

In this post we’ll review one of the most widely used Python modules for interacting with web-based services such as REST APIs, the Python requests module. If you were ever wondering what magic is going on behind the scenes when running one of the thousands of Ansible networking modules, or many of the Python-based SDKs that are available from vendors, there’s a good chance the underlying operations are being performed by requests. The Python requests module is a utility that emulates the operations of a web browser using code. It enables programs to interact with a web-based service across the network, while abstracting and handling the lower-level details of opening up a TCP connection to the remote system. Like a web browser, the requests module allows you to programmatically:
- Initiate HTTP requests such as GET, PUT, POST, PATCH, and DELETE
- Set HTTP headers to be used in the outgoing request
- Store and access the web server content in various forms (HTML, XML, JSON, etc.)
- Store and access cookies
- Utilize either HTTP or HTTPS
Retrieving Data
The most basic example of using requests is simply retrieving the contents of a web page using an HTTP GET:
import requests
response = requests.get('https://google.com')
The resulting response object will contain the actual HTML code that would be seen by a browser in the text object, which can be accessed by typing response.text.
>>> response.text
'<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="en"><head><meta content="Search the world\'s information, including webpages, images, videos and more. Google has many special features to help you find exactly what you\'re looking for." name="description"><meta content="noodp" name="robots"><meta content="text/html; charset=UTF-8" http-equiv="Content-Type">
-- output omitted for brevity --
There are a lot of great utilities for parsing HTML, but in most cases we will not be doing that when working with networking vendor APIs. In the majority of cases, the data will come back structured as XML or JSON.
response = requests.get('https://nautobot.demo.networktocode.com/api')
>>> response.content
b'{"circuits":"https://nautobot.demo.networktocode.com/api/circuits/","dcim":"https://nautobot.demo.networktocode.com/api/dcim/","extras":"https://nautobot.demo.networktocode.com/api/extras/","graphql":"https://nautobot.demo.networktocode.com/api/graphql/","ipam":"https://nautobot.demo.networktocode.com/api/ipam/","plugins":"https://nautobot.demo.networktocode.com/api/plugins/","status":"https://nautobot.demo.networktocode.com/api/status/","tenancy":"https://nautobot.demo.networktocode.com/api/tenancy/","users":"https://nautobot.demo.networktocode.com/api/users/","virtualization":"https://nautobot.demo.networktocode.com/api/virtualization/"}'
Notice that the above output is in bytes format. This is indicated by the lowercase “b” in front of the response text. We could convert this into a string using response.content.decode() and then use the Python json module to load it into a Python dictionary. However, because json is one of the most common data formats, the requests module has a convenience method that will automatically convert the response from bytes to a Python dictionary. Simply call response.json():
>>> response.json()
{'circuits': 'https://nautobot.demo.networktocode.com/api/circuits/', 'dcim': 'https://nautobot.demo.networktocode.com/api/dcim/', 'extras': 'https://nautobot.demo.networktocode.com/api/extras/', 'graphql': 'https://nautobot.demo.networktocode.com/api/graphql/', 'ipam': 'https://nautobot.demo.networktocode.com/api/ipam/', 'plugins': 'https://nautobot.demo.networktocode.com/api/plugins/', 'status': 'https://nautobot.demo.networktocode.com/api/status/', 'tenancy': 'https://nautobot.demo.networktocode.com/api/tenancy/', 'users': 'https://nautobot.demo.networktocode.com/api/users/', 'virtualization': 'https://nautobot.demo.networktocode.com/api/virtualization/'}
>>> type(response.json())
<class 'dict'>
In some cases, we will have to specify the desired data format by setting the Accept header. For example:
headers = {'Accept': 'application/json'}
response = requests.get('https://nautobot.demo.networktocode.com/api', headers=headers)
In this example, we are informing the API that we would like the data to come back formatted as JSON. If the API provides the content as XML, we would specify the header as {'Accept': 'application/xml'}. The appropriate content type to request should be spelled out in the vendor API documentation. Many APIs use a default, so you may not need to specify the header. Nautobot happens to use a default of application/json, so it isn’t necessary to set the header. If you do not set the Accept header, you can find out the type of returned content by examining the Content-Type header in the response:
>>> response.headers['Content-Type']
'application/json'
Although we are using Nautobot for many of the examples of
requestsmodule usage, there is a very useful SDK called pynautobot that can handle a lot of the heavy lifting for you, so definitely check that out!
Authentication
Most APIs are protected by an authentication mechanism which can vary from product to product. The API documentation is your best resource in determining the method of authentication in use. We’ll review a few of the more common methods with examples below.
API Key
With API key authentication you typically must first access an administrative portal and generate an API key. Think of the API key the same way as you would your administrative userid/password. In some cases it will provide read/write administrative access to the entire system, so you want to protect it as such. This means don’t store it in the code or in a git repository where it can be seen in clear text. Commonly the API keys are stored as environment variables and imported at run time, or are imported from password vaults such as Hashicorp or Ansible vault. Once an API key is generated, it will need to be included in some way with all requests. Next we’ll describe a few common methods for including the API key in requests and provide example code.
Token in Authorization Header
One method that is used across a wide variety of APIs is to include the API key as a token in the Authorization header. A few examples of this are in the authentication methods for Nautobot and Cisco Webex. The two examples below are very similar, with the main difference being that Nautobot uses Token {token} in the Authorization header whereas Cisco Webex uses Bearer {token} in the Authorization header. Implementation of this is not standardized, so the API documentation should indicate what the format of the header should be.
Nautobot API
First, it is necessary to generate an API key from the Nautobot GUI. Sign into Nautobot and select your username in the upper right-hand corner, and then view your Profile. From the Profile view, select API Tokens and click the button to add a token. The token will then need to be specified in the Authorization header in all requests as shown below.
import requests
import os
# Get the API token from an environment variable
token = os.environ.get('NAUTOBOT_TOKEN')
# Add the Authorization header
headers = {'Authorization': f'Token {token}'}
# This is the base URL for all Nautobot API calls
base_url = 'https://nautobot.demo.networktocode.com/api'
# Get the list of devices from Nautobot using the requests module and passing in the authorization header defined above
response = requests.get('https://nautobot.demo.networktocode.com/api/dcim/devices/', headers=headers)
>>> response.json()
{'count': 511, 'next': 'https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=50', 'previous': None, 'results': [{'id': 'fd94038c-f09f-4389-a51b-ffa03e798676', 'url': 'https://nautobot.demo.networktocode.com/api/dcim/devices/fd94038c-f09f-4389-a51b-ffa03e798676/', 'name': 'ams01-edge-01', 'device_type': {'id': '774f7008-3a75-46a2-bc75-542205574cee', 'url': 'https://nautobot.demo.networktocode.com/api/dcim/device-types/774f7008-3a75-46a2-bc75-542205574cee/', 'manufacturer': {'id': 'e83e2d58-73e2-468b-8a86-0530dbf3dff9', 'url': 'https://nautobot.demo.networktocode.com/api/dcim/manufacturers/e83e2d58-73e2-468b-8a86-0530dbf3dff9/', 'name': 'Arista', 'slug': 'arista', 'display': 'Arista'}, 'model': 'DCS-7280CR2-60', 'slug': 'dcs-7280cr2-60', 'display': 'Arista DCS-7280CR2-60'}, 'device_role': {'id': 'bea7cc02-e254-4b7d-b871-6438d1aacb76', 'url': 'https://nautobot.demo.networktocode.com/api/dcim/device-roles/bea7cc02-e254-4b7d-b871-6438d1aacb76/'
--- OUTPUT TRUNCATED FOR BREVITY ---
Cisco Webex API
When working with the Webex API, a bot must be created to get an API key. First create a bot in the dashboard https://developer.webex.com/docs/. Upon creating the bot you are provided a token which is good for 100 years. The token should then be included in the Authorization header in all requests as shown below.
import requests
import os
# Get the API token from an environment variable
token = os.environ.get('WEBEX_TOKEN')
# Add the Authorization header
headers = {'Authorization': f'Bearer {token}'}
# This is the base URL for all Webex API calls
base_url = 'https://webexapis.com'
# Get list of rooms
response = requests.get(f'{base_url}/v1/rooms', headers=headers)
>>> response.json()
{'items': [{'id': 'Y2lzY29zcGFyazovL3VzL1JPT00vNjZlNmZjYTAtMjIxZS0xMWVjLTg2Y2YtMzk0NmQ2YTMzOWVi', 'title': 'nautobot-chatops', 'type': 'group', 'isLocked': False, 'lastActivity': '2021-10-22T19:37:38.091Z', 'creatorId': 'Y2lzY29zcGFyazovL3VzL1BFT1BMRS9iYmRiZDljNC1hMTRkLTQwMTYtYjVjZi1jOGExNzY0MWI1YWQ', 'created': '2021-09-30T18:44:11.242Z', 'ownerId': 'Y2lzY29zcGFyazovL3VzL09SR0FOSVpBVElPTi8zZjE3OTcwNi1mMTFhLTRhYjctYmEzZS01N2E0YTk2YjA4OWY'}, {'id': 'Y2lzY29zcGFyazovL3VzL1JPT00vNzBjZTgwYTAtMjIxMi0xMWVjLWEwMDAtZjcyZTAyM2Q2MDIx', 'title': 'Webex space for Matt', 'type': 'group', 'isLocked': False, 'lastActivity': '2021-09-30T17:18:33.898Z', 'creatorId': 'Y2lzY29zcGFyazovL3VzL1BFT1BMRS9iYmRiZDljNC1hMTRkLTQwMTYtYjVjZi1jOGExNzY0MWI1YWQ', 'created': '2021-09-30T17:18:33.898Z', 'ownerId': 'Y2lzY29zcGFyazovL3VzL09SR0FOSVpBVElPTi8zZjE3OTcwNi1mMTFhLTRhYjctYmEzZS01N2E0YTk2YjA4OWY'}, {'id': 'Y2lzY29zcGFyazovL3VzL1JPT00vOWIwN2FmMjYtYmQ4Ny0zYmYwLWI2YzQtNTdlNmY1OGQwN2E2', 'title': 'Jason Belk', 'type': 'direct', 'isLocked': False, 'lastActivity': '2021-01-26T19:53:01.306Z', 'creatorId': 'Y2lzY29zcGFyazovL3VzL1BFT1BMRS9jNzg2YjVmOC1hZTdjLTQyMzItYjRiNS1jNzQxYTU3MjU4MzQ', 'created': '2020-12-10T17:53:01.202Z'}, {'id': 'Y2lzY29zcGFyazovL3VzL1JPT00vNTYwNzhhNTAtMTNjMi0xMWViLWJiNjctMTNiODIxYWUyMjE1', 'title': 'NTC NSO Projects', 'type': 'group', 'isLocked': False, 'lastActivity': '2021-05-28T17:46:16.727Z', 'creatorId': 'Y2lzY29zcGFyazovL3VzL1BFT1BMR
--- OUTPUT TRUNCATED FOR BREVITY ---
Custom Token Header
Some APIs require that the API key be provided in a custom header that is included with all requests. The key and the format to use for the value should be spelled out in the API documentation.
Cisco Meraki
Cisco Meraki requires that all requests have an X-Cisco-Meraki-API-Key header with the API key as the value. As with the Token in Authorization Header method discussed previously, you must first go to the API dashboard and generate an API key. This is done in the Meraki Dashboard under your profile settings. The key should then be specified in the X-Cisco-Meraki-API-Key for all requests.
import requests
import os
# Get the API key from an environment variable
api_key = os.environment.get('MERAKI_API_KEY')
# The base URI for all requests
base_uri = "https://api.meraki.com/api/v0"
# Set the custom header to include the API key
headers = {'X-Cisco-Meraki-API-Key': api_key}
# Get a list of organizations
response = requests.get(f'{base_uri}/organizations', headers=headers)
>>> response.json()
[{'id': '681155', 'name': 'DeLab', 'url': 'https://n392.meraki.com/o/49Gm_c/manage/organization/overview'}, {'id': '575334852396583536', 'name': 'TNF - The Network Factory', 'url': 'https://n22.meraki.com/o/K5Faybw/manage/organization/overview'}, {'id': '573083052582914605', 'name': 'Jacks_test_net', 'url': 'https://n18.meraki.com/o/22Uqhas/manage/organization/overview'}, {'id': '549236', 'name': 'DevNet Sandbox', 'url': 'https://n149.meraki.com/o/-t35Mb/manage/organization/overview'}, {'id': '575334852396583264', 'name': 'My organization', 'url': 'https://n22.meraki.com/o/
--- OUTPUT TRUNCATED FOR BREVITY ---
HTTP Basic Authentication w/ Token
Some APIs require that you first issue an HTTP POST to a login url using HTTP Basic Authentication. A token that must be used on subsequent requests is then issued in the response. This type of authentication does not require going to an administrative portal first to generate the token; the token is automatically generated upon successful login.
HTTP Basic Authentication/Token – Cisco DNA Center
The Cisco DNA Center login process requires that a request first be sent to a login URL with HTTP Basic Authentication, and upon successful authentication issues a token in the response. The token must then be sent in an X-Auth-Token header in subsequent requests.
import requests
from requests.auth import HTTPBasicAuth
import os
username = os.environ.get('DNA_USERNAME')
password = os.environ.get('DNA_PASSWORD')
hostname = 'sandboxdnac2.cisco.com'
# Create an HTTPBasicAuth object that will be passed to requests
auth = HTTPBasicAuth(username, password)
# Define the login URL to get the token
login_url = f"https://{hostname}/dna/system/api/v1/auth/token"
# Issue a login request
response = requests.post(login_url, auth=auth)
# Parse the token from the response if the response was OK
if response.ok:
token = response.json()['Token']
else:
print(f'HTTP Error {response.status_code}:{response.reason} occurred')
# Define the X-Auth-Token header to be used in subsequent requests
headers = {'X-Auth-Token': token}
# Define the url for getting network health information from DNA Center
url = f"https://{hostname}/dna/intent/api/v1/network-health"
# Retrieve network health information from DNA Center
response = requests.get(url, headers=headers, auth=auth)
>>> response.json()
{'version': '1.0', 'response': [{'time': '2021-10-22T19:40:00.000+0000', 'healthScore': 100, 'totalCount': 14, 'goodCount': 14, 'unmonCount': 0, 'fairCount': 0, 'badCount': 0, 'entity': None, 'timeinMillis': 1634931600000}], 'measuredBy': 'global', 'latestMeasuredByEntity': None, 'latestHealthScore': 100, 'monitoredDevices': 14, 'monitoredHealthyDevices': 14, 'monitoredUnHealthyDevices': 0, 'unMonitoredDevices': 0, 'healthDistirubution': [{'category': 'Access', 'totalCount': 2, 'healthScore': 100, 'goodPercentage': 100, 'badPercentage': 0, 'fairPercentage': 0, 'unmonPercentage': 0, 'goodCount': 2, 'badCount': 0, 'fairCount': 0, 'unmonCount': 0}, {'category': 'Distribution', 'totalCount': 1, 'healthScore': 100, 'good
--- OUTPUT TRUNCATED FOR BREVITY ---
POST with JSON Payload
With this method of authentication, the user must first issue a POST to a login URL and include a JSON (most common), XML, or other type of payload that contains the user credentials. A token that must be used with subsequent API requests is then returned. In some cases the token is returned as a cookie in the response. When that is the case, a shortcut is to use a requests.session object. By using a session object, the token in the cookie can easily be reused on subsequent requests by sourcing the requests from the session object. This is the strategy used in the Cisco ACI example below.
POST with JSON Payload – Cisco ACI
Cisco ACI requires a JSON payload to be posted to the /aaaLogin URL endpoint with the username/password included. The response includes a cookie with key APIC-cookie and a token in the value that can be used on subsequent requests.
import requests
import os
username = os.environ.get('USERNAME')
password = os.environ.get('PASSWORD')
hostname = 'sandboxapicdc.cisco.com'
# Build the JSON payload with userid/password
payload = {"aaaUser": {"attributes": {"name": username, "pwd" : password }}}
# Create a Session object
session = requests.session()
# Specify the login URL
login_url = f'https://{hostname}/api/aaaLogin.json'
# Issue the login request. The cookie will be stored in session.cookies.
response = session.post(login_url, json=payload, verify=False)
# Use the session object to get ACI tenants
if response.ok:
response = session.get(f'https://{hostname}/api/node/class/fvTenant.json', verify=False)
else:
print(f"HTTP Error {response.status_code}:{response.reason} occurred.")
>>> response.json()
{'totalCount': '4', 'imdata': [{'fvTenant': {'attributes': {'annotation': '', 'childAction': '', 'descr': '', 'dn': 'uni/tn-common', 'extMngdBy': '', 'lcOwn': 'local', 'modTs': '2021-10-08T15:31:47.480+00:00', 'monPolDn': 'uni/tn-common/monepg-default', 'name': 'common', 'nameAlias': '', 'ownerKey': '', 'ownerTag': '', 'status': '', 'uid': '0', 'userdom': 'all'}}}, {'fvTenant': {'attributes': {'annotation': '', 'childAction': '', 'descr': '', 'dn': 'uni/tn-infra', 'extMngdBy': '', 'lcOwn': 'local', 'modTs': '2021-10-08T15:31:55.077+00:00', 'monPolDn': 'uni/tn-common/monepg-default', 'name': 'infra', 'nameAlias': '', 'ownerKey': '', 'ownerTag': '', 'status': '', 'uid': '0', 'userdom': 'all'}}},
--- OUTPUT TRUNCATED FOR BREVITY ---
Certificate Checking
Note the verify=False in the above example. This can be used to turn off certificate checking when the device or API you are targeting is using a self-signed or invalid SSL certificate. This will cause a log message similar to the following to be generated:
InsecureRequestWarning: Unverified HTTPS request is being made to host ‘sandboxapicdc.cisco.com’. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings`
The solution that should be used for a production deployment would be to install a valid SSL certificate, and don’t use verify=False. However, if you are dealing with lab devices that may never have a valid certificate then the message can be disabled using the following snippet:
import urllib3
urllib3.disable_warnings()
Handling Errors
It is helpful when working with requests to understand HTTP status codes and some of the common triggers for them when working with APIs. HTTP status codes indicate the success or failure of a request, and when errors occur, can give a hint toward what the problem might be. Here are some common HTTP status codes that you might see when working with APIs and potential causes:
200 OK: The request was successful
201 Created: Indicates a POST or PUT request was successful
204 Deleted: Indicates a successful DELETE request
400 Bad Request: Usually indicates there was a problem with the payload in the case of a POST, PUT, or PATCH request
401 Unauthorized: Invalid or missing credentials
403 Forbidden: An authenticated user does not have permission to the requested resource
404 Not Found: The URL was not recognized
429 Too Many Requests: The API may have rate limiting in effect. Check the API docs to see if there is a limit on number of requests per second or per minute.
500 Internal Server Error: The server encountered an error processing your request. Like a 400, this can also be caused by a bad payload on a POST, PUT or PATCH.
When the requests module receives the above status codes in the response, it returns a response object and populates the status_code and reason fields in the response object. If a connectivity error occurs, such as a hostname that is unreachable or unresolvable, requests will throw an exception. However, requests will not throw an exception by default for HTTP-based errors such as the 4XX and 5XX errors above. Instead it will return the failure status code and reason in the response. A common strategy in error handling is to use the raise_for_status() method of the response object to also throw an exception for HTTP-based errors as well. Then a Python try/except block can be used to catch any of the errors and provide a more human-friendly error message to the user, if desired.
Note that HTTP status codes in the 2XX range indicate success, and thus
raise_for_status()will not raise an exception.
# Example of error for which Requests would throw an exception
# Define a purposely bad URL
url = 'https://badhostname'
# Implement a try/except block to handle the error
try:
response = requests.get(url, json=data)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Error while connecting to {url}: {e}")
Error while connecting to https://badhostname: HTTPSConnectionPool(host='badhostname', port=443): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x108890d60>: Failed to establish a new connection: [Errno 8] nodename nor servname provided, or not known'))
# Example of HTTP error, no exception thrown but we force one to be triggered with raise_for_status()
# Define a purposely bad URL
url = 'https://nautobot.demo.networktocode.com/api/dcim/regions/bogus'
# Get the API token from an environment variable.
token = os.environ.get('NAUTOBOT_TOKEN')
# Add the Authorization header
headers = {'Authorization': f'Token {token}'}
# Implement a try/except block to handle the error
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Error while connecting to {url}: {e}")
Error while connecting to https://nautobot.demo.networktocode.com/api/dcim/regions/bogus: 404 Client Error: Not Found for url: https://nautobot.demo.networktocode.com/api/dcim/regions/bogus/
CRUD (Create, Replace, Update, Delete) API Objects
So far we have mostly discussed retrieving data from an API using HTTP GET requests. When creating/updating objects, HTTP POST, PUT, and PATCH are used. A DELETE request would be used to remove objects from the API.
- POST: Used when creating a new object
- PATCH: Update an attribute of an object
- PUT: Replaces an object with a new one
- DELETE: Delete an object
It should be noted that some APIs support both PUT and PATCH, while some others may support only PUT or only PATCH. The Meraki API that we’ll be using for the following example supports only PUT requests to change objects.
POST
When using a POST request with an API, you typically must send a payload along with the request in the format required by the API (usually JSON, sometimes XML, very rarely something else). The format needed for the payload should be documented in the API specification. When using JSON format, you can specify the json argument when making the call to requests.post. For example, requests.post(url, headers=headers, json=payload). Other types of payloads such as XML would use the data argument. For example, requests.post(url, headers=headers, data=payload).
Create a Region in Nautobot
With Nautobot, we can determine the required payload by looking at the Swagger docs that are on the system itself at /api/docs/. Let’s take a look at the Swagger spec to create a Region in Nautobot.
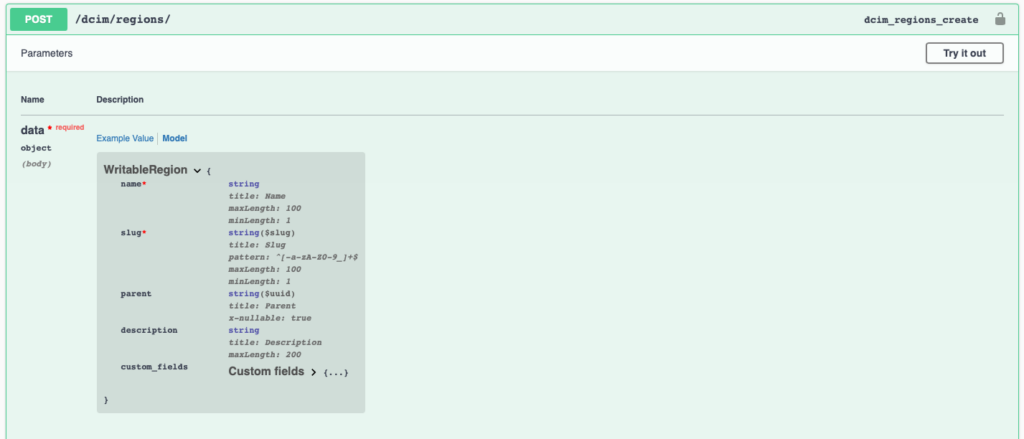
The fields marked with a red * above indicate that they are required fields, the other fields are optional. If we click the Try it out button as shown above, it gives us an example payload.
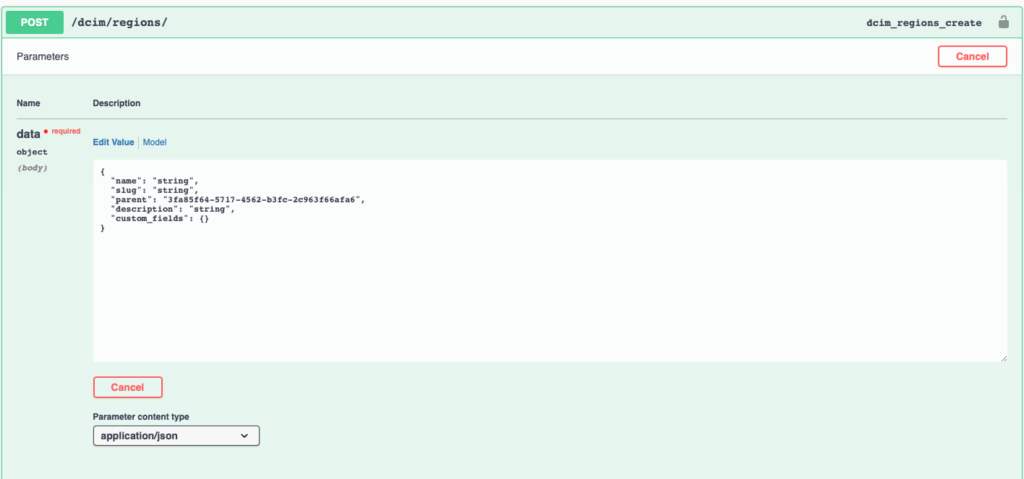
Since the name and slug are the only required fields, we can form a payload from the example omitting the other fields if desired. The below code snippet shows how we can create the Region in Nautobot using requests.post.
import requests
import os
# Get the API token from an environment variable.
token = os.environ.get('NAUTOBOT_TOKEN')
# Add the Authorization header
headers = {'Authorization': f'Token {token}'}
# This is the base URL for all Nautobot API calls
base_url = 'https://nautobot.demo.networktocode.com/api'
# Form the payload for the request, per the API specification
payload = {
"name": "Asia Pacific",
"slug": "asia-pac",
}
# Create the region in Nautobot
response = requests.post('https://nautobot.demo.networktocode.com/api/dcim/regions/', headers=headers, json=payload)
>>> response
<Response [201]>
>>> response.reason
'Created'
PATCH
A PATCH request can be used to update an attribute of an object. For example, in this next snippet we will change the description of the Region we just created in the POST request. It was omitted in the previous POST request so it is currently a blank string. Although it is not called out in the Swagger API specification, the PATCH request for Nautobot requires the id field to be defined in the payload. The id can be looked up for our previously created Region by doing a requests.get on /regions?slug=asia-pac. The ?slug=asia-pac at the end of the URL is a query parameter that is used to filter the request for objects having a field matching a specific value. In this case, we filtered the objects for the one with the slug field set to asia-pac to grab the ID. In addition, the payload needs to be in the form of a list of dictionaries rather than a single dictionary as is shown in the Swagger example.
Update a Region Description in Nautobot
import requests
import os
# Get the API token from an environment variable.
token = os.environ.get('NAUTOBOT_TOKEN')
# Add the Authorization header
headers = {'Authorization': f'Token {token}'}
# This is the base URL for all Nautobot API calls
base_url = 'https://nautobot.demo.networktocode.com/api'
# First we get the region_id from our previously created region
response = requests.get('https://nautobot.demo.networktocode.com/api/dcim/regions/?slug=asia-pac', headers=headers)
>>> response.json()
{'count': 1, 'next': None, 'previous': None, 'results': [{'id': 'be2c22a2-56ce-4d84-8ac9-5a68c6a39d62', 'url': 'https://nautobot.demo.networktocode.com/api/dcim/regions/be2c22a2-56ce-4d84-8ac9-5a68c6a39d62/', 'name': 'Asia Pacific', 'slug': 'asia-pac', 'parent': None, 'description': 'Test region created from the API!', 'site_count': 0, '_depth': 0, 'custom_fields': {}, 'created': '2021-10-22', 'last_updated': '2021-10-22T21:20:07.628690', 'display': 'Asia Pacific'}]}
# Parse the above response for the region identifier
region_id = response.json()['results'][0]['id']
# Form the payload for the request, per the API specification (see preceding paragraph for some nuances!)
payload = [{
"name": "Asia Pacific",
"slug": "asia-pac",
"description": "Test region created from the API!",
"id": region_id
}]
# Update the region in Nautobot
response = requests.patch('https://nautobot.demo.networktocode.com/api/dcim/regions/', headers=headers, json=payload)
>>> response
<Response [200]>
PUT
A PUT request is typically used to replace an an entire object including all attributes of the object.
Replace a Region Object in Nautobot
Let’s say we want to replace the entire Region object that we created previously, giving it a completely new name, slug and description. For this we can use a PUT request, specifying the id of the previously created Region and providing new values for the name, slug, and description attributes.
import requests
import os
# Get the API token from an environment variable
token = os.environ.get('NAUTOBOT_TOKEN')
# Add the Authorization header
headers = {'Authorization': f'Token {token}'}
# This is the base URL for all Nautobot API calls
base_url = 'https://nautobot.demo.networktocode.com/api'
# First we get the region_id from our previously created region
response = requests.get('https://nautobot.demo.networktocode.com/api/dcim/regions/?slug=asia-pac', headers=headers)
>>> response.json()
{'count': 1, 'next': None, 'previous': None, 'results': [{'id': 'be2c22a2-56ce-4d84-8ac9-5a68c6a39d62', 'url': 'https://nautobot.demo.networktocode.com/api/dcim/regions/be2c22a2-56ce-4d84-8ac9-5a68c6a39d62/', 'name': 'Asia Pacific', 'slug': 'asia-pac', 'parent': None, 'description': 'Test region created from the API!', 'site_count': 0, '_depth': 0, 'custom_fields': {}, 'created': '2021-10-22', 'last_updated': '2021-10-22T21:20:07.628690', 'display': 'Asia Pacific'}]}
# Parse the above response for the region identifier
region_id = response.json()['results'][0]['id']
# Form the payload for the request, per the API specification (see preceding paragraph for some nuances!)
payload = [{
"name": "Test Region",
"slug": "test-region-1",
"description": "Asia Pac region updated with a PUT request!",
"id": region_id
}]
# Update the region in Nautobot
response = requests.put('https://nautobot.demo.networktocode.com/api/dcim/regions/', headers=headers, json=payload)
>>> response
<Response [200]>
# Search for the region using the new slug
response = requests.get('https://nautobot.demo.networktocode.com/api/dcim/regions/?slug=test-region-1', headers=headers)
# This returns the replaced object, while retaining the same identifier
>>> response.json()
{'count': 1, 'next': None, 'previous': None, 'results': [{'id': 'be2c22a2-56ce-4d84-8ac9-5a68c6a39d62', 'url': 'https://nautobot.demo.networktocode.com/api/dcim/regions/be2c22a2-56ce-4d84-8ac9-5a68c6a39d62/', 'name': 'Test Region', 'slug': 'test-region-1', 'parent': None, 'description': 'Asia Pac region updated with a PUT request!', 'site_count': 0, '_depth': 0, 'custom_fields': {}, 'created': '2021-10-22', 'last_updated': '2021-10-25T17:31:04.003235', 'display': 'Test Region'}]}
Enable an SSID in Meraki
Let’s look at another example of using a PUT to enable a wireless SSID in the Cisco Meraki dashboard. For this we will use a PUT request including the appropriate JSON payload to enable SSID 14.
import requests
import os
# Get the API key from an environment variable
api_key = os.environment.get('MERAKI_API_KEY')
# The base URI for all requests
base_uri = "https://api.meraki.com/api/v0"
# Set the custom header to include the API key
headers = {'X-Cisco-Meraki-API-Key': api_key}
net_id = 'DNENT2-mxxxxxdgmail.com'
ssid_number = 14
url = f'{base_uri}/networks/{net_id}/ssids/{ssid_number}'
# Initiate the PUT request to enable an SSID. You must have a reservation in the Always-On DevNet sandbox to gain authorization for this.
response = requests.put(url, headers=headers, json={"enabled": True})
DELETE
An object can be removed by making a DELETE request to the URI (Universal Resource Indicator) of an object. The URI is the portion of the URL that refers to the object, for example /dcim/regions/{id} in the case of the Nautobot Region.
Remove a Region from Nautobot
Let’s go ahead and remove the Region that we previously added. To do that, we’ll send a DELETE request to the URI of the region. The URI can be seen when doing a GET request in the url attribute of the Region object. We can also see in the API specification for DELETE that the call should be made to /regions/{id}
# Search for the region using the slug
response = requests.get('https://nautobot.demo.networktocode.com/api/dcim/regions/?slug=test-region-1', headers=headers)
# Parse the URL from the GET request
url = response.json()['results'][0]['url']
>>> url
'https://nautobot.demo.networktocode.com/api/dcim/regions/be2c22a2-56ce-4d84-8ac9-5a68c6a39d62/'
# Delete the Region object
response = requests.delete(url, headers=headers)
# A status code of 204 indicates successful deletion
>>> response
<Response [204]>
Rate Limiting
Some APIs implement a throttling mechanism to prevent the system from being overwhelmed with requests. This is usually implemented as a rate limit of X number of requests per minute. When the rate limit is hit, the API returns a status code 429: Too Many Requests. To work around this, your code must implement a backoff timer in order to avoid hitting the threshold. Here’s an example working around the Cisco DNA Center rate limit of 5 requests per minute:
import requests
from requests.auth import HTTPBasicAuth
import time
from pprint import pprint
import os
# Pull in credentials from environment variables
username = os.environ.get('USERNAME')
password = os.environ.get('PASSWORD')
hostname = "sandboxdnac2.cisco.com"
headers = {"Content-Type": "application/json"}
# Use Basic Authentication
auth = HTTPBasicAuth(username, password)
# Request URL for the token
login_url = f"https://{hostname}/dna/system/api/v1/auth/token"
# Retrieve the token
resp = requests.post(login_url, headers=headers, auth=auth)
token = resp.json()['Token']
# Add the token to subsequent requests
headers['X-Auth-Token'] = token
url = f"https://{hostname}/dna/intent/api/v1/network-device"
resp = requests.get(url, headers=headers, auth=auth)
count = 0
# Loop over devices and get device by id
# Each time we reach five requests, pause for 60 seconds to avoid the rate limit
for i, device in enumerate(resp.json()['response']):
count += 1
device_count = len(resp.json()['response'])
print (f"REQUEST #{i+1}")
url = f"https://{hostname}/dna/intent/api/v1/network-device/{device['id']}"
response = requests.get(url, headers=headers, auth=auth)
pprint(response.json(), indent=2)
if count == 5 and (i+1) < device_count:
print("Sleeping for 60 seconds...")
time.sleep(60)
count = 0
Pagination
Some API calls may set a limit on the number of objects that are returned in a single call. In this case, the API should return paging details in the JSON body including the URL to request the next set of data as well as the previous set. If Previous is empty, we are on the first set of data. If Next is empty, we know we have reached the end of the dataset. Some API implementations follow RFC5988, which includes a Link header in the format:
The above example is from the Webex API, which implements RFC5988. This is described in the API documentation here: https://developer.webex.com/docs/api/basics
Keep in mind that not all implementations use the RFC, however. The API documentation should explain how pagination is handled.
Handling Pagination in Nautobot
A good example of pagination can be seen when making a GET request to retrieve all Devices from Nautobot. Nautobot includes a count, next, and previous attribute in responses that are paginated. By default, the API will return a maximum of 50 records. The limit value as well as an offset value are indicated in the next value of the response. For example: 'next': 'https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=50'. In the URL, the limit indicates the max amount of records, and the offset indicates where the next batch of records begins. The previous attribute indicates the url for the previous set of records. If previous is None, it means we are on the first set of records. And if next is None, it means we are on the last set of records.
In the below snippet, we first retrieve the first set of 50 records and store them in a device_list variable. We then create a while loop that iterates until the next field in the response contains None. The returned results are added to the device_list at each iteration of the loop. At the end we can see that there are 511 devices, which is the same value as the count field in the response.
import requests
import os
# Get the API token from an environment variable
token = os.environ.get('NAUTOBOT_TOKEN')
# Add the Authorization header
headers = {'Authorization': f'Token {token}'}
# This is the base URL for all Nautobot API calls
base_url = 'https://nautobot.demo.networktocode.com/api'
# Create the initial request for the first batch of records
response = requests.get(f'{base_url}/dcim/devices', headers=headers)
# Store the initial device list
device_list = [device for device in response.json()['results']]
# Notice that we now have the first 50 devices
>>> len(device_list)
50
# But there are 511 total!
>>> response.json()['count']
511
# Loop until 'next' is None, adding the retrieved devices to device_list on each iteration
if response.json()['next']:
while response.json()['next']:
print(f"Retrieving {response.json()['next']}")
response = requests.get(response.json()['next'], headers=headers)
for device in response.json()['results']:
device_list.append(device)
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=50
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=100
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=150
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=200
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=250
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=300
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=350
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=400
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=450
Retrieving https://nautobot.demo.networktocode.com/api/dcim/devices/?limit=50&offset=500
>>> len(device_list)
511
Handling Pagination in Cisco Webex
In the code below, first we get the Room IDs for the WebEx Teams rooms I am a member of. Then we retrieve the members from the DevNet Dev Support Questions room and create a continuous function that follows the Link URL and displays the content. The While loop is broken when the Link header is no longer present, returning None when we try to retrieve it with headers.get(‘Link’).
import requests
import re
import os
api_path = "https://webexapis.com/v1"
# You can retrieve your token here: https://developer.webex.com/docs/api/getting-started
token = os.environ.get('WEBEX_TOKEN')
headers = {"Authorization": f"Bearer {token}"}
# List the rooms, and collect the ID for the DevNet Support Questions room
get_rooms = requests.get(f"{api_path}/rooms", headers=headers)
for room in get_rooms.json()['items']:
print(room['title'], room['id'])
if room['title'] == "Sandbot-Support DevNet":
room_id = room['id']
# This function will follow the Link URLs until there are no more, printing out
# the member display name and next URL at each iteration. Note that I have decreased the maximum number of records to 1 so as to force pagination. This should not be done in a real implementation.
def get_members(room_id):
params = {"roomId": room_id, "max": 1}
# Make the initial request and print the member name
response = requests.get(f"{api_path}/memberships", headers=headers, params=params)
print(response.json()['items'][0]['personDisplayName'])
# Loop until the Link header is empty or not present
while response.headers.get('Link'):
# Get the URL from the Link header
next_url = response.links['next']['url']
print(f"NEXT: {next_url}")
# Request the next set of data
response = requests.get(next_url, headers=headers)
if response.headers.get('Link'):
print(response.json()['items'][0]['personDisplayName'])
else:
print('No Link header, finished!')
# Execute the function using the Sandbox-Support DevNet RoomID
get_members(room_id)
Conclusion
I hope this has been a useful tutorial on using requests to work with vendor REST APIs! While no two API implementations are the same, many of the most common patterns for working with them are covered here. As always, hit us up in the comments or on our public Slack channel with any questions. Thanks for reading!
-Matt
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!