

In early October, I had the chance and the opportunity to be part of the team that represented Network to Code at Networking Field Day 21. Participating in Network Field Day is always a challenging exercise as you’re expected to present in front of a group of industry experts that are not shy about asking the hard questions. On top of that they love demos, but only live demos, which adds another level of stress on top of this exercise.
A few weeks ago, while we were brainstorming on what we wanted to demonstrate this time, we decided to try something different. Instead of building the most complex and impressive demo about network automation, we decided to walk the delegates through a journey into network automation. What would it look like to start automating an existing network and step by step turn it into a modern environment? We also wanted to take this opportunity to explain how at Network to Code we are working hand-in-hand with our customers to automate their networks.
When we are engaging with a new customer, the first order of business is usually to do an assessment of the current situation. What are the most important business requirements? What is the current status of the network? Which tools are already in place and which one should stay or be replaced?
Based on this initial assement we build a personalized action plan with each customer, composed of multiple phases. These phases will be different for each customer based on what they already have in place.
As we start implementing these phases and making progress in the network automation journey, we are also working on both formal and informal training to ensure that the team in place is able to follow along what we are doing and feels comfortable with the solution that we are building. It’s very important for the long-term success of the project.
For this exercise, we built a virtual topology composed of 5 different Network OS (NOS): NX-OS, IOS XE, IOS XR, Junos and EOS. It’s very common to find a heterogeneous network composed of very different NOS and its part of the challenge in taking an existing network into automation. Automating a brownfield network is hard, but it’s the most common use case.
When we want to automate a network it’s critical to start thinking about standardization. When it comes to standardization make sure you consider at least the following items at the beginning of a project:

More is not always merrier when it comes to standardization. Not all standards are automation friendly and it’s usually best to keep it simple. For example, most networks already have a naming convention in place, in most cases, it’s trying to fit as much information as possible into the hostname of the device because it’s the only place we can store information.
It usually works well at first but overtime as the network evolves, these very complex rules tend to get in the way of evolution. In an automated environment, where all devices are inventoried properly, you have the ability to store as much metadata/attribute and additional information per device in a structured way as you want, so it’s not required to put everything in the hostname anymore.
The discussion around workflows is usually very interesting and an eye-opening moment for a lot of our customers. Everyone has workflows but in a lot of cases they are not properly documented. It’s not unusual to hear we don’t have a lot of workflows, maybe 1 or 2 with a few steps” at the beginning of the workshop and by the end of the session we have identified 5 to 10 workflows, with more than 10 steps each.
At the end, automation is all about workflow, so this part is very important in a similar way to the naming convention described previously–not all workflows are automation friendly. It’s important to identify the requirements and the dependencies of your workflows and identify where and how this information is available. If some critical information requires a manual intervention late in the process, it will be hard to fully automate this workflow. In this case, it’s important to redesign the workflow and see what information is really mandatory and what’s optional.
To start automating your first workflow, even the simplest, it’s important to have an inventory of your system. It’s not possible to automate without an inventory that contains critical information such as: ip address, platform, role, credentials, etc. An inventory can be as simple as a structured text file (like an ansible inventory) or it can be saved in a database. How you store it is not important as long as you have a proper inventory.
Once you have your inventory, it’s possible to automate the population of all your other tools that maintains their own list of devices. Monitoring tools, DCIM, IPAM etc…
Once you have an inventory, you are ready to start implementing some read-only workflows that won’t harm the network, the most commons are:
During the NFD presentation I demonstrated how from an inventory file I was able to populate all my devices into an DCIM solution like Netbox, including some information like the rack elevation. Then, using a Chatbot that we developed at Network to Code, I was able to gather information from my network directly within Slack leveraging Netbox and Napalm. In this example, among other things, I showed how to gather the LLDP information from a device using Slack, Netbox and Napalm.
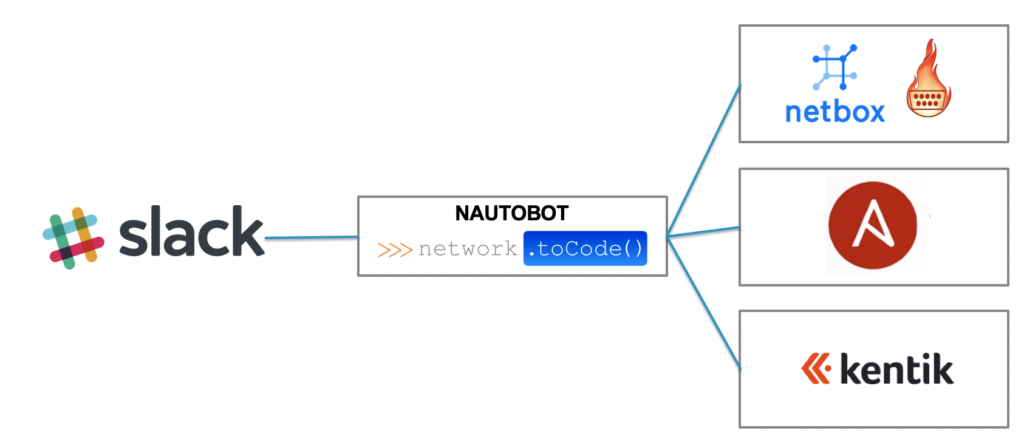
You can watch this part of the demo starting around 8:20min
The next step in a network automation journey is to build a Source of Truth (SOT) to capture the intended state of the network. The Source of Truth is a very important component in your automation framework, if not the most important, but surprisingly it’s not often discussed. John Anderson gave a great introduction to SOT during his presentation earlier at NFD21, you can watch it (around 2:56).
One of the goals is to be able to regenerate all your configurations for your network devices from the Source of Truth and your configuration templates. We’ll address this part in the next section. Now to be able to do that, you need to ensure that your Source of Truth has all the right information:
You probably don’t want to import everything all the time, because it wouldn’t be defined as a Source Of Truth. But, to get started you need to extract as much information as you can, and then you’ll need to curate the data to ensure that everything is in order. This process can take a lot of time and effort, but the outcome is worth it.
During the NFD presentation, I introduced an new tool that we’ve been working on called the network-importer, the idea of the network-importer is to help you import an existing network into a SOT at the beginning of a project, but it can also help you to analyze the differences between the network and the SOT if you already have one. This can also help identify the drift between the SOT and the network if you are not yet ready to generate and deploy your configurations from your SOT. Internally, the network-importer is leveraging multiple open source libraries to extract the relevant information from the network.
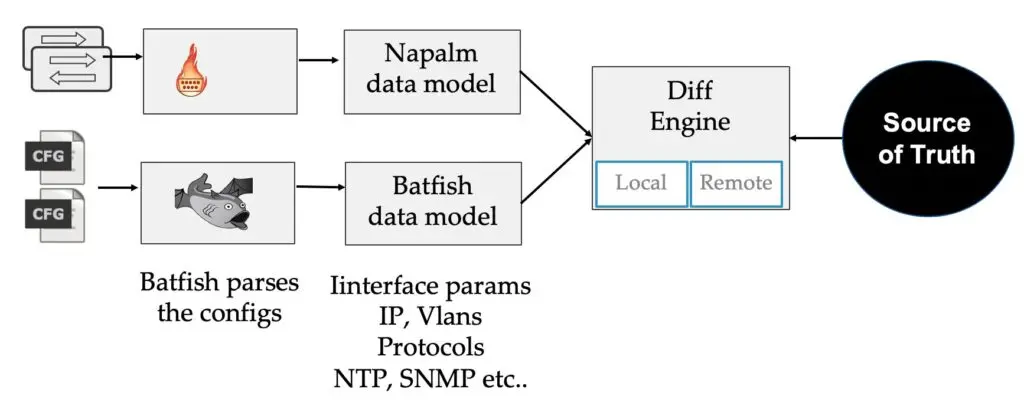
Right now, the network-importer only supports Netbox as a SOT but the goal would be to add more SOT in the future. This project is still at its early stage but once it reaches the right level of maturity, we would like to open source it.
If you are interested in helping beta test, please fill this form and we’ll get back to you when it’s ready
You can watch the demo here starting around 14:41
The last part of my presentation was about configurations generation and especially how to generate configurations from the Source of Truth. Generating configurations from a configuration template is a topic that has been covered many times, and if you’re not familiar with Jinja as a templating language I encourage you to read this great blog about Jinja from my colleague Jeremy Stretch.
In my experience there are other challenges before and after the configuration templating that are important to talk about:
As an example, if you are building the configuration for a Leaf in a spine-leaf design, you’ll need at a minimum this information: hostname, loopback address, asn, all interfaces, all ip addresses, peers ip addresses, peers ASN, vlans information.
In most cases the list is much longer but this list sufficiently highlights the challenges that we need to solve here.
Where you do you get this information and how do you present it in your configuration templates? Usually this information is available in multiple places (multiple Source of Truth) and even if you managed to put everything into a single Source of Truth like we did in step 4, you’ll need to make multiple API calls to get all the information you are looking for. As an example, when working with Netbox, we’ll need to make at least 3 API calls per device:
When using Ansible to build your configurations, the first method could be to make each API call a task in your playbook and register the output of each call into a variable that will be passed to your template. This solution will work, but the format of the data you’ll get in your template won’t be easy to work with and you’ll end up with a very complex Jinja.
Another method would be to build a custom Ansible module in charge of gathering all the information you need and pre-processing the data as required. In this second method, you’ll be able to do some pre-processing of the data before presenting it to the configuration template, which will lead to an easier template.
The picture below shows both approaches side by side.
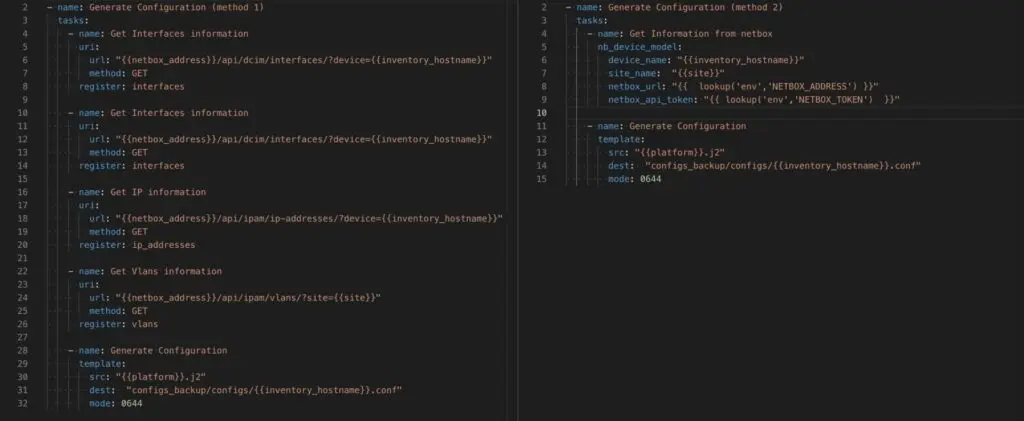
The difference of the length of the playbooks is obvious here but it’s usually not a good indicator to compare 2 playbooks. In this case, the data provided to the configuration template on the right will be easier to work with.
Having a way to test your generated configurations is very important at the beginning of the project of course, but it also helps each time you want to refactor your configuration templates or refactor how you are collecting and gathering your data. Having a robust solution to safely iterate on your automation stack is going to play a big role in your ability to adapt quickly to your environment.
Like in software development, a proper testing strategy should have different level of tests. In software development we called them : unit tests, functional tests, integration tests. The solution that we are exploring in this article would qualify as functional test. We won’t cover the other type of tests in this article.
If you have an example of what your final configuration should look like (the reference), this can be either the current running configuration or a previously generated configuration, you can generate a diff between your newly generated configuration and the reference one. Usually the goal is that both should be identical and the diff should return nothing. If the diff is returning an unexpected change then you know something is not right either in your data or in your configuration template.
Ansible provides an easy solution to generate diff between 2 files when using the option --diff. If you combine that with the dry-run mode (--check), you’ll be able to see the changes that you are about to make without touching your reference file.
Below is an example of a playbook that will generate a new configuration from your template and compare it with the last backup configuration (reference) without changing it. The key here is to use the options check_mode: yes and diff: yes on the second task in the playbook.
- name: Generate and Compare Configuration (do not save it)
tasks:
- name: Get Information from netbox
nb_device_model:
device_name: "{{ inventory_hostname }}"
site_name: "{{ site }}"
netbox_url: "{{ lookup('env','NETBOX_ADDRESS') }}"
netbox_api_token: "{{ lookup('env','NETBOX_TOKEN') }}"
- name: Check Configuration
template:
src: "{{ platform }}.j2"
dest: "configs_backup/configs/{{ inventory_hostname }}.conf"
mode: 0644
check_mode: yes
diff: yes
Below is an example of what you will get if there is a difference between your new configuration and the reference one. In this case, my new configuration is missing vlan 1001. I need to check my Source of Truth to ensure that it’s properly defined there.
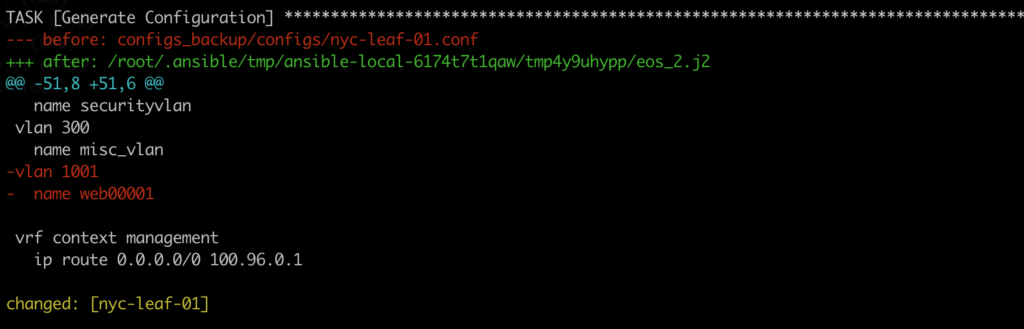
Unfortunately, I wasn’t able to present this part because we were running a bit late so no video this time
-Damien (@damgarros)
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.






Share details about yourself & someone from our team will reach out to you ASAP!