

Just like The Fast and the Furious movies, we are going to be churning out sequels like no other! Welcome to Part 2 of the Telemetry Stack! series, where we walk you through the different stages of bringing insight into your infrastructure. Although there won’t be a special appearance from Ludacris in this sequel, you are in for a heck of a ride!
In this post we will focus on the concept of normalizing data between multiple systems and adding value with enrichment. To help follow along with some of the keywords used in this post, I recommend checking out Part 1 written by Nikos Kallergis for a refresher.
Normalization and Enrichment
During Part 1 we discussed the TPG stack, its different layers, and how to get started with Telegraf. Now it’s time to talk about processing those metrics into something more useful!
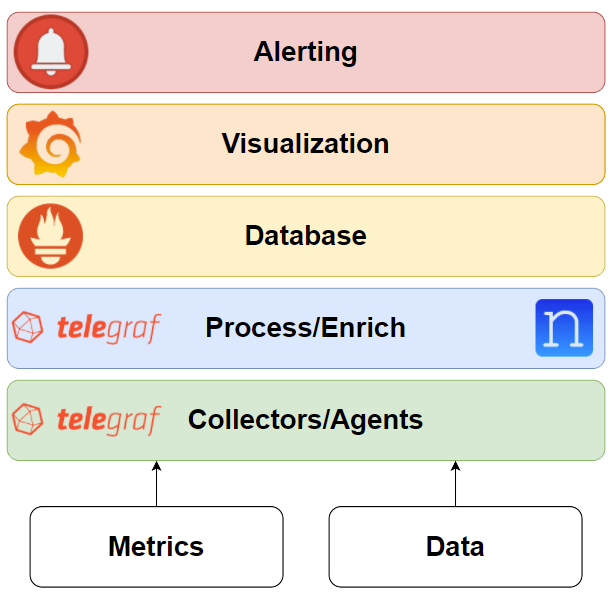
Have you ever run into the issue where different versions of software return different metric names like bgp_neighbor versus bgp-neighbor? What about metrics that don’t quite have all the data you’d like? This is where processing can help solve a lot of headaches by allowing you to normalize and enrich the metrics before passing them into your database.
Normalizing Data
One of the toughest situations to work with in telemetry is that almost every vendor is different. This means that sometimes your BGP metrics can come in with different labels or fields, which can introduce all kinds of trouble when trying to sort them in graphs or alerting. Normalizing the data allows you to adjust different fields and labels to either tune them to your environment, or to enforce naming standards.
Enriching Data
Enriching data can be very powerful and can take your metrics to a whole new level. Sure, some vendors do an amazing job at returning all the data you need, but what about the data that they can’t provide? With data enrichment you can add labels or fields to your metrics to track things like site location, rack location, customer IDs, and even SLA information for tenants.
NOTE:
Prometheus uses labels to determine the uniqueness of a metric. If you change the label of an existing metric, you may lose graph history in Grafana. You would need to update your query to pull for both the old and new labels so that they are combined.
Normalizing Data Using Telegraf
Using our scenario from above, let’s normalize some BGP data and modify a few metric fields to make sure they match and are standard across the board.
[[processors.rename]]
# ---------------------------------------------------
# Normalize BGP Data
# ---------------------------------------------------
[[processors.rename]]
order = 1
namepass = ["bgp*"]
[[processors.rename.replace]]
field = "installed"
dest = "prefixes_installed"
[[processors.rename.replace]]
field = "sent"
dest = "prefixes_sent"
[[processors.rename.replace]]
field = "received"
dest = "prefixes_received"
It looks like a bit of a mess at first; but if you look closely, it’s pretty straightforward. [[processors.rename]]
orderallows us to set the order in which processors are executed. It’s not required; but if you don’t specify, the order will be random.namepassis an array of glob pattern strings. Only measurements’ names that match this pattern will be emitted.
With a simple processor like this, we are able to catch any BGP fields that come in as installed and transform them into prefixes_installed to ensure they match our metrics pulled from other agents.
- bgp_neighbor{installed="100", sent="100", received="150", neighbor="10.17.17.1"} 1
+ bgp_neighbor{prefixes_installed="100", prefixes_sent="100", prefixes_received="150", neighbor="10.17.17.1"} 1
[[processors.enum]]
Another powerful processor in Telegraf is enum. The enum processor allows the configuration of value mappings for field or tag values. The main use for this is for creating a mapping between strings and integers.
# ---------------------------------------------------
# Normalize status codes
# ---------------------------------------------------
[[processors.enum]]
order = 3
namepass = ["storage"]
[[processors.enum.mapping]]
tag = "status"
[processors.enum.mapping.value_mappings]
1 = "READ_ONLY"
2 = "RUN_FROM_FLASH"
3 = "READ_WRITE"
With this enum config, all storage metrics will have their status tag updated so that the end result is no longer a number and is easier to read.
- storage{type="scsi", status="1", host="server01"} 1500000
+ storage{type="scsi", status="READ_ONLY", host="server01"} 1500000
Sometimes even simple normalizations can save you from some of those dreaded late-night calls from your NOC. Changing a field into a more user-friendly field will prevent a lot of headaches during outages as well.
Enriching Data Using Telegraf
When it comes to enrichment you can either perform a what we call a static enrichment or a dynamic enrichment. Static enrichment is based on the Telegraf configuration file which means it is valid during the lifecycle of the configuration. Sometimes we like flexibility and not have a dependency on configuration or Telegraf deployments which is where dynamic enrichment comes in.
Static Enrichment
Telegraf has a lot of processors for enrichment but we will focus on the regex plugin. This plugin allows you to match a particular pattern for creating static labels and values.
[[processors.regex]]
order = 3
namepass = ["interface_admin_status"]
[processors.regex.tagpass]
device = ["ceos-01"]
[[processors.regex.tags]]
key = "interface"
pattern = "^Management1$"
replacement = "mgmt"
result_key = "intf_role"
- interface_admin_status{device="ceos-01", interface="Management1"} 1
+ interface_admin_status{device="ceos-01", interface="Management1", intf_role="mgmt"} 1
This is great, but wouldn’t it be better if this label could be updated with a change inside Nautobot? Well, this is where dynamic enrichment comes in.
Dynamic Enrichment
With dynamic enrichment we can take it a step further by pulling values from a single source of truth like Nautobot. In the next example I will be giving you a glance into an upcoming project that’s still currently in work but hopefully will be released soon so keep a lookout for the blog post!
Let me give you a sneak peek into network-agent. The network-agent project is built as a ‘batteries included’ Telegraf/Python-based container targeted for network metrics consumption and processing. The network-agent container comes with a lot of features, but for now we will only focus on the Nautobot processor.
Key features of this processor:
- GraphQL-based queries to Nautobot for simplicity and speed.
- JMESPath query for easy data extraction.
- LRU caching to reduce API calls for metric enrichment.
NOTE:
The default cache TTL is set to 120 seconds. This means that the cache will remain valid until this timer has passed. After that, another GraphQL query to Nautobot is sent to check for new interfaces and roles.
This is what the configuration can look like:
[nautobot]
# Nautobot URL and Token specified using environment variables
graphql_query = """
query ($device: [String!]) {
devices(name: $device) {
name
interfaces(tag: "intf_pri__tier1") {
name
cf_role
tags {
name
}
}
}
}
"""
[enrich.interface.tag_pass]
device = 'ceos-*'
name = "interface*"
[enrich.interface.extract] # JMESPATH
interface_role = "devices[0].interfaces[?name==''].cf_role | [0]"
With this processor, we are able to query Nautobot for devices and filter the results to only interfaces with a intf_pri__tier1 tag. The information is then cached and can be used during the enrichment process.
[enrich.interface.tag_pass]
With the device and name options, we are able to control which specific metrics will get enriched with our new label.
[enrich.interface.extract]
This is where we define our new label that will get added to the metrics and the JMESPath query to grab our value. In this case, we will be taking the custom field called role out of Nautobot and adding it to all our interface metrics for our ceos devices.
- interface_admin_status{device="ceos-01", interface="Ethernet1"} 1
+ interface_admin_status{device="ceos-01", interface="Ethernet1", interface_role="border"} 1
Conclusion
Metric labels can be extremely powerful for both troubleshooting global infrastructure and capacity planning for companies. Whether you are using enrichment to add customer_id to BGP metrics or using normalization to remove those pesky special characters from your interface descriptions, telemetry can do it all.
-Donnie
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!