
“I was asked to share the story of the Joint Communications Unit’s (JCU) automation journey, and I am happy to do that. I really enjoy telling the story and hope that we are able to help other elements in the DoD accomplish some of the things that we have within JCU. First, I would like to reference the JCU mission statement to describe what JCU is and what they are responsible for.”
The Joint Communications Unit (JCU) is a technical unit of the United States Special Operations Command charged to standardize and ensure interoperability of communication procedures and equipment of the Joint Special Operations Command and its subordinate units. The JCU was activated at Ft. Bragg, NC in 1980, after the failure of Operation Eagle Claw. The JCU has earned the reputation of “DoD’s Finest Communicators”.
There were two primary reasons why we sought out automation for JCU. The team I was a part of was responsible for ensuring network configurations were compliant and standard across a number of communication packages. The issue with the compliance and standardization process was the lack of defined compliance and standards. We did not have a versioncontrolled network configuration, and we had massive configuration drift on the network devices. We thrived on just making it work, which led at times, to hours of troubleshooting equipment. This process of att empting to baseline these communication packages took up to a week at a time, and at the end they just worked, and there was no standardization across the systems.
The second reason we sought automation was the creation of the Modular Family of Systems (MFS). This new suite of expeditionary communication packages was designed to replace all of the existing equipment JCU used for tactical communications. The initial configuration plan used many Excel spreadsheets as an IPAM solution for multiple enclaves (separate network classifications) and a Word document for each MFS Type (Lite, Medium, Heavy). Due to the modular nature and the requirement to support any possible scenario, the Word documents were approximately 27 pages long for some network enclaves and device types.
MFS is the suite of expeditionary communications packages that JCU needs to utilize in order to meet their communications requirements. The MFS suite consists of Lite, Medium, and Heavy variants that all provide the same capabilities from a configuration perspective, but support different numbers of users.
The components of the MFS suite include the Cisco ESR5915, ESR6300, CSR1000V, CSR8000V, and ESS3300. The components were designed to be modular in nature and able to be quickly swapped in and out using embedded event manager scripts to create dynamic connections between routers. My team had to configure and field a large number of these systems very quickly and guarantee that they would work.
After building that first batch manually and going through the painful process of populating a Word document with the correct hostnames, subnets, IPs, etc. that make up the host variables of a specific device, and encountering many fat-finger mistakes, we quickly realized we needed to come up with a better process. It took us over three weeks to configure and test the first set of equipment.
A combination of Ansible, GitLab and Jinja2 became our solution to provide a standardized, configured and working device. We took the Word documents of network configurations and separated the different sections into many Jinja2 templates and added a bunch of logic to meet the needs of each MFS type.
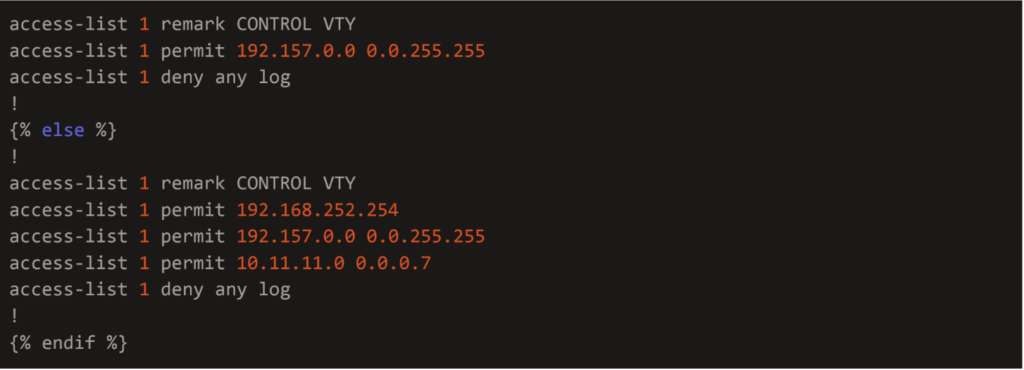
IP management and host variables were moved to YAML files for each kit, which contained the variables and IP assignments for each kit type.
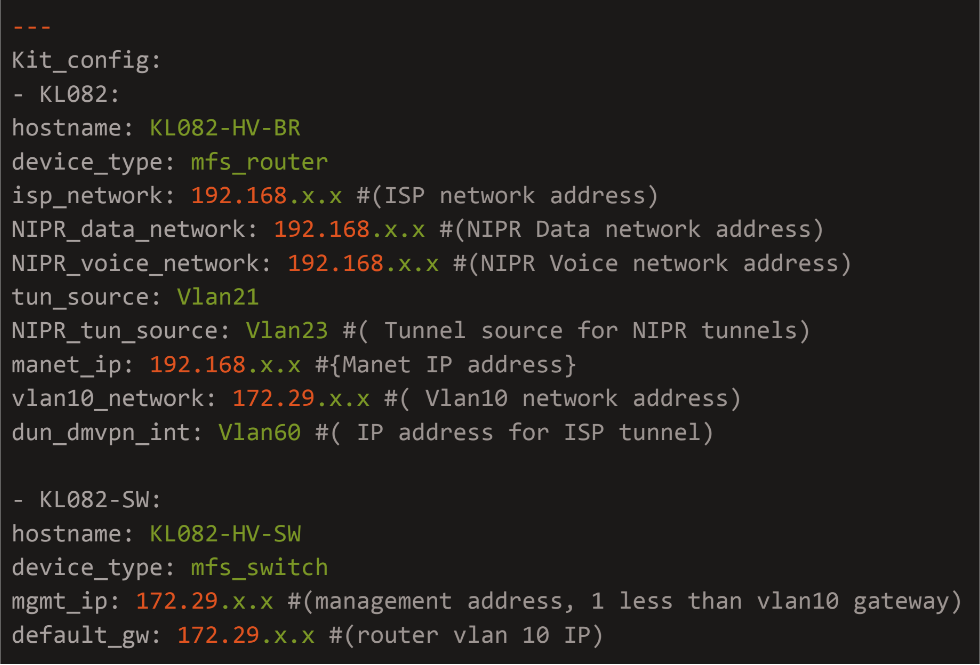
A static host file using the ini format was created to manage the connection variables and define host type and primary IP of each device.
The automation provided the solution we were looking for and allowed us to begin configuring and fielding MFS packages. Once the initial concept had been fleshed out and tested, we moved the Ansible playbooks and GitLab project to AWX in order to provide a user interface to request network configurations for our users.
We knew early on that using a static inventory and individual YAML files for host variables was never going to scale for us. It was very annoying to add or make a change to the inventory or YAML files. A branch needed to be created followed by a merge request before AWX could sync the project and finally create and deliver a config to a network device. If a mistake was made, this process would have to be repeated and take even longer. We wanted a smooth, quick, and streamlined process for adding and making changes to devices that would have an immediate effect when generating configurations.
After a lot of searching we found that a network source of truth (SOT) could solve both of the issues we were having with our inventory and our host variables. We currently use Nautobot as our network source of truth. Nautobot had a number of features that we thought could help us make fast and scalable changes to our inventories like config context and graphQL. Additionally the support from the Network to Code Slack channel and optional training available were very helpful for us.
We did some initial tests using Nautobot API calls for device objects and config context for group variables that did not scale for us; and as our device count grew, our inventory got increasingly slower. We found that we were pulling too much information from Nautobot. We decided to make some changes to our group variable structure and moved to using graphQL. We found that using graphQL to query the exact information we needed from Nautobot to generate a config, reduced our inventory runtime from approximately 5 minutes to under 10 seconds.
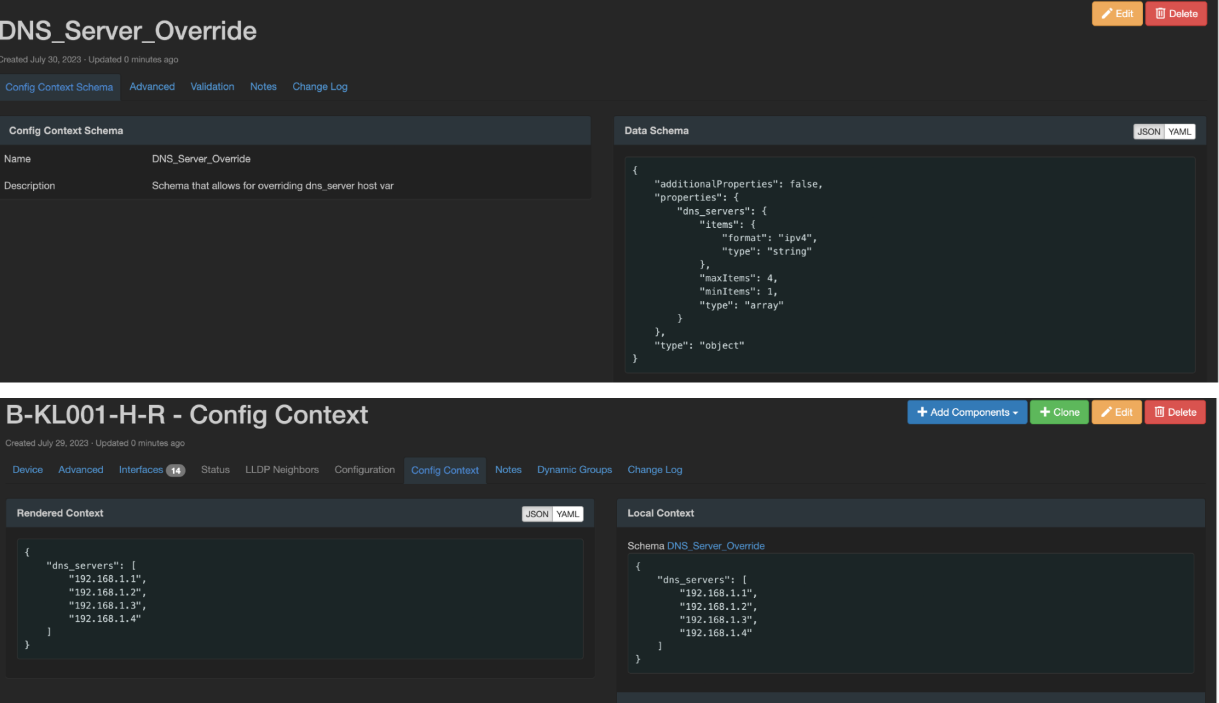
Config Context gives us the ability to assign a variable to an object as a host variable in order to overwrite a group variable. This gave us some scalability in supporting more than just ourselves when it came to generating network configurations. The screenshot below shows the usage of config context schema and config context to allow users to overwrite a dns_server host variable. Config context schema ensures the user enters data in config context correctly so there will be no errors when generating device configurations.
Knowing that PKI authentication was going to be a requirement at some point, we wanted a solution that would integrate with Keycloak or other Identity Management solutions to give us two-factor authentication options. We ended up creating a Python dynamic inventory to query Nautobot. This inventory would run every time a config generation request was made inside of AWX, ensuring that the config would contain the most recent changes from our preferred source of truth, Nautobot.query.
The script would make an API call to Nautobot and return the results of a preconfigured graphQL query. The results of the graphQL query are then parsed in the rest of the dynamic inventory and put into a format that AWX is able to consume.
We also used the job feature to build a custom Python job that allowed us to add and/or change the device type of a tenant. This made it very easy for us to life cycle the Cisco ESR5915 with the ESR6300. Users were able to select the tenant object they wanted to change and then what they wanted to change it to. The next time they generated configurations for that tenant object, Ansible would have the latest information from Nautobot. This screenshot shows that KL001 is currently a medium_v2, which is a Cisco 6300. If we wanted to change the device types of that tenant object inside of Nautobot manually we would need to delete all of the devices and re-create them from a new device type, while assigning IPs to interfaces and assigning primary IPs to the device and changing the hostname.
Using the custom jobs option in Nautobot we are able to allow our users to run a single job that accomplishes all of the necessary changes in Nautobot to generate a new standardized config for that device type.
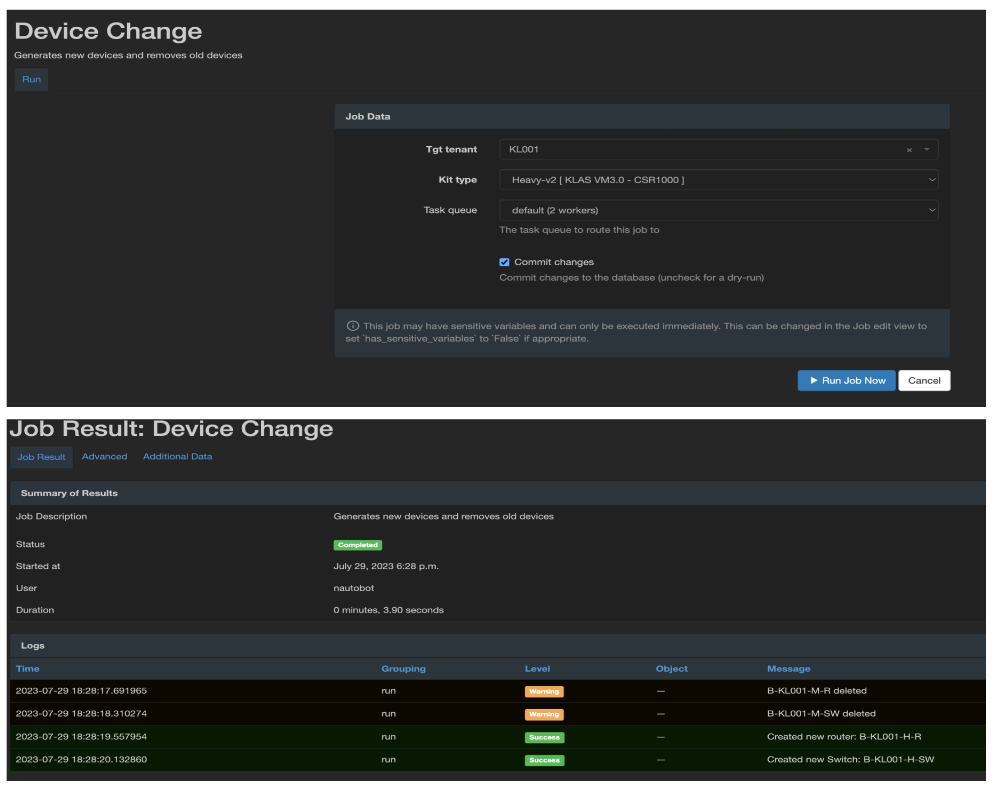
The final result of the job will be new devices within the existing tenant KL001 with updated information.
We provide a dictionary of options for the dropdown as a selection of choices, and then the rest of the jobs script deletes and creates the object based on what we deem the desired state of that device type.
Using a network source of truth like Nautobot increases the speed and flexibility of your automation. It builds trust and allows for visibility into the desired state of network devices for all users. If used correctly it can correct the state of network devices and build a safe and secure environment for network operations.
The final workflow of our automation process can be seen below, excluding the CI/CD pipelines used to validate Jinja syntax and network configurations, prior to allowing a merge request to succeed.
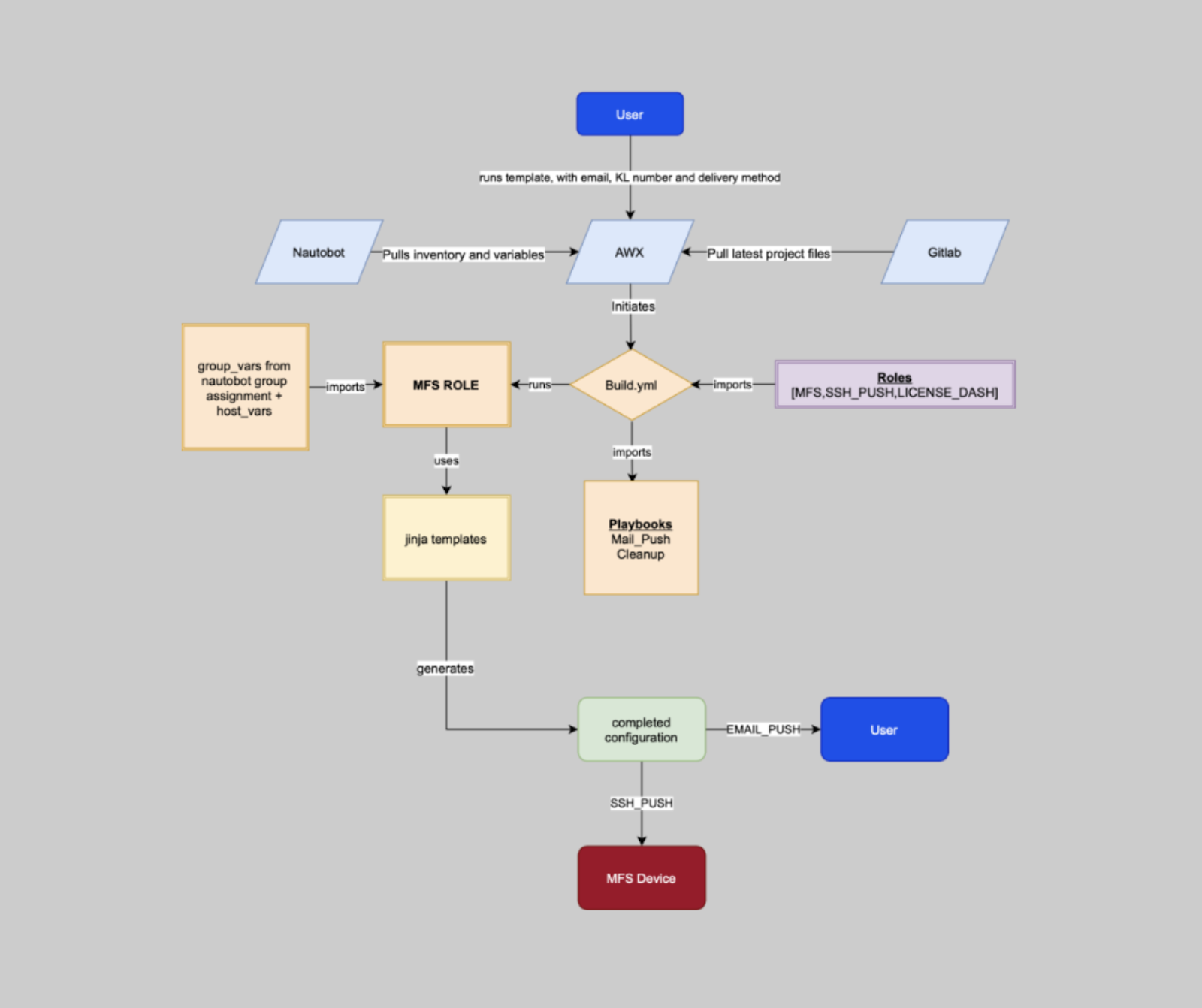
Over time and with increased experience, we have made many changes to the automation process to include more complex logic in the Jinja2 templates, template inheritance with blocks, and CI/CD pipelines for testing network configurations to name a few. The process we use for automating network configurations continues to grow and improve as we learn more and gain experience.
What else have we done and what else is on the roadmap?

I get asked a lot about how we were able to do this. How did we get the time and skills? How are we maintaining those skills or training new people that come into the organization?
Our leadership team is very supportive and encourages the teams within the organization to find new and more efficient ways to do business. We are given time and space to work through difficult problem sets. We have dedicated team members who want to solve problems and enjoy learning new things.
We developed a four-month platform engineer onboarding course that runs twice a year. All qualified new hires that are coming to the unit go through this course and learn GitLab, Ansible, Jinja, network source of truth, Django, and Kubernetes.
If you are interested in coming to JCU to work on similar projects like Automation, Coding, Edge Computing, or Kubernetes, please go to https://www.jcu.mil and fill out an application.


Share details about yourself & someone from our team will reach out to you ASAP!
