As Network Engineers, we get to use plenty of open sourced tools to help with our workflows. Open source projects like Linux, Python, and Netmiko are not only built by the code maintainer—many generous engineers contribute back to the source code. And if you find yourself using any open source tools extensively, it’s good practice (and even good karma) to try to give something back to these projects. However, contributing back to something like the Python source code can seem very daunting and scary if you’ve never contributed to an open source project before. No need to fear, though, because there are projects with an easy and simple way to get started! And all you need to know is a little Python and Regex. Sound exciting? Then let’s get you started on your way to contributing to your first open source project!
Open Source Parsers
I am of course talking about the wonderful world of CLI parsers. Projects like NTC Templates and Cisco Genie Parser aimed to take raw CLI outputs from our network devices and convert them into nice and clean structured data for other programs or scripts to use. They achieve this amazing feat by using custom Regex patterns for each and every command that could possibility be sent to network devices.
If this is your first time ever hearing about the magic of CLI Parsers, then boy am I excited for you! Our very own Mikhail Yohman has created an entire series to help you dive deep into Parsing Strategies! He goes very in depth on how these parsers work under the hood, so I won’t go into specifics here.
What I do want to highlight is that these projects encourage developers to submit custom Regex patterns for commands that are not in the project currently. This is an awesome opportunity to not only give to the community, but also to get your code into a major open source project! The post will walk you through how to develop a Regex pattern that can match an entire output.
Some Advanced Regex Commands
Okay, in order to write custom Regex patterns that can grab entire outputs, we first need to go over some Regex syntax that wasn’t covered in my previous post.
Metacharacters\s\d
First up are some shortcuts we call metacharacters that are built into Regex. The two we are going to talk about are \s and \d.
\s is a shortcut for any whitespace character. This, of course, includes the space character; but it can also capture characters like tab and new line!
\d is a quick one to understand because it just means any digit character. So instead of writing [0-9], we can just drop in \d to represent the same thing.
Any metacharacter can be capitalized to indicate you want to capture the opposite. So just as \s matches a whitespace character, a capital \S matches any NON-whitespace character. Super helpful when you want to grab something that maybe contains letters and numbers!
Quantifiers{}*+
If you want to match something 1 to 3 times, you can use quantifiers {} and write {1,3}. But you don’t have to be limited to just those two numbers. If you omit the last number like {3,}, you would match a pattern three or more times.
Regex has some cool shorthand for common quantifiers. We can use + instead of {1,} to match something one or more times and * instead of {0,} for zero or more times.
Named capture groups(?P<name>)
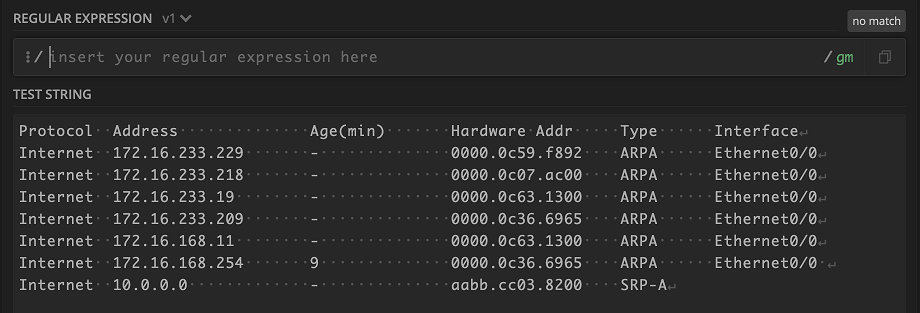
Capture groups are a really awesome feature in Regex because it allows us to assign the data that we parse with a pattern to a number so we can refer back to it later. Named capture groups are the same thing, but they let us assign a named key to a value instead of a number. We can let Regex know we want to use a named capture group by adding a ?P<some_name> to a normal capture group (). Altogether it would look something like this: (?P<some_name>)
Let’s use the MAC address 0000.0c59.f892 to help explain. Like we discussed before, \S can match any non-whitespace character, so it is perfect for this case since MAC addresses can contain letters, numbers, and other special characters. We can then use the pattern (?P<mac_address>\S+) to capture the value and assign it a key name. This will produce the following key/value pair:
"mac_address": "0000.0c59.f892"
OR operator|
One last thing I want to go over is the OR operator. Sometimes you want to match more than one thing for a particular capture group. In those cases we can use the OR operator represented with |. So if you wanted to find Arista OR Cisco, you can use (Arista|Cisco) to search for both cases.
Let’s Try It Out
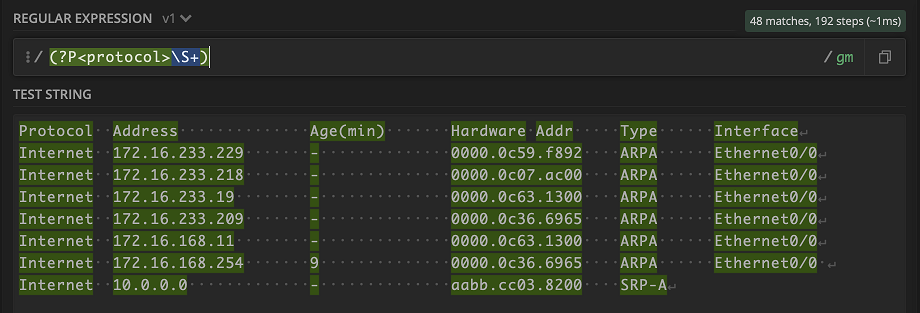
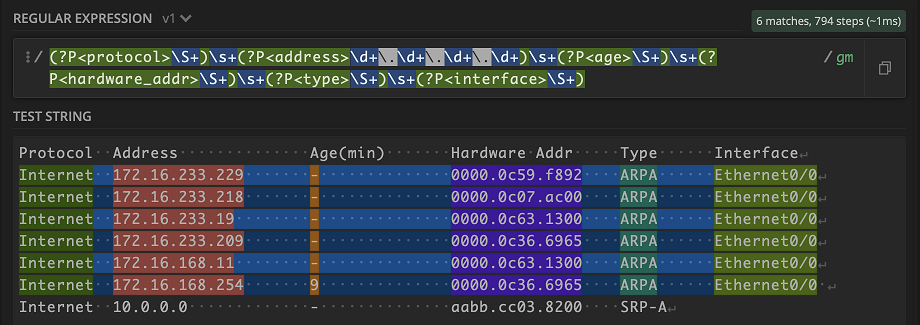
All right with all that down, let’s give it a try with an output from the command show ip arp. I like to use Regex101 to test out new parsers, so let’s drop our output in the text box.
In order to tackle the output, we just go piece by piece. Most Regex projects will parse line by line, so we can actually ignore the header of this output for now. We want to capture the value under Protocol Internet. Looks like a good candidate for \S+ for any non-whitespace character occurring one or more times.
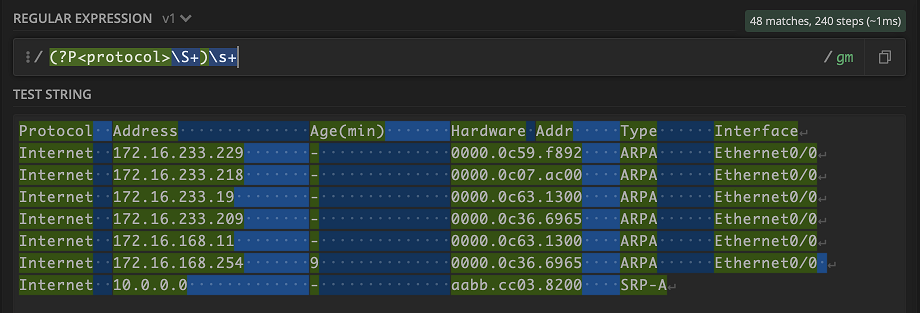
Whoa! Everything lit up. But really that makes sense, given what \S+ means. Don’t fret though, let’s keep going. Next is the whitespace that we can capture \s+
Let’s move on to the value under address Address. We can use the handy \d+ to grab any digit one or more times and use \. to backslash out the . in the IPv4 address.
Keep in mind that using \d+ is just a quick way to represent one octet in an IPv4 address. If you are validating user input, you might want to be more precise with the pattern. We can use it in this case because a network device should not output any weird IPv4 address like 999.999.999.999.
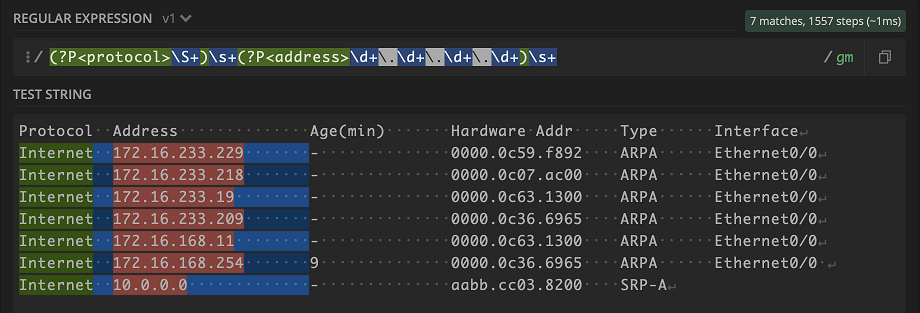
But awesome—look at that! For the next few values, I’m going to use our friend \S+ and match the names of our keys to the headers in the output. Remember to include the \s+ for the whitespace in between values.
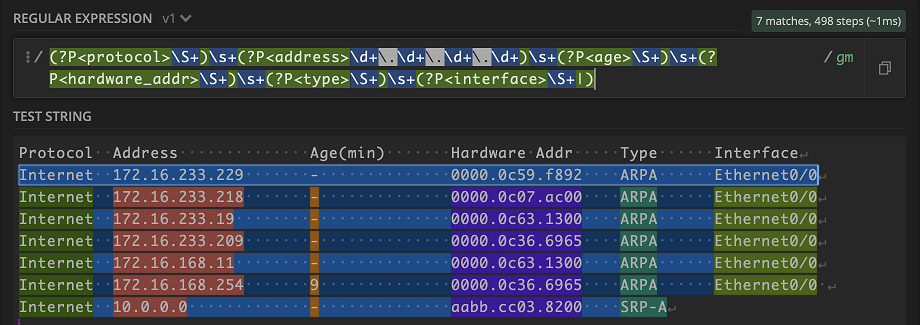
Looking good! That last line isn’t working because Interface has a case where there may be no output. No worries, we can account for this by using the | for cases with no output.
Awesome! Our final pattern can now match an entire line of different patterns!
Contributing to Projects
I hope that was fun! If this at all interested you, I encourage you to take a look at the contribution pages for NTC Templates and Cisco Genie Parser. Both projects use Regex in very different ways, so you’re going to have to get a little familiar with the particular project you want to contribute to before starting your first parser. Cisco Genie Parser uses the Regex library that is built into Python, which is what we walked through in the example above. NTC Templates leverages TextFSM, which has a language all its own. A lot of the same concepts apply, you just may need to get yourself familiar with TextFSM before starting.
Go More in Dept
If you want to go little more in depth than what we did here, again, Mikhail Yohman has an entire series on different parsing strategies and even talks specifically about both NTC Templates and Cisco Genie Parser.
Knox Hutchinson also has an awesome video on Genie Parser from SCRATCH, in which he walks you through the entire process of making the parser and actually creating a pull request to have it merge into the source code.
Conclusion
I hope you enjoyed this quick peek into the wonderful world of parsers. This post is just meant to give you some inspiration to make your first contribution to an open source project. It can be a rewarding and fulfilling process that I think every engineer should experience in their career. Thanks for reading, and I look forward to seeing whatever you create!
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Which data type is more popular, JSON or XML? I believe the overwhelming majority will say “JSON”, which is understandable, because JSON is easier to read, easier to understand, and more human friendly. Besides that, there are a lot of reading materials around JSON and how to handle such data. But what to do when only XML is supported?
The default solution for most of us today is to convert XML to JSON or Python dictionary. But this approach has some significant drawbacks because XML and JSON are not 100% compatible. XML doesn’t have the same distinction between a list and a dictionary. Depending on what you are processing you can end up with a different datastructure if you have one element returned, an interface for example, or multiple.
There is a better way to process XML data in Python by using the native construct and libraries available. This blog is intended to give you tips and tricks on how to parse XML data with Python and Ansible.
XML Data Structure
In this section, we will briefly go over the XML Data Structure and the terminology used in it, which will help us better understand the XML data.
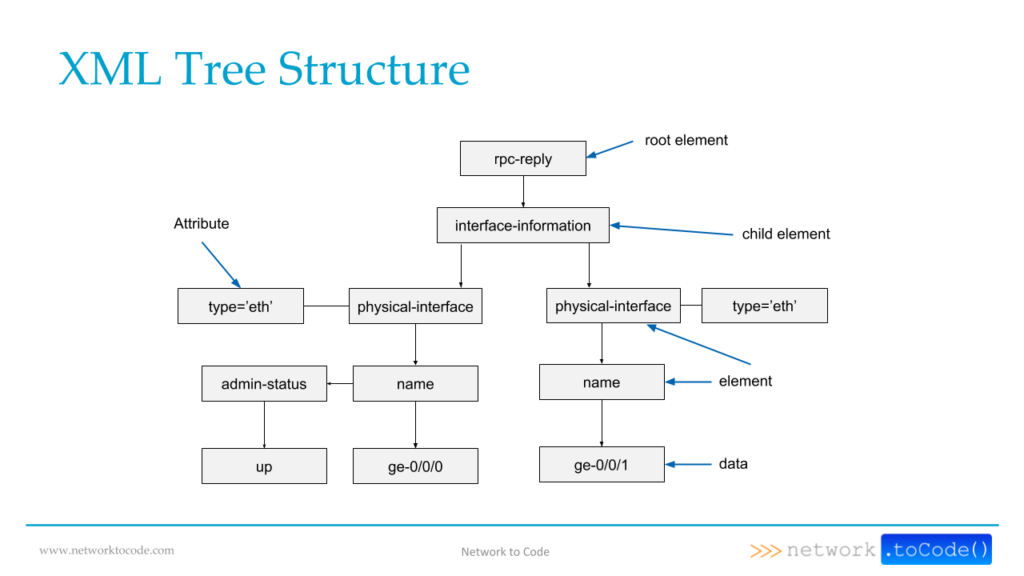
The image below depicts a sample XML data in a tree format.
NOTE Some XML data will have namespaces, and we will address them a bit later.
Now let’s explain the terminology depicted in the image:
root element – The element at the root of the XML tree. XML data will always have one root element. This element can also be referred to as parent element.
child element – Any element right below the root element is a child element. The root element may contain one or more child elements.
attribute – A tag for an element providing some information about it.
data – The data the element contains.
NOTE This is not a complete overview of the XML, but rather a quick introduction to it. The complete information about the XML can be found here.
Parsing XML with Python
Python has a very sophisticated built-in library called xml.etree.ElementTree to deal with XML data. Before we jump into the Python interpreter and start parsing the data, we will need to address XML XPath and the methods available to the xml.etree.ElementTree class.
XML XPath Support
XPath uses path expressions to find element(s) and relative data in the XML document. The xml.etree.ElementTree supports the following XPath expressions1:
Syntax
Meaning
tag
Selects all child elements with the given tag. For example, spam selects all child elements named spam, and spam/egg selects all grandchildren named egg in all children named spam. {namespace}* selects all tags in the given namespace, {*}spam selects tags named spam in any (or no) namespace, and {}* selects only tags that are not in a namespace.
*
Selects all child elements, including comments and processing instructions. For example, */egg selects all grandchildren named egg.
.
Selects the current node. This is mostly useful at the beginning of the path, to indicate that it’s a relative path.
//
Selects all subelements, on all levels beneath the current element. For example, .//egg selects all egg elements in the entire tree.
..
Selects the parent element. Returns None if the path attempts to reach the ancestors of the start element (the element find was called on).
[@attrib]
Selects all elements that have the given attribute.
[@attrib=’value’]
Selects all elements for which the given attribute has the given value. The value cannot contain quotes.
[tag]
Selects all elements that have a child named tag. Only immediate children are supported.
[.=’text’]
Selects all elements whose complete text content, including descendants, equals the given text.
[tag=’text’]
Selects all elements that have a child named tag whose complete text content, including descendants, equals the given text.
[position]
Selects all elements that are located at the given position. The position can be either an integer (1 is the first position), the expression last() (for the last position), or a position relative to the last position (e.g., last()-1).
xml.etree.ElementTree Methods and Attributes
These are the methods and attributes that we will be using:
NOTE All elements of the loaded XML data will be objects of the Element Python class and will support these methods and attributes.
Methods:
iter("<element>") – recursively iterates over all the sub-tree below the root element. Requires the element name.
findall("<xpath-expression>") – finds elements using XPath expression.
find("<element>") – finds the first child element with a particular tag.
get("<attribute-tag>") – gets the element’s attribute value.
Attributes:
tag – shows the tag name of the element (rpc-reply).
attrib – shows the value of the attribute ({'type': 'eth'}).
text – shows the data assigned to the element (ge-0/0/0.0).
Now we are ready to work with the XML data. Let’s start by opening the Python interpreter and importing the xml.etree.ElementTree class as ET for brevity.
>>>import xml.etree.ElementTree as ET
We will need to load the data now. It can be done two ways. Either load the XML file with the parse() method then obtain the root element with getroot() method, or load it from string using fromstring().
NOTE We will be using the XML data shown in the XML Data Structure section, but with more interfaces.
>>> tree = ET.parse('interface_data.xml')>>> root = tree.getroot()
or
>>> root = ET.fromstring(interface_data)
To print the tag of the root element we can use the tag attribute
>>> root.tag'rpc-reply
Let’s iterate of the child elements of the root element and print its tag names:
>>> for child inroot:...print(child.tag)...interface-information
As we can see from the output, the root element has only one child element, with interface-information tag name. To see more data, we can iterate over the interface-information element and print its elements’ tag names and attributes:
>>> for child inroot:... for element inchild:...print(f"Element Name: {element.tag} Element Attribute: {element.attrib}")...Element Name: physical-interfaceElementAttribute: {'type':'eth'}Element Name: physical-interfaceElementAttribute: {'type':'eth'}Element Name: physical-interfaceElementAttribute: {'type':'eth'}Element Name: physical-interfaceElementAttribute: {'type':'eth'}Element Name: physical-interfaceElementAttribute: {'type':'eth'}
Even though the nested iteration works, it is not optimal, since the XML tree can have several layers. Instead, we can use iter() method and provide an element name as a parameter. In this case, we will iterate over only the found elements. For example, let’s iterate over all name elements and show their contents.
>>> for element in root.iter('name'):...print(element.text)...ge-0/0/0ge-0/0/0.0ge-0/0/1ge-0/0/1.0ge-0/0/2ge-0/0/2.0ge-0/0/3ge-0/0/3.0ge-0/0/4ge-0/0/4.0
In the same way, we can iterate over the elements in question, but with the help of the findall() method. For it, we will need to provide XPath expression as an argument. This time, we would like to print all IP addresses that are assigned to the ifa-local element:
NOTE The period before the forward slashes indicates that the search needs to happen from current element.
>>> for element in root.findall('.//ifa-local'):...print(element.text)...172.16.0.151/24192.168.10.1/2410.10.10.1/24172.31.177.1/24192.168.0.1/24
The XPath expression to find a particular element with a specific attribute will be a little bit different. For it, we will need to use findall(.//*[@type]) syntax to search from current element against all the elements that have an attribute tag of type:
>>> for element in root.findall('.//*[@type]'):...print(element.tag, element.attrib)...physical-interface{'type':'eth'}physical-interface{'type':'eth'}physical-interface{'type':'eth'}physical-interface{'type':'eth'}physical-interface{'type':'eth'}
Parsing XML Data ith Namespaces
XML Namespaces are used to group certain elements identified by Uniform Resource Identifier (URI) and avoid any element name conflicts in the XML document. Detailed information about XML Namespaces can be found here.
If we try to find a specific element using one of the methods that we discussed before, soon we will find out that no elements are matched.
>>> tree_xmlns = ET.parse("interface_data_with_xmlns.xml")>>> root_xmlns = tree_xmlns.getroot()>>> for element in root_xmlns.findall('.//ifa-local'):...print(element.text)...>>>
The reason is that each element of the interface-information child element is appended with {URI} tag. To see how it looks, we can print the tag name of the root’s child-element:
NOTE The root element does not have the URI tag appended since it has only XML name definition rather than assignment.
Now, if we change the syntax and search for the all ifa-local elements, we should get the desired result:
>> for element in root_xmlns.findall('.//{http://xml.juniper.net/junos/20.2R0/junos-interface}ifa-local'):...print(element.text)...172.16.0.151/24192.168.10.1/2410.10.10.1/24172.31.177.1/24192.168.0.1/24
Python recommends a different way to search for elements with namespace. For that, we will need to create a dictionary and map a key to the namespace URI, then, using the desired class method, provide the dictionary as a second argument. The syntax looks like this:
>> ns =dict(interface="http://xml.juniper.net/junos/20.2R0/junos-interface")>> for element in root_xmlns.findall('.//interface:ifa-local', ns):...print(element.text)...172.16.0.151/24192.168.10.1/2410.10.10.1/24172.31.177.1/24192.168.0.1/24
In Python 3.8 and above, the namespace can be referenced with an asterisk character(*):
>> for element in root_xmlns.findall('.//{*}ifa-local'):...print(element.text)...172.16.0.151/24192.168.10.1/2410.10.10.1/24172.31.177.1/24192.168.0.1/24
Parsing XML with Ansible
Parsing XML with Ansible can be done using two methods. The first method involves using community.general.xml module which is very well documented. The second, more interesting, one using the parse_xml filter. Here we will be showing the second option.
parse_xmlAnsible Filter
To use the filter, we will need to create a specification file. The file has two parts: the first part defines the elements that need to be extracted from the XML data. The second part defines the variables and their values that will be available in the Ansible Playbook. We will start by looking at the first part.
result – The name of this key can be set to anything.
value – This is a predefined key which holds a Jinja2 variable which will be mapped to a variable that will be defined in the second part of the specification file.
top – This key holds the path to the element that will be iterated over for data extraction. Note that the path starts from the child element not the root element.
items – This is a predefined key which will hold multiple items.
name – Key that will hold the value that is assigned to the <name></name> element.
admin_status – Key that will hold the value that is assigned to the <admin-status></admin-status> element.
oper_status – Key that will hold the value that is assigned to the <oper-status></oper-status> element.
ifl_name – Key that will hold the value that is assigned to the <name></name> element which is a child elment of the <logical-interface></logical-interface> element.
ip_addr – Key that will hold the value that is assigned to the <ifa-local></ifa-local> element. Note that here we are using XPath expression to locate the desired element.
Now let’s look at the second part of the file and break it down:
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Thank you for joining me for Part 3 of the parsing strategies blog series. This post will dive deeper into using Cisco’s PyATS Genie library for parsing. For further reference in this blog post, I’ll be referring to the Genie library just by Genie. Genie also uses Regular Expressions (RegEx) under the hood to parse the output received from a device whether it’s semi-structured data, XML, YANG, etc. This is a key difference from other parsers, but for now, let’s stick with parsing semi-structured data.
Let’s move on and dive deeper into what the show lldp neighbors parser looks like, how it works, and how we need to modify our existing playbook to use the Genie parsers.
Genie Primer
Before we get too deep into how Genie works, you can see all the available parsers. The number of parsers has increased dramatically over the last several months and is starting to include more vendors, which is great to see.
Genie uses Python classes to build two important parsing functions:
Schema class: This class defines the schema the structured output should adhere to.
Parser class: This class defines the actual parsing methods for the specific command.
One key difference between what we’ve covered so far and Genie parsers is the ability to connect to devices and grab the necessary output, which is the default behavior, but also allows users to provide the output instead, thus working like most parsers that are separate from the device interaction.
Another key difference is the ability to use other parsing strategies within Genie such as TextFSM or Template Text Parser (TTP), but for the sake of this post, we will be covering RegEx.
You can find more detailed information on how the Genie parsers work at their developer guide.
Let’s dive into our particular parser.
"""show_lldp.py supported commands:* show lldp* show lldp entry ** show lldp entry [<WORD>] * show lldp interface [<WORD>] * show lldp neighbors * show lldp neighbors detail * show lldp traffic"""import refrom genie.metaparser import MetaParserfrom genie.metaparser.util.schemaengine import Schema, \ Any, \ Optional, \ Or, \ And, \ Default, \ Use# import parser utilsfrom genie.libs.parser.utils.common import Common
We can see this parser is declared in the show_lldp.py module and supports several variations of the show lldp commands. It then imports re, which is the built in RegEx library. The next import is the MetaParser that makes sure that the parsers’ output adheres to the defined schema. After MetaParser is imported, the schema related imports take place that helps build the actual schema we’ll see shortly. After that, the Common class that provides helper functions is imported.
The schema class provides us insight into what the output will look like. Let’s take a look at the initial definition.
We can see that ShowLldpNeighborsSchema will be a subclass of the MetaParser class imported at the beginning of the file. Within the ShowLldpNeighborsSchema class, we define our schema attribute used to make sure our output adheres to the schema before returning it to the user.
The schema is a dictionary and is expecting a total_entries key with an integer value and an interfaces key, used to define a dictionary. Each interface will be a key within the interfaces dictionary and the data obtained from the output is defined in several other nested dictionaries. Each key value pair specifies the key and the type of value it must be. There are also Optional keys not required to pass schema validation.
Now that we see the schema, we can mock up what our potential output would be.
We can see the ShowLldpNeighbors class is inheriting the ShowLldpNeighborsSchema class we just covered. Now there is a mapping for the short form capabilities codes returned within the output when neighbors exist, and the long form the parser wants to return to the user.
The next defined variable is cli_command. It specifies the commands executed by the parser if no output is provided.
Let’s take look at the cli method to see what will be executed when a user specifies the cli parser for show lldp neighbors command.
Each type of output will be specified as a method under the parser class. For example, if the device returns xml, there will be an xml method that will parse and return structured data that adheres to the same schema as the cli output.
Let’s explore the code in bite size chunks to show what’s happening.
def cli(self, output=None):if output is None: cmd = self.cli_command[0] out = self.device.execute(cmd)else: out = output parsed_output ={}
We can see the cli method takes an optional argument named output, but defaults to None. The first logic determines whether the user has provided the output or whether the parser needs to execute the command against the device. The connection the parser uses is provided by the PyATS library. This means no other library is required such as netmiko or napalm to connect to the devices.
# Total entries displayed:4 p1 = re.compile(r'^Total\s+entries\s+displayed:\s+(?P<entry>\d+)$') # Device ID Local Intf Hold-time Capability Port ID # router Gi1/0/52117 R Gi0/0/0 # 10.10.191.107 Gi1/0/14155 B,T 7038.eeff.572d # d89e.f3ff.58fe Gi1/0/333070 d89e.f3ff.58fe p2 = re.compile(r'(?P<device_id>\S+)\s+(?P<interfaces>\S+)' r'\s+(?P<hold_time>\d+)\s+(?P<capabilities>[A-Z,]+)?' r'\s+(?P<port_id>\S+)')
After the parsed_output variable is instantiated the next step is to define the RegEx expressions used to find the valuable data within the device output. Since the output is tabulated, which means it’s defined as a table, all values we care about will be on the same line (row) for each neighbor.
The parser uses re.compile to specify the RegEx expression ahead of time for use later in the code. Typically, re.compile is used when the same expression is used multiple times.
p1 will provide the total_entries within our schema, by using the Named Capturing Groups ability within the re library. Luckily, Cisco provide great documentation within the code to tell you what each RegEx is expecting to capture. p2 defines the RegEx used to capture the neighbor related information. We can see it uses mostly \S+ which captures any non-whitespace since the output is straight forward. But we can see the capabilities named capture group is a bit more complicated. It’s expecting at least one or more capital letter or comma, and then zero or one of that RegEx expression. This may be better explained by their example if we look at the capabilities column, it shows that it can capture a single capability, two capabilities with a comma, or zero capabilities.
Now let’s look at the remaining code to see how it uses these RegEx expressions.
for line in out.splitlines(): line = line.strip() # Total entries displayed:4 m = p1.match(line)ifm: parsed_output['total_entries'] =int(m.groupdict()['entry'])continue # Device ID Local Intf Hold-time Capability Port ID # router Gi1/0/52117 R Gi0/0/0 # 10.10.191.107 Gi1/0/14155 B,T 7038.eeff.572d # d89e.f3ff.58fe Gi1/0/333070 d89e.f3ff.58fe m = p2.match(line)ifm: group = m.groupdict() intf = Common.convert_intf_name(group['interfaces']) device_dict = parsed_output.setdefault('interfaces',{}). \setdefault(intf,{}). \setdefault('port_id',{}). \setdefault(group['port_id'],{}).\setdefault('neighbors',{}). \setdefault(group['device_id'],{}) device_dict['hold_time'] =int(group['hold_time'])if group['capabilities']: capabilities =list(map(lambda x: x.strip(), group['capabilities'].split(','))) device_dict['capabilities'] = capabilitiescontinuereturn parsed_output
We can see the parser performs a for loop through the output using the splitlines method to provide a list of each line within the output. It will strip any whitespace on either side of the string.
The parser will attempt to match the p1 compiled RegEx and if it captures it, will then add total_entries to the parsed_output dictionary and then continue to the next line in the output.
If the parser didn’t capture anything for p1, it will then attempt to match p2. If a match occurs, it will then the groupdict() method to return all the named capture groups and their values as a dictionary.
We can now see the parser uses the convert_intf_name method from the Common class imported at the top of the file.
Once the interface name is converted, the parser adds the interfaces dictionary to the parsed_output variable by extracting the information captured or defaulting to an empty dictionary for any non-captured data and then assigning it to the device_dict variable.
After the device_dict is specified, it adds the hold time to it.
The next step is to strip and split the capabilities into a list and add to the device_dict variable. The parser will then continue to the next line of the output.
Once all lines are parsed, it will return the parsed_output to the user as long as it passes schema validation.
I believe this can be easier to understand than something like TextFSM since it’s written in Python and Python is a popular language among network automation engineers.
Let’s move on and review the topology again.
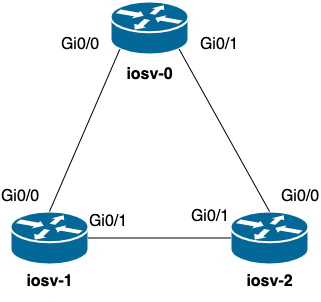
The Topology.. Again
Below is a picture of the lab topology we’re using to validate LLDP neighbors. It’s a simple topology with three Cisco IOS routers connected together and have LLDP enabled.
Ansible Setup.. Again
We’ve already covered most of the Ansible setup in part 2, but we’ll explain the small changes we have to make to use the Genie parsers within Ansible.
Here is a look at a host var we’ve defined as a refresher since there are no changes here.
Now let’s take a look at the changes in pb.validate.neighbors.yml.
----hosts:"ios"connection:"ansible.netcommon.network_cli"gather_facts:"no"tasks:-name:"PARSE LLDP INFO INTO STRUCTURED DATA" ansible.netcommon.cli_parse:command:"show lldp neighbors"parser:name: ansible.netcommon.pyatsset_fact:"lldp_neighbors"-name:"MANIPULATE THE DATA TO BE IN THE SAME FORMAT AS TEXTFSM TO PREVENT CHANGING FINAL ASSERTION TASK"set_fact:lldp_neighbors:"{{ lldp_neighbors | convert_data }}"-name:"ASSERT THE CORRECT NEIGHBORS ARE SEEN"assert:that:-"lldp_neighbors | selectattr('local_interface', 'equalto', item['local_intf']) | map(attribute='neighbor') | first == item['neighbor']"loop:"{{ approved_neighbors }}"
Using the ansible.netcommon.pyats parser requires genie and pyats to be installed via pip install genie pyats.
There are a few things to dissect with the playbook. First, we changed the parser to ansible.netcommon.pyats. Second, we added another task to manipulate the data we get back from the parser, into a similar format as the second blog post in this series so we don’t have to change the last task. I did the conversion within a custom filter plugin due to the structure of the data and the ease of handling this within Python. You will see the output below once we run our playbook.
Playbook Output
Let’s go ahead and run the playbook and see what output we get.
I ran this playbook with some verbosity to show what each task returns and the format of our parsed data.
If we take a closer look at the output of the first task, we can see under the parsed key as well as setting the fact (lldp_neighbors), that we have our structured data from running the raw output through Genie.
The second task shows the loop for each host and the item it’s using during the loop. If you look back at our playbook, we’re using both the local_intf and neighbor for our assertions from our approved_neighbors variable.
Summary
We converted the data using a custom filter plugin, but we could have easily adjusted the facts and final assertions to align with the output we receive back from Genie. It’s also valuable to show the possibility of having a single playbook using any parser to run operational assertions. If we were in production, we could make the convert_data custom filter plugin translate several different parser formats into a parser agnostic format.
For brevity, here is our tree output to show you what the folder structure looks like to use a custom filter plugin.
I hope you enjoyed this blog post and understand a little bit more about Genie parsers and how to consume them with Ansible. The next post in this series will go over Ansible Engine parsing.
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. In case of sale of your personal information, you may opt out by using the link Do not sell my personal information. Privacy | Cookies
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
__hssc
30 minutes
HubSpot sets this cookie to keep track of sessions and to determine if HubSpot should increment the session number and timestamps in the __hstc cookie.
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie records the user consent for the cookies in the "Advertisement" category.
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
CookieYes sets this cookie to record the default button state of the corresponding category and the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Cookie
Duration
Description
__cf_bm
30 minutes
Cloudflare set the cookie to support Cloudflare Bot Management.
li_gc
5 months 27 days
Linkedin set this cookie for storing visitor's consent regarding using cookies for non-essential purposes.
lidc
1 day
LinkedIn sets the lidc cookie to facilitate data center selection.
UserMatchHistory
1 month
LinkedIn sets this cookie for LinkedIn Ads ID syncing.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__hstc
5 months 27 days
Hubspot set this main cookie for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
1 year 1 month 4 days
Google Analytics sets this cookie to calculate visitor, session and campaign data and track site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognise unique visitors.
_gat_gtag_UA_*
1 minute
Google Analytics sets this cookie to store a unique user ID.
_gid
1 day
Google Analytics sets this cookie to store information on how visitors use a website while also creating an analytics report of the website's performance. Some of the collected data includes the number of visitors, their source, and the pages they visit anonymously.
AnalyticsSyncHistory
1 month
Linkedin set this cookie to store information about the time a sync took place with the lms_analytics cookie.
CONSENT
2 years
YouTube sets this cookie via embedded YouTube videos and registers anonymous statistical data.
hubspotutk
5 months 27 days
HubSpot sets this cookie to keep track of the visitors to the website. This cookie is passed to HubSpot on form submission and used when deduplicating contacts.
ln_or
1 day
Linkedin sets this cookie to registers statistical data on users' behaviour on the website for internal analytics.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
bcookie
1 year
LinkedIn sets this cookie from LinkedIn share buttons and ad tags to recognize browser IDs.
bscookie
1 year
LinkedIn sets this cookie to store performed actions on the website.
li_sugr
3 months
LinkedIn sets this cookie to collect user behaviour data to optimise the website and make advertisements on the website more relevant.
VISITOR_INFO1_LIVE
5 months 27 days
YouTube sets this cookie to measure bandwidth, determining whether the user gets the new or old player interface.
YSC
session
Youtube sets this cookie to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the user's video preferences using embedded YouTube videos.
yt-remote-device-id
never
YouTube sets this cookie to store the user's video preferences using embedded YouTube videos.
yt.innertube::nextId
never
YouTube sets this cookie to register a unique ID to store data on what videos from YouTube the user has seen.
yt.innertube::requests
never
YouTube sets this cookie to register a unique ID to store data on what videos from YouTube the user has seen.