

Data is a crucial aspect for all network automation solutions, whether it’s a quick script, or a complex workflow using automation systems. Automated processes need data to drive their outcome by knowing what devices are involved and what actions to take on those devices.
Data can exist in many forms from a simple text file with a few items to a multi-tabbed spreadsheet to a database full of tables and views. Ever make a shopping list? How about storing contact information in your phone? Do you use a calendar to plan your schedule? All of these are examples of real-world structured data that we leverage without really thinking about it.
What Is Structured Data?
When we mention structured data, we are simply talking about organizing data in a common format so that it can be easily understood and leveraged. Take contact information in your phone as an example. Every time you access your contacts, you see the data in the same format regardless of what contact in your phone you are looking at:
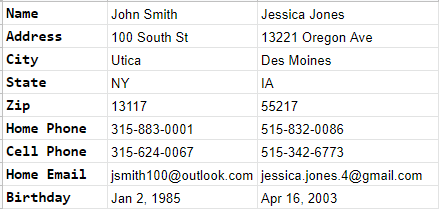
Now, imagine if the contacts in your phone were unstructured. While each of the contact records contain the same data, it’s now displayed in a different order from one person to the next.
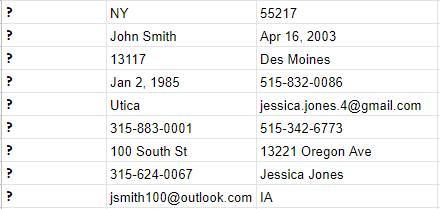
How challenging would it be to use this data? Which is the home phone number and which is the cell number? With this basic example you can see why structured data is so important. It keeps things consistent, and easy to use.
One question that comes up is “Are data structures the same as structured data?” They are similar in the fact they both deal with organizing and storing data, but data structures are more closely tied to how a computer program stores and accesses data in memory to minimize compute resource usage and maximize program run time. You can check out this blog Mikhail Yohman wrote on some basic Python data structures to get a better understanding: Intro to Data Structures.
Let’s shift our focus to structured data seen and used by network engineers.
Structured Data in Network Engineering
Structured data exists in a variety of places in the network engineering space, but the most notorious example is…… drum roll ….. the Excel spreadsheet or csv file! An example of a basic spreadsheet a network engineer may come across tracking network asset inventory is seen below. We’ll use this example and data throughout our blog series:

Network engineers use spreadsheets as a quick and easy way to manage data for various projects quite simply because it works. A tabular format is very easy for humans to interpret, and it can often be imported easily into scripts for programs to use. However, spreadsheets can often contain repetitive data which makes them less than ideal to use, or they can be extremely cumbersome if there are tens or hundreds of thousands of rows and numerous columns.
Inventory information isn’t the only network data stored in spreadsheets. How many of you have seen configuration snippets, or even entire configurations/templates, stored in spreadsheets too? Take a common task of deploying SNMP commands to devices on the network to use as an example. We want to deploy the following commands to all of our devices:
- snmp-server location {data}
- snmp-server contact {data}
- snmp-server chassis-id {data}
- snmp-server community {data} RO
- snmp-server community {data} RW
Let’s be honest, the first thing most network engineers will do is take the data from the device inventory and manually apply it to the configuration command formats above to build the configuration per device. This is likely done with a bunch of copying and pasting, using older configs as a template to build out the new config, or for those more savvy, writing a macro or using a formula in the spreadsheet (concatenate, anyone?) to get the results a little quicker. The output would be something like what is seen below, which would then be copied and pasted one at a time into each device during a change window:


Is this doable? You bet! But… it’s not ideal. I’d venture to guess most folks reading this have been bitten by the manual entry, or copy/paste, monster at some point in their career and spent time in the wee hours of the morning addressing an outage. There are more effective ways for us to structure the data above for this solution especially if we want to leverage it in a flexible, standardized, automated process.
Conclusion
I cannot stress enough the importance of ensuring your data is both structured and normalized (eliminating redundant data where possible). In the next three parts of this series, we’ll leverage the same spreadsheet data above when we dive into structured data formats regularly seen in network automation solutions: XML, YAML, and JSON. We’ll talk about those specific formats, when/why we may use one over another, how the structured data can be applied to template solutions like Jinja2, and how it all ties together to produce a flexible, standardized automated solution. As always, if you have any questions/comments, we’re here to help! Come join us on the Network to Code Slack.
-Dave
Tags :
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!