

Which data type is more popular, JSON or XML? I believe the overwhelming majority will say “JSON”, which is understandable, because JSON is easier to read, easier to understand, and more human friendly. Besides that, there are a lot of reading materials around JSON and how to handle such data. But what to do when only XML is supported?
The default solution for most of us today is to convert XML to JSON or Python dictionary. But this approach has some significant drawbacks because XML and JSON are not 100% compatible. XML doesn’t have the same distinction between a list and a dictionary. Depending on what you are processing you can end up with a different datastructure if you have one element returned, an interface for example, or multiple.
There is a better way to process XML data in Python by using the native construct and libraries available. This blog is intended to give you tips and tricks on how to parse XML data with Python and Ansible.
In this section, we will briefly go over the XML Data Structure and the terminology used in it, which will help us better understand the XML data.
The image below depicts a sample XML data in a tree format.
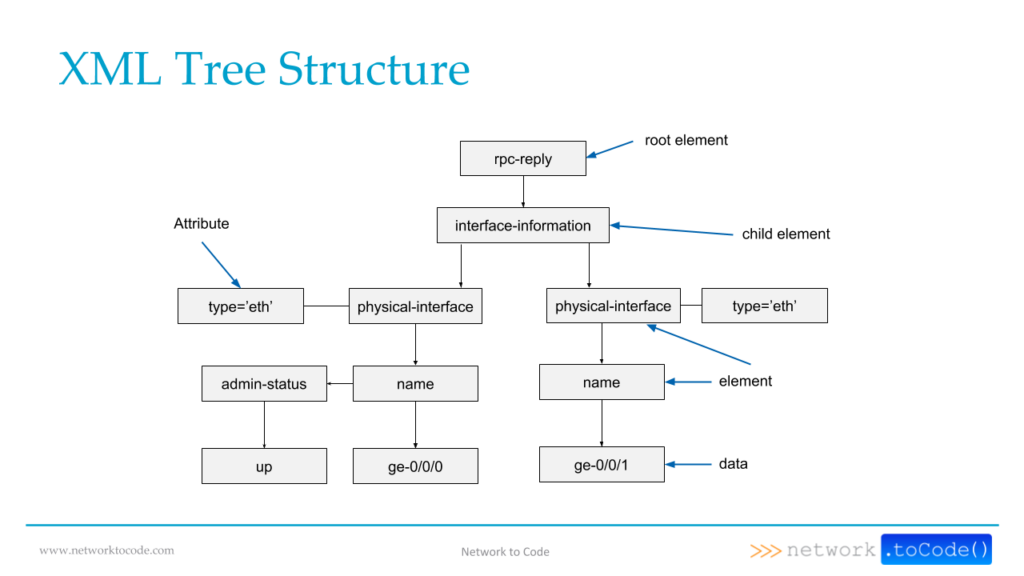
The corresponding XML data will look like this:
<rpc-reply>
<interface-information>
<physical-interface type='eth'>
<name>ge-0/0/0</name>
<admin-status>up</admin-status>
<oper-status>up</oper-status>
<logical-interface>
<name>ge-0/0/0.0</name>
<admin-status>up</admin-status>
<oper-status>up</oper-status>
<filter-information>
</filter-information>
<address-family>
<address-family-name>inet</address-family-name>
<interface-address>
<ifa-local>172.16.0.151/24</ifa-local>
</interface-address>
</address-family>
</logical-interface>
</physical-interface>
</interface-information>
</rpc-reply>
NOTE
Some XML data will have namespaces, and we will address them a bit later.
Now let’s explain the terminology depicted in the image:
NOTE
This is not a complete overview of the XML, but rather a quick introduction to it. The complete information about the XML can be found here.
Python has a very sophisticated built-in library called xml.etree.ElementTree to deal with XML data. Before we jump into the Python interpreter and start parsing the data, we will need to address XML XPath and the methods available to the xml.etree.ElementTree class.
XPath uses path expressions to find element(s) and relative data in the XML document. The xml.etree.ElementTree supports the following XPath expressions1:
| Syntax | Meaning |
|---|---|
| tag | Selects all child elements with the given tag. For example, spam selects all child elements named spam, and spam/egg selects all grandchildren named egg in all children named spam. {namespace}* selects all tags in the given namespace, {*}spam selects tags named spam in any (or no) namespace, and {}* selects only tags that are not in a namespace. |
| * | Selects all child elements, including comments and processing instructions. For example, */egg selects all grandchildren named egg. |
| . | Selects the current node. This is mostly useful at the beginning of the path, to indicate that it’s a relative path. |
| // | Selects all subelements, on all levels beneath the current element. For example, .//egg selects all egg elements in the entire tree. |
| .. | Selects the parent element. Returns None if the path attempts to reach the ancestors of the start element (the element find was called on). |
| [@attrib] | Selects all elements that have the given attribute. |
| [@attrib=’value’] | Selects all elements for which the given attribute has the given value. The value cannot contain quotes. |
| [tag] | Selects all elements that have a child named tag. Only immediate children are supported. |
| [.=’text’] | Selects all elements whose complete text content, including descendants, equals the given text. |
| [tag=’text’] | Selects all elements that have a child named tag whose complete text content, including descendants, equals the given text. |
| [position] | Selects all elements that are located at the given position. The position can be either an integer (1 is the first position), the expression last() (for the last position), or a position relative to the last position (e.g., last()-1). |
These are the methods and attributes that we will be using:
NOTE
All elements of the loaded XML data will be objects of theElementPython class and will support these methods and attributes.
Methods:
iter("<element>") – recursively iterates over all the sub-tree below the root element. Requires the element name.findall("<xpath-expression>") – finds elements using XPath expression.find("<element>") – finds the first child element with a particular tag.get("<attribute-tag>") – gets the element’s attribute value.Attributes:
tag – shows the tag name of the element (rpc-reply).attrib – shows the value of the attribute ({'type': 'eth'}).text – shows the data assigned to the element (ge-0/0/0.0).
Now we are ready to work with the XML data. Let’s start by opening the Python interpreter and importing the xml.etree.ElementTree class as ET for brevity.
>>> import xml.etree.ElementTree as ET
We will need to load the data now. It can be done two ways. Either load the XML file with the parse() method then obtain the root element with getroot() method, or load it from string using fromstring().
NOTE
We will be using the XML data shown in the XML Data Structure section, but with more interfaces.
>>> tree = ET.parse('interface_data.xml')
>>> root = tree.getroot()
or
>>> root = ET.fromstring(interface_data)
To print the tag of the root element we can use the tag attribute
>>> root.tag
'rpc-reply
Let’s iterate of the child elements of the root element and print its tag names:
>>> for child in root:
... print(child.tag)
...
interface-information
As we can see from the output, the root element has only one child element, with interface-information tag name. To see more data, we can iterate over the interface-information element and print its elements’ tag names and attributes:
>>> for child in root:
... for element in child:
... print(f"Element Name: {element.tag} Element Attribute: {element.attrib}")
...
Element Name: physical-interface Element Attribute: {'type': 'eth'}
Element Name: physical-interface Element Attribute: {'type': 'eth'}
Element Name: physical-interface Element Attribute: {'type': 'eth'}
Element Name: physical-interface Element Attribute: {'type': 'eth'}
Element Name: physical-interface Element Attribute: {'type': 'eth'}
Even though the nested iteration works, it is not optimal, since the XML tree can have several layers. Instead, we can use iter() method and provide an element name as a parameter. In this case, we will iterate over only the found elements. For example, let’s iterate over all name elements and show their contents.
>>> for element in root.iter('name'):
... print(element.text)
...
ge-0/0/0
ge-0/0/0.0
ge-0/0/1
ge-0/0/1.0
ge-0/0/2
ge-0/0/2.0
ge-0/0/3
ge-0/0/3.0
ge-0/0/4
ge-0/0/4.0
In the same way, we can iterate over the elements in question, but with the help of the findall() method. For it, we will need to provide XPath expression as an argument. This time, we would like to print all IP addresses that are assigned to the ifa-local element:
NOTE
The period before the forward slashes indicates that the search needs to happen from current element.
>>> for element in root.findall('.//ifa-local'):
... print(element.text)
...
172.16.0.151/24
192.168.10.1/24
10.10.10.1/24
172.31.177.1/24
192.168.0.1/24
The XPath expression to find a particular element with a specific attribute will be a little bit different. For it, we will need to use findall(.//*[@type]) syntax to search from current element against all the elements that have an attribute tag of type:
>>> for element in root.findall('.//*[@type]'):
... print(element.tag, element.attrib)
...
physical-interface {'type': 'eth'}
physical-interface {'type': 'eth'}
physical-interface {'type': 'eth'}
physical-interface {'type': 'eth'}
physical-interface {'type': 'eth'}
XML Namespaces are used to group certain elements identified by Uniform Resource Identifier (URI) and avoid any element name conflicts in the XML document. Detailed information about XML Namespaces can be found here.
Let’s look at an XML data with name spaces.
<rpc-reply xmlns:junos="http://xml.juniper.net/junos/20.2R0/junos">
<interface-information xmlns="http://xml.juniper.net/junos/20.2R0/junos-interface" junos:style="terse">
<physical-interface type='eth'>
<name>ge-0/0/0</name>
<admin-status>up</admin-status>
<oper-status>up</oper-status>
<logical-interface>
<name>ge-0/0/0.0</name>
<admin-status>up</admin-status>
<oper-status>up</oper-status>
<filter-information>
</filter-information>
<address-family>
<address-family-name>inet</address-family-name>
<interface-address>
<ifa-local>172.16.0.151/24</ifa-local>
</interface-address>
</address-family>
</logical-interface>
</physical-interface>
</interface-information>
</rpc-reply>
If we try to find a specific element using one of the methods that we discussed before, soon we will find out that no elements are matched.
>>> tree_xmlns = ET.parse("interface_data_with_xmlns.xml")
>>> root_xmlns = tree_xmlns.getroot()
>>> for element in root_xmlns.findall('.//ifa-local'):
... print(element.text)
...
>>>
The reason is that each element of the interface-information child element is appended with {URI} tag. To see how it looks, we can print the tag name of the root’s child-element:
NOTE
The root element does not have the URI tag appended since it has only XML name definition rather than assignment.>> print(root_xmlns[0].tag) {http://xml.juniper.net/junos/20.2R0/junos-interface}interface-information >>Now, if we change the syntax and search for the all
ifa-localelements, we should get the desired result:>> for element in root_xmlns.findall('.//{http://xml.juniper.net/junos/20.2R0/junos-interface}ifa-local'): ... print(element.text) ... 172.16.0.151/24 192.168.10.1/24 10.10.10.1/24 172.31.177.1/24 192.168.0.1/24Python recommends a different way to search for elements with namespace. For that, we will need to create a dictionary and map a key to the namespace URI, then, using the desired class method, provide the dictionary as a second argument. The syntax looks like this:
>> ns = dict(interface="http://xml.juniper.net/junos/20.2R0/junos-interface") >> for element in root_xmlns.findall('.//interface:ifa-local', ns): ... print(element.text) ... 172.16.0.151/24 192.168.10.1/24 10.10.10.1/24 172.31.177.1/24 192.168.0.1/24In Python 3.8 and above, the namespace can be referenced with an asterisk character(
*):>> for element in root_xmlns.findall('.//{*}ifa-local'): ... print(element.text) ... 172.16.0.151/24 192.168.10.1/24 10.10.10.1/24 172.31.177.1/24 192.168.0.1/24
Parsing XML with Ansible can be done using two methods. The first method involves using community.general.xml module which is very well documented. The second, more interesting, one using the parse_xml filter. Here we will be showing the second option.
parse_xmlAnsible FilterTo use the filter, we will need to create a specification file. The file has two parts: the first part defines the elements that need to be extracted from the XML data. The second part defines the variables and their values that will be available in the Ansible Playbook. We will start by looking at the first part.
keys:
result:
value: "{{ dev_intf }}"
top: interface-information/physical-interface
items:
name: name
admin_status: admin-status
oper_status: oper-status
ifl_name: logical-interface/name
ip_addr: .//ifa-local
Let’s break it all down:
keys – This is a predefined root level key name.result – The name of this key can be set to anything.value – This is a predefined key which holds a Jinja2 variable which will be mapped to a variable that will be defined in the second part of the specification file.top – This key holds the path to the element that will be iterated over for data extraction. Note that the path starts from the child element not the root element.items – This is a predefined key which will hold multiple items.
name – Key that will hold the value that is assigned to the <name></name> element.admin_status – Key that will hold the value that is assigned to the <admin-status></admin-status> element.oper_status – Key that will hold the value that is assigned to the <oper-status></oper-status> element.ifl_name – Key that will hold the value that is assigned to the <name></name> element which is a child elment of the <logical-interface></logical-interface> element.ip_addr – Key that will hold the value that is assigned to the <ifa-local></ifa-local> element. Note that here we are using XPath expression to locate the desired element.Now let’s look at the second part of the file and break it down:
vars:
dev_intf:
name: "{{ item.name }}"
admin_status: "{{ item.admin_status }}"
oper_status: "{{ item.oper_status }}"
ifl_name: "{{ item.ifl_name }}"
ip_addr: "{{ item.ip_addr }}"
vars – This is a well-known Ansible key for defining variables.dev_intf – The root key named by us that will hold the data extracted from the XML.
name – Variable key that will hold the value assigned to the name key defined under items.admin_status – Variable key that will hold the value assigned to the admin_status defined key under items.oper_status – Variable key that will hold the value assigned to the oper_status defined key under items.ifl_name – Variable key that will hold the value assigned to the ifl_name defined key under items.The entire specs file looks like this:
keys:
result:
value: "{{ dev_intf }}"
top: interface-information/physical-interface
items:
name: name
admin_status: admin-status
oper_status: oper-status
ifl_name: logical-interface/name
ip_addr: .//ifa-local
vars:
dev_intf:
name: "{{ item.name }}"
admin_status: "{{ item.admin_status }}"
oper_status: "{{ item.oper_status }}"
ifl_name: "{{ item.ifl_name }}"
ip_addr: "{{ item.ip_addr }}"
Now let’s look at the simple Ansible Playbook in which we will use the parse_xml filter.
- name: READ XML
connection: local
gather_facts: no
hosts: localhost
tasks:
- set_fact:
parsed_xml_data: "{{ lookup('file', 'interface_data.xml') | parse_xml('interface.specs') }}"
- debug:
var: parsed_xml_data
Finally, let’s run the Playbook against the XML data and see the output.
$ ansible-playbook pb_parse_xml.yml
PLAY [READ XML] *******************************************************************************************************
TASK [set_fact] *******************************************************************************************************
ok: [localhost]
TASK [debug] **********************************************************************************************************
ok: [localhost] => {
"xml_data_parsed": {
"result": [
{
"admin_status": "up",
"ifl_name": "ge-0/0/0.0",
"ip_addr": "172.16.0.151/24",
"name": "ge-0/0/0",
"oper_status": "up"
},
{
"admin_status": "up",
"ifl_name": "ge-0/0/1.0",
"ip_addr": "192.168.10.1/24",
"name": "ge-0/0/1",
"oper_status": "up"
},
{
"admin_status": "up",
"ifl_name": "ge-0/0/2.0",
"ip_addr": "10.10.10.1/24",
"name": "ge-0/0/2",
"oper_status": "up"
},
{
"admin_status": "up",
"ifl_name": "ge-0/0/3.0",
"ip_addr": "172.31.177.1/24",
"name": "ge-0/0/3",
"oper_status": "up"
},
{
"admin_status": "up",
"ifl_name": "ge-0/0/4.0",
"ip_addr": "192.168.0.1/24",
"name": "ge-0/0/4",
"oper_status": "up"
}
]
}
}
PLAY RECAP ************************************************************************************************************
localhost : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0I hope this post will help you understand how to parse XML data natively in Python and Ansible without converting it to JSON automatically.
-Armen
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.






Share details about yourself & someone from our team will reach out to you ASAP!