

Nautobot is an extensible Source of Truth with a focus on clean network automation data. In a network automation context, clean data is correct (error-free) and properly formatted to be usable by the automation.
Nautobot’s Config Contexts, Config Context Schemas, and Git as a data source extensibility features help ensure data is clean when it is imported into Nautobot and stays clean once it is there. This post discusses the use cases of each feature and how each makes data cleaner. This post will also demonstrate how to import Config Contexts and Config Context Schemas into Nautobot from a Git repository.
Config Contexts
Nautobot’s configuration contexts are used to assign attributes to one or more devices based on some type of context for that device. By “context”, we mean some characteristic of not just the device, but of the device’s circumstances. For example, when a device resides in a certain region or site, there may be special or unique attributes the device needs to inherit that are specific to the region or site.
Config contexts make contextual data easy to associate to devices, which helps minimize errors.
Note: Nautobot has built-in models to hold data for object instances (those objects in DCIM, IPAM, VLANs, etc.), but config contexts allow users to store structured, but unmodeled (by default), data tied to an object.
Nautobot’s Config Context documentation uses syslog servers as an example: devices in a given region need to have region-specific syslog servers configured.
For this demo, we’ll add two config contexts to Nautobot:
- One for
United Statesregional NTP and syslog servers, which should apply to all devices in the region - One for the
atlsite syslog servers, which should be used only for devices in theatlsite, instead of the regional syslog servers
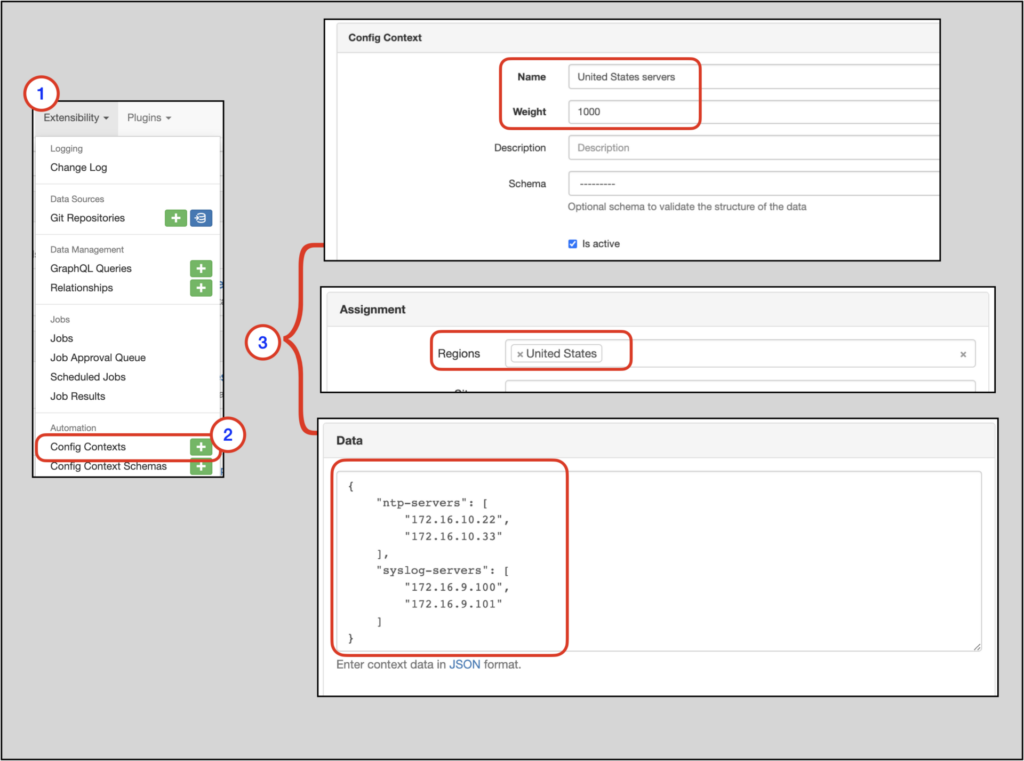
To create a config context, from the top menu navigate to Extensibility–>Config Contexts–> +.
The United States regional data for the NTP and syslog servers will:
- Have a
weightof1000 - Apply to all devices in the
United Statesregion
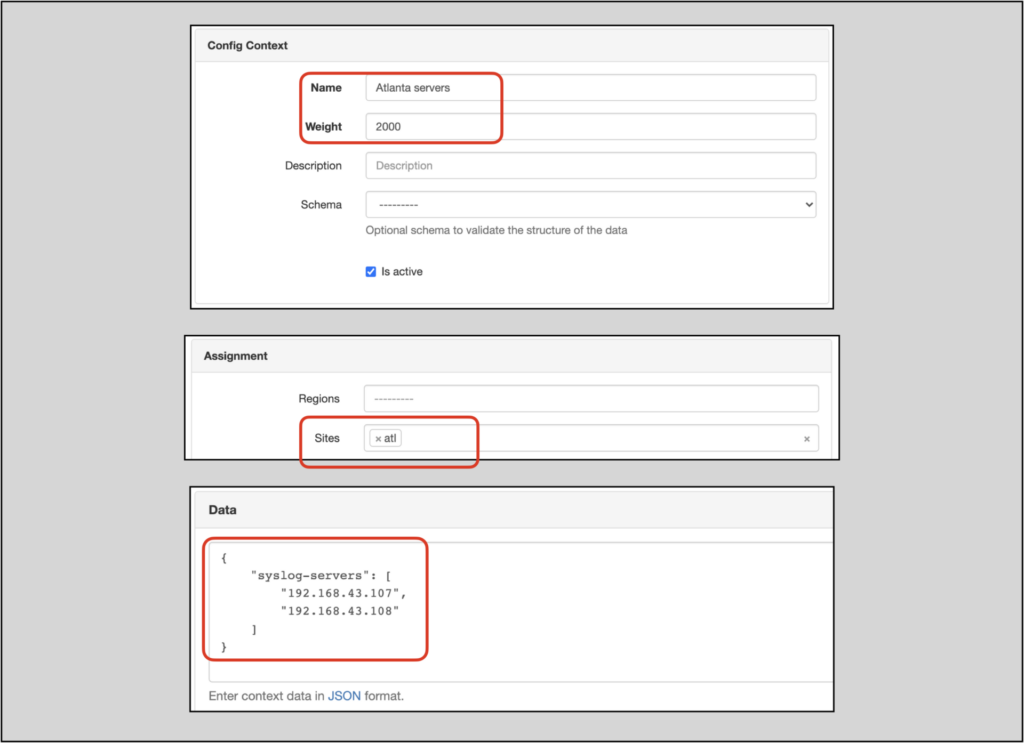
The atl site data for the syslog servers will:
- Have a
weightof2000 - Apply only to devices in the
atlsite
For a device at site atl, such as “atl-edge-01”, the atl site syslog data (weight 2000) will override the United States regional syslog data (weight 1000) because Nautobot uses hierarchical rendering, in which greater weights prevail.
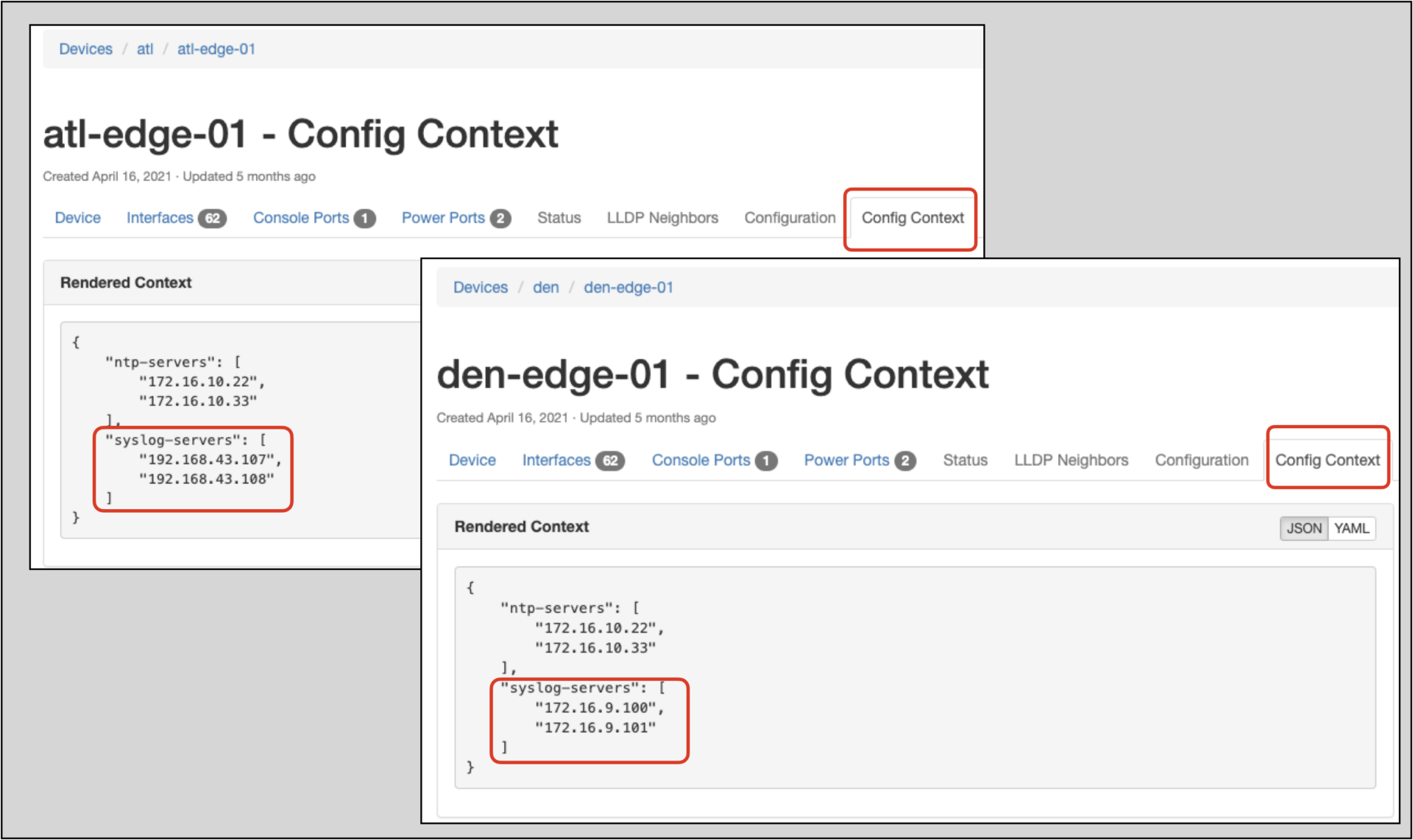
The atl site has site-unique syslog data, while den uses the data from the United States region
JSON and YAML Formatting
Nautobot accepts config context data in the UI in JSON format, but may be viewed as JSON or YAML in the web UI by selecting the appropriate button:
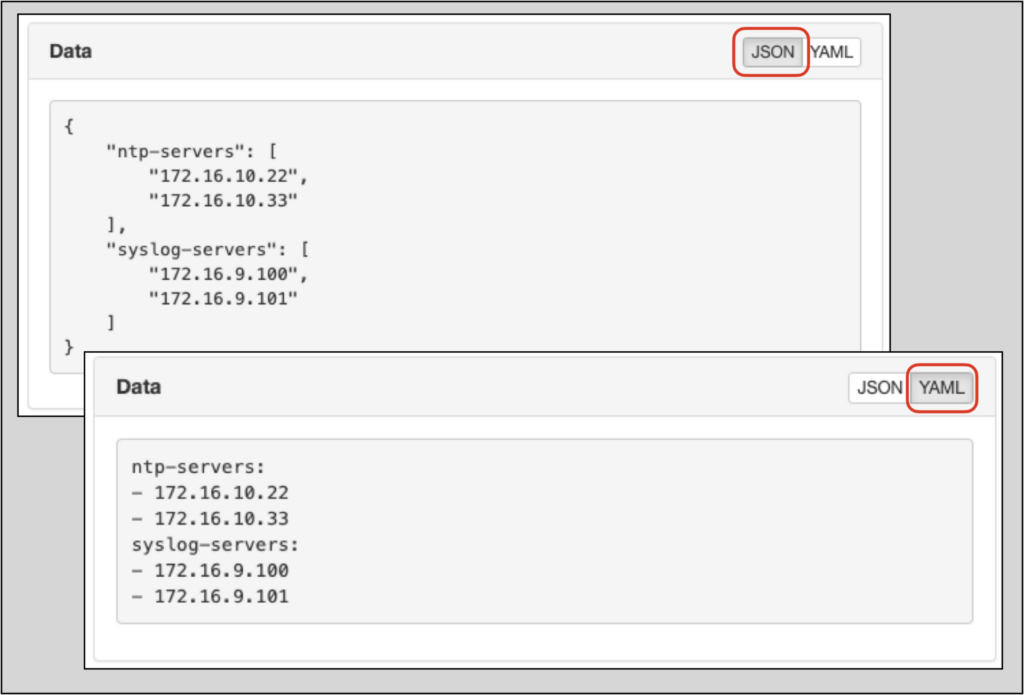
Note: When importing config context data from a Git repository, the data may be in either JSON or YAML format. Git repositories are covered in a later section of this post.
Config Context Schemas
Config contexts allow for arbitrary data structures to be stored within Nautobot, but, at scale, organizations will want to ensure that config contexts adhere to a uniform structure, e.g., a schema or model.
Take the NTP servers as an example. If you have three NTP server config contexts for three regions, you may want to enforce a general data structure uniformity across devices in all three regions, in order to prevent something like this:
Americas NTP Servers:
{
"ntp-servers": [
"172.16.10.22",
"172.16.10.33"
]
}
APAC NTP Servers:
{
"ntp-servers": [
"172.16.13.22",
"172.16.13.33"
]
}
EMEA NTP Servers:
{
"ntp-servers": [
"172.16.17.22,172.16.17.33"
]
}
The EMEA server data has a different structure, which may break a unified automation framework. Let’s use config context schemas to enforce a data format.
In our example situation, we want the following:
- Exactly two servers configured
- The two servers should be members in a list
- The list of members should contain exactly two members
- Each member should be a string in IPv4 format
- No other additional data (properties) can be defined outside of
ntp-servers
Using the config context schema example from the Nautobot documentation, this would be our schema:
{
"type": "object",
"properties": {
"ntp-servers": {
"type": "array",
"minItems": 2,
"maxItems": 2,
"items": {
"type": "string",
"format": "ipv4"
}
}
},
"additionalProperties": false
}
Let’s add that schema now:
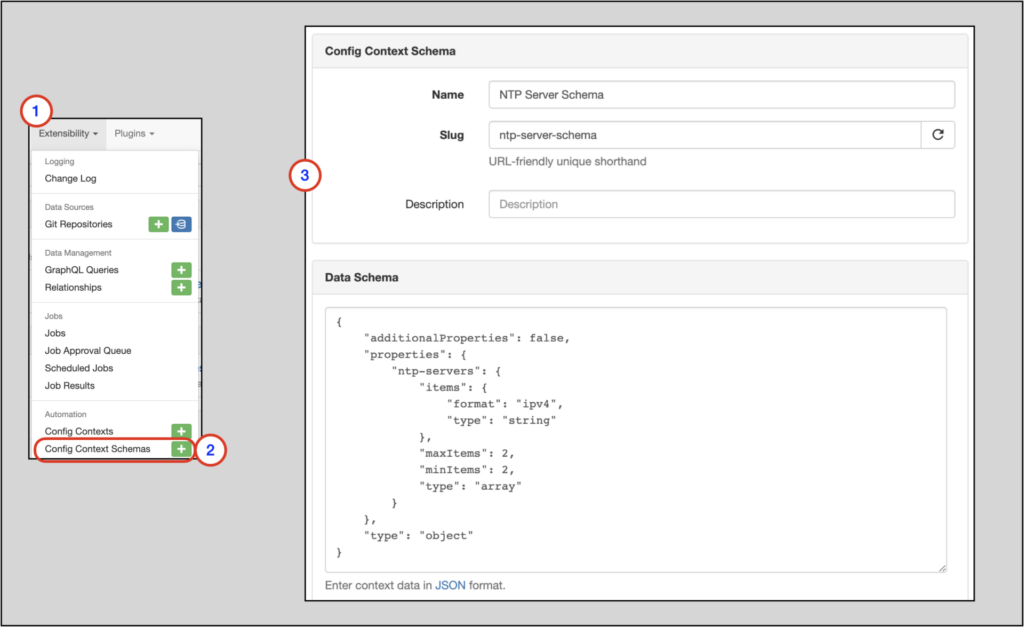
Validating the Config Context Schema
Now that there’s a config context schema in place, we can test it by attempting to add a config context that violates the schema.
The new context schema can be applied from the Add/Edit config context page:
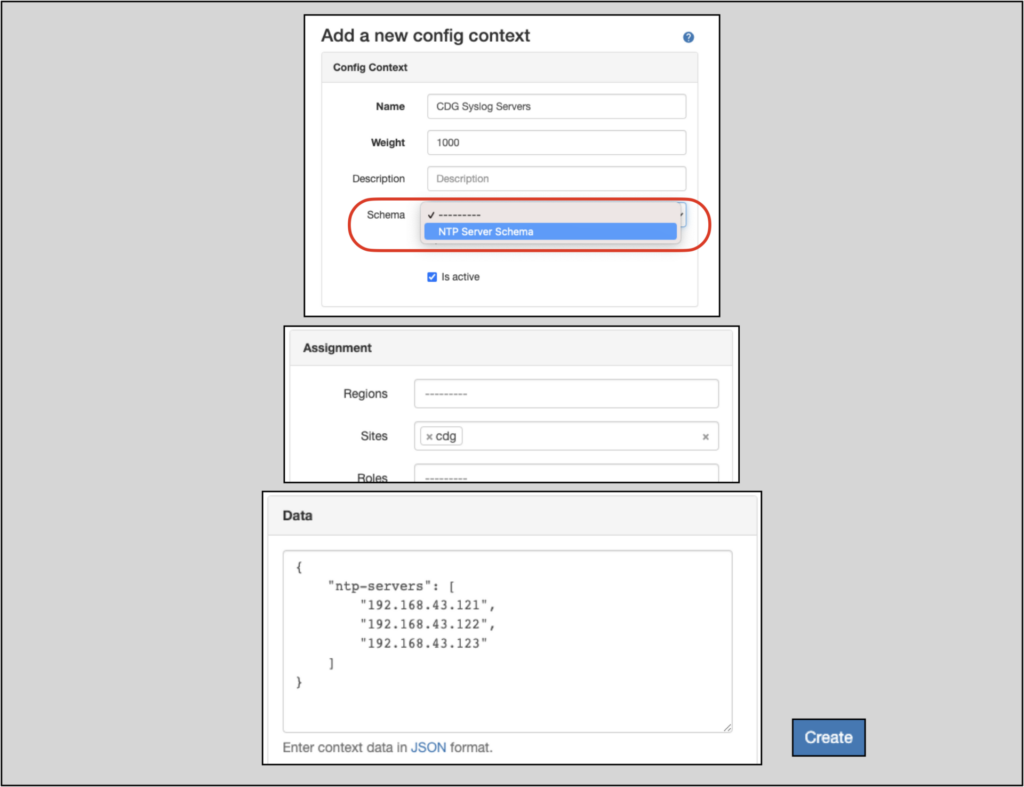
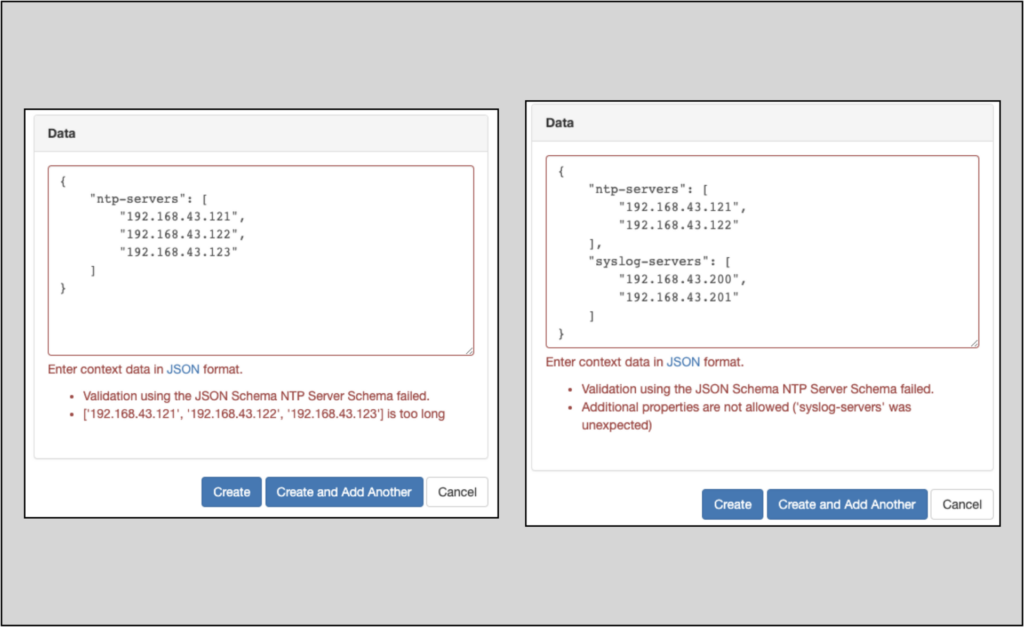
Once we click create, Nautobot returns an error indicating that the list of NTP servers is too long; another failed attempt tried to add syslog server data along with the NTP server data and was also flagged by Nautobot as a schema violation.
Using Git Repositories for Network Data
For some workflows and for some scaling considerations, it may make sense to store config contexts or config context schemas in a Git repository instead of Nautobot.
Scale and Data Quality
At any reasonable scale (and even at smaller scales), it can be impractical to manually input data into a system:
- There may be a lot of data
- The data structure may be complex
These factors make it more likely that there will be errors in data that is manually entered.
Git workflows can greatly minimize the chances of erroneous data because they allow:
- Peer review and discussion of any changes to the data
- Continuous integration/continuous delivery (CI/CD) pipelines to test/validate changes
These Git workflows can make data from Git repositories cleaner than data from other sources.
Importing Data from Git Repositories Into Nautobot
Nautobot’s Git as a data source feature supports importing data, including config contexts and config context schemas, from Git provider repositories. Supported providers include GitHub, GitLab, and Bitbucket.
To work through this example, we will use the user-guide branch from the existing public demo-git-datasource GitHub repo.
To baseline our situation, let’s look at nyc-bb-01.infra.ntc.com, which is a Juniper vMX device. The Config Context tab on the main page for that device shows no info at present:
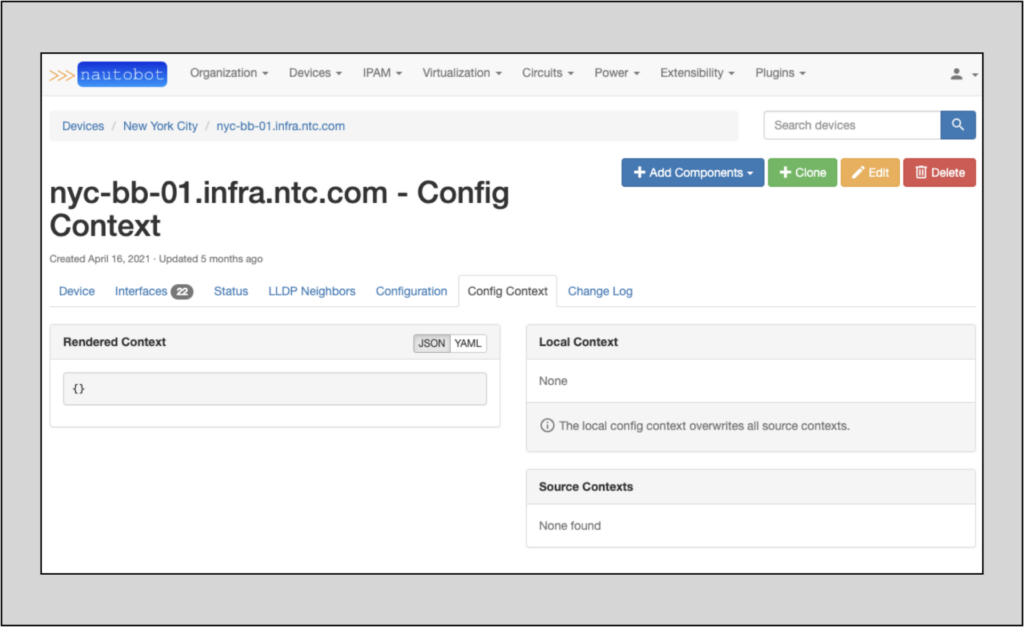
Note: Config contexts may be provided as JSON or YAML files located in the
/config_contexts/folder, which must be in the root of the Git repository.
Examining the Repository
There is a good amount of config context data in this repository branch. Here are the four files that will affect nyc-bb-01.infra.ntc.com:
demo-git-datasource/config_contexts/devices/nyc-bb-01.infra.ntc.com will provide the device’s local context (the data specific to that device):
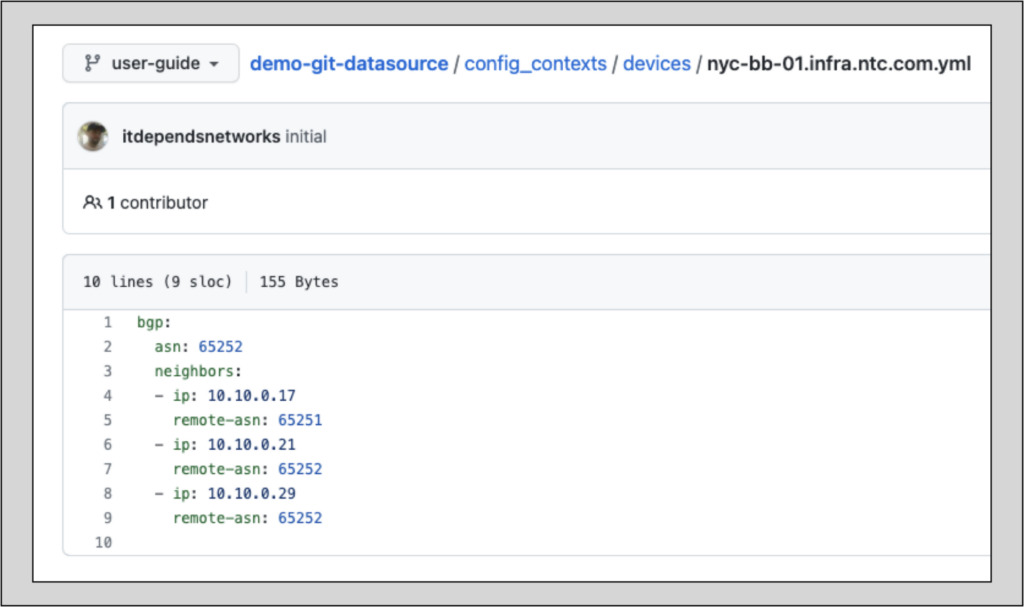
demo-git-datasource/config_contexts/data-models.yml will provide global information:
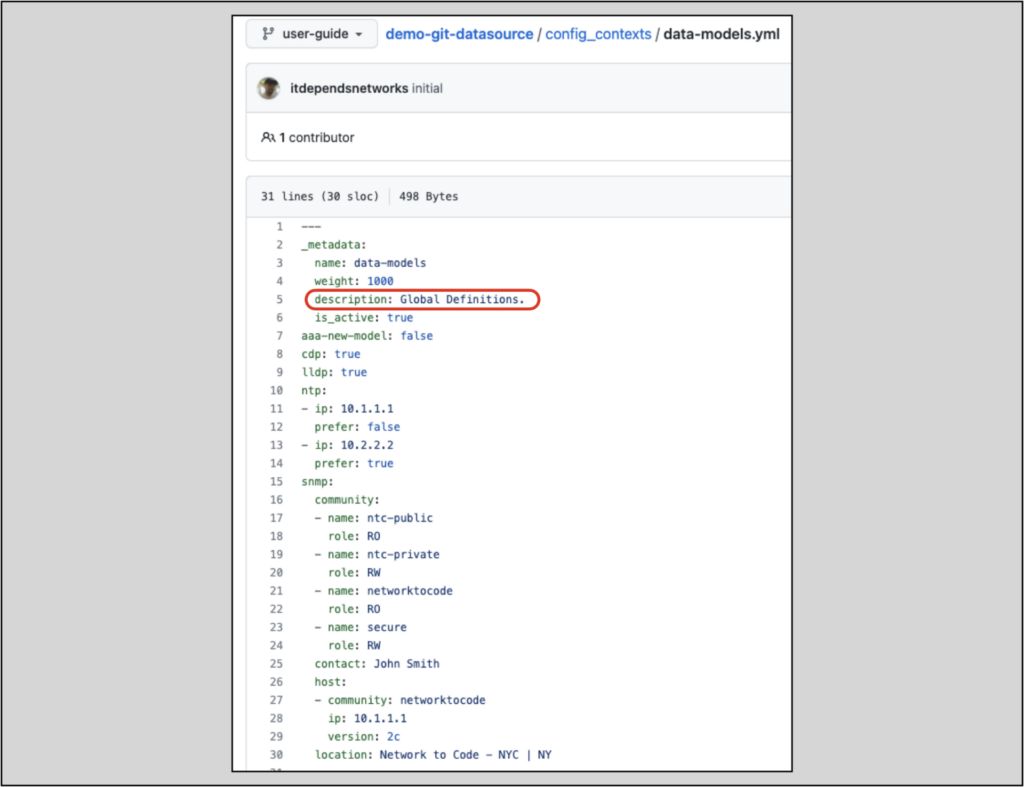
demo-git-datasource/config_contexts/platform_junos.yml will provide platform-specific information:
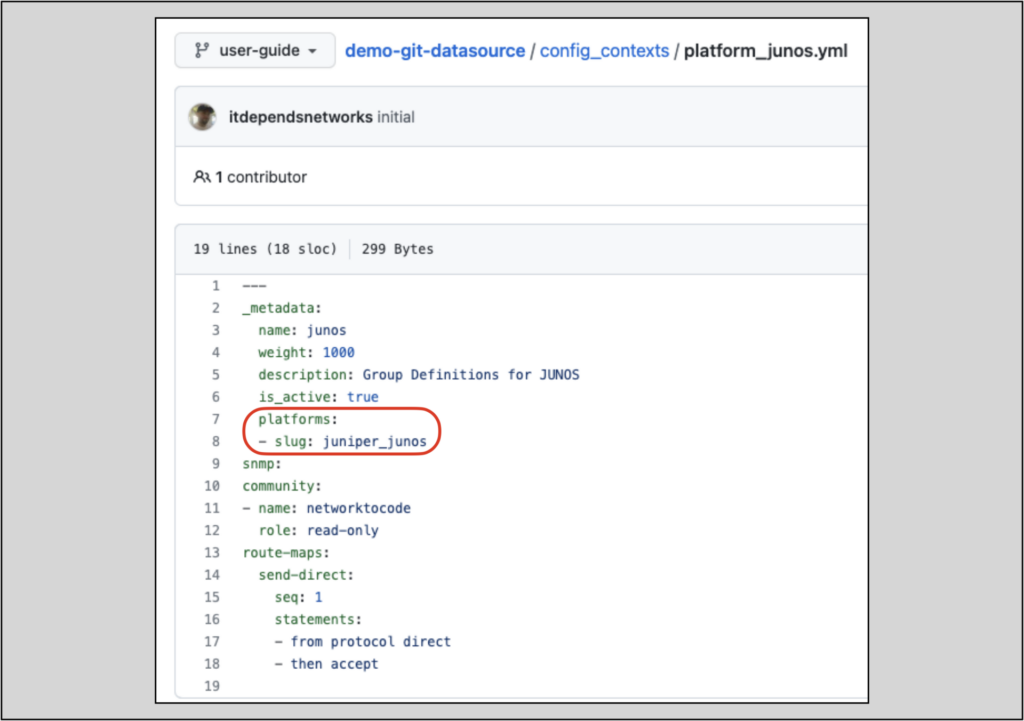
demo-git-datasource/config_contexts/role_spine.yml will provide role-specific information:
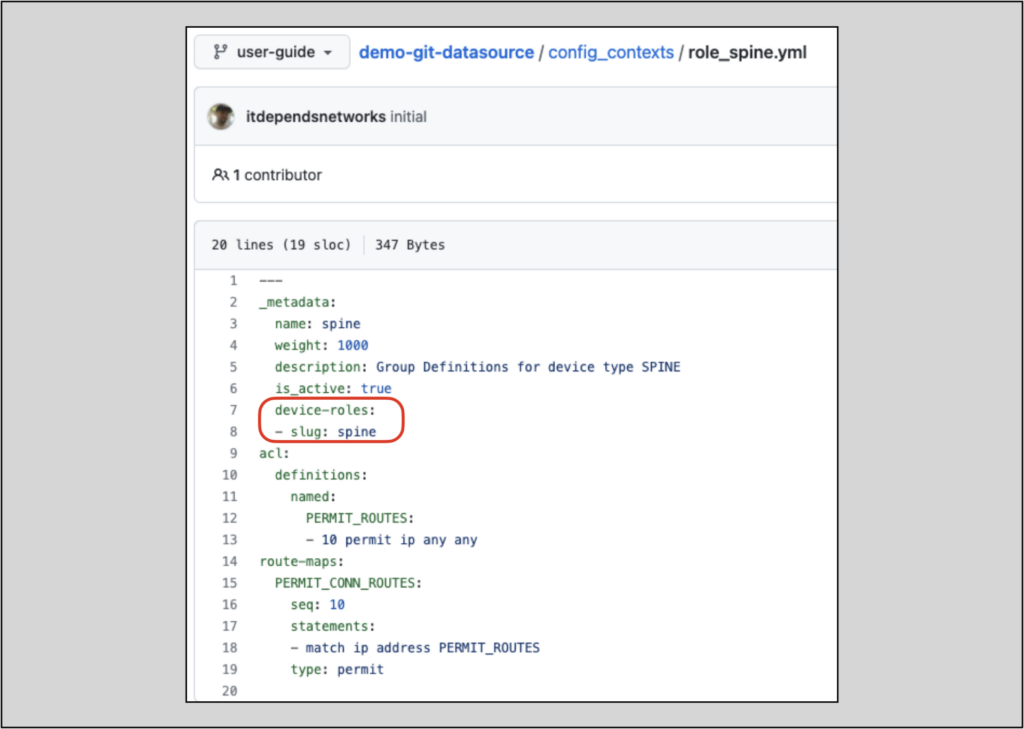
Add a Git Repository
To add the Git repository, navigate to Extensibility–>Data Sources–>Git Repositories–>+.
This picture shows the Add a new Git repository page filled out; this repository will provide config contexts only:
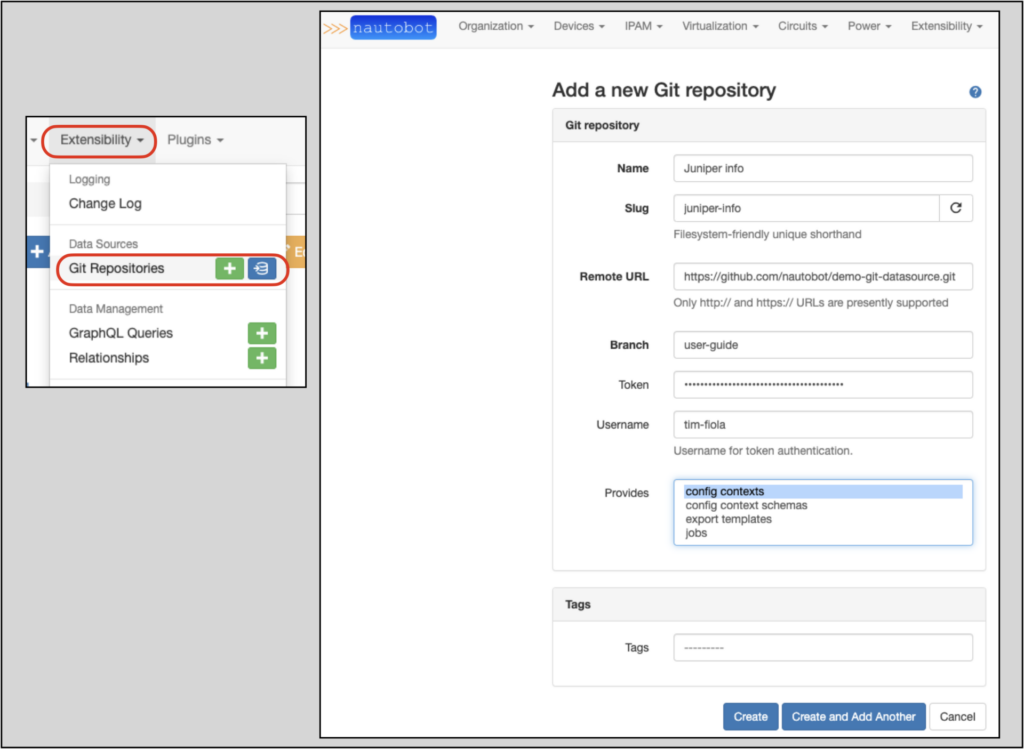
The Nautobot docs on Git as a Data Source contain details on each field on the Add a new Git repository form.
After the repository is added (by clicking the Create button), you should see a page showing a Completed synchronization status:
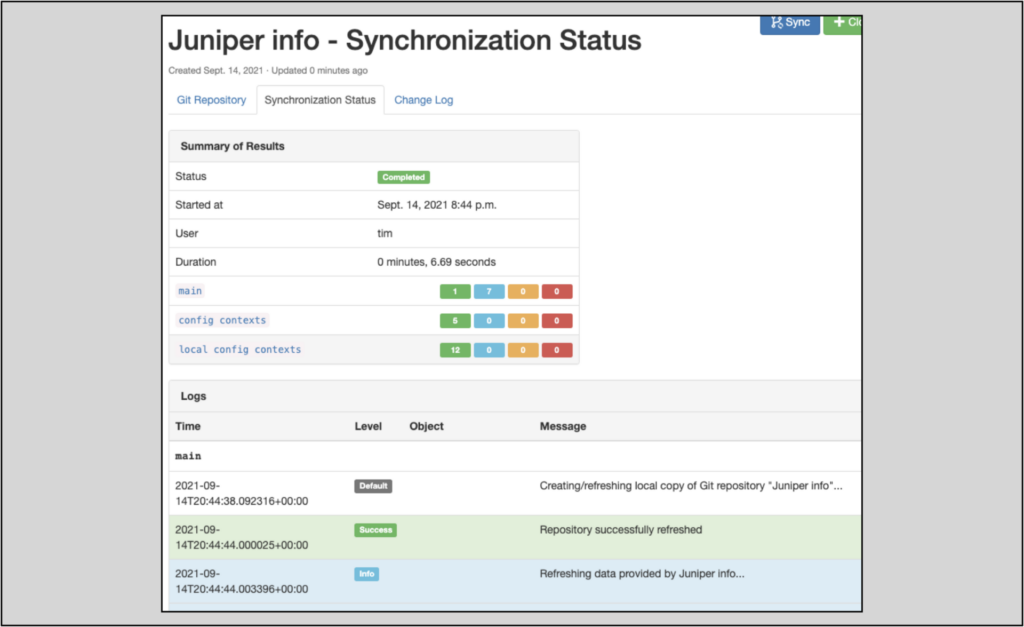
Note: Importing data from Git repositories into Nautobot will be the topic of a future Nautobot blog post.
Results
Once the repository is added, when we return to the Config Context tab on the nyc-bb-01.infra.ntc.com main page, we see three main items:
- The Rendered Context – this is the final data rendering, after all contexts and weights have been applied
- The Local Context – this is data specific to a device and will always take precedence over any other config contexts, regardless of context weight
- In this example, local context came from the
demo-git-datasource/config_contexts/devices/nyc-bb-01.infra.ntc.comfile
- In this example, local context came from the
- Source Context – this is data from other contexts; in this example, those contexts were global, platform, and role

Conclusion
Config Contexts, Config Context Schemas, and Git as a data source are three of Nautobot’s extensibility features. Each of these also plays a role in ensuring the quality of Nautobot’s data:
- Config contexts: Allow users to easily associate specific data based on a device’s context (circumstances)
- Config context schemas: Enforces structure on config context data, minimizing the chance for an unusable/unexpected data structure
- This is especially important in automation, where the automation infrastructure is expecting data in a specific structure
- Importing Git repositories: Enables users to import clean data, including config contexts and config context schemas, from Git repositories
This post has covered the use cases for those features, demonstrated how to implement them, and described the value they provide.
Thank you, and have a great day!
-Tim
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!