_value = extract_data_from_json(comparison, path)
my_check = CheckType.create(check_type="exact")
return my_check.evaluate(reference_value, comparison_value)
As soon as I run the code, the execution pauses and I am dropped into Python interpreter where the breakpoint() line was added. As we can see from the below output, pdb returns the code filename and directory path, the line and line number just below breakpoint(). I can now move around the code and start debugging…
> /Users/olivierif/Desktop/test.py(6)pre_post_change_result()
-> path = "result[*].interfaces.*.[$name$,interfaceStatus]"
Let’s move closer to the line number returned by the traceback. Typing n as next, will move pdb to the next line—line number 7.
(Pdb) n
> /Users/olivierif/Desktop/test.py(7)pre_post_change_result()
-> reference_value = extract_data_from_json(reference, path)
What if we want to print, for example, one of the function arguments or a variable? Just type the argument or variable name… Be aware, though, that the terminal must have passed the line where your variable is defined. pdb knows about only the code that has been through already.
(Pdb) reference
{'result': [{'interfaces': {'Management1': {'name': 'Management1', 'interfaceStatus': 'connected'}}}]}
(Pdb) my_check
*** NameError: name 'my_check' is not defined
(Pdb)
Let’s now use j to jump to the fault code line. Before doing that, let’s see where we are in the code with l as list.
(Pdb) l
2
3 def pre_post_change_result(reference, comparison):
4 """Evaluate pre and post network change."""
5 breakpoint()
6 path = "result[*].interfaces.*.[$name$,interfaceStatus]"
7 -> reference_value = extract_data_from_json(reference, path)
8 comparison_value = extract_data_from_json(comparison, path)
9 my_check = CheckType.create(check_type="exact")
10
11 return my_check.evaluate(reference_value, comparison_value)
12
(Pdb) j 9
> /Users/olivierif/Desktop/test.py(9)pre_post_change_result()
-> my_check = CheckType.create(check_type="exact")
Note that from line 7 I was able to move directly to line 9 with j 9 where 9 is the line number that I want pdb to move to.
Now the cool bit: In the code above, I am using the evaluate method to build my check type. If you remember the traceback, that was the line that gave me the error. While I am in pdb terminal I can s—as step—into that method and move around it:
(Pdb) s
--Call--
> /usr/local/lib/python3.10/site-packages/jdiff/check_types.py(11)create()
-> @staticmethod
(Pdb) l
6
7 # pylint: disable=arguments-differ
8 class CheckType(ABC):
9 """Check Type Base Abstract Class."""
10
11 -> @staticmethod
12 def create(check_type: str):
13 """Factory pattern to get the appropriate CheckType implementation.
14
15 Args:
16 check_type: String to define the type of check.
(Pdb) n
> /usr/local/lib/python3.10/site-packages/jdiff/check_types.py(18)create()
-> if check_type == "exact_match":
Wait… what was the argument passed to this method? Can’t really remember. Let’s type a as for args.
Pdb) a
check_type = 'exact_matches'
(Pdb)
…here we are! The method accepts exact_match string as check type, not exact!
Good, let’s now move pdb until we hit a return or raise line—with r key—so we can see our NotImplementedError line.
(Pdb) r
--Return--
> /usr/local/lib/python3.10/site-packages/jdiff/check_types.py(29)create()->None
-> raise NotImplementedErrorConclusion
As you can see, using pdb is a way more efficient way to debug the code. There are tons of useful functions that can be used in interactive mode, and you can also use it to add useful verbosity to your code. I do invite you to spend some time around docs and play with it. Once you get acquainted with the library, you won’t have any more frustration in debugging your code.
-Federico
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!