

Structured Data, Schemas, Network as Code, and Sources of Truth—what do these all have in common? Data is central to all of them in concept and in practice. How do we work with all of that data? By modeling it of course! We’ll discuss how to start data modeling. Data modeling is not typically the focus of the conversation but is usually what you are working with, and it’s important to understand some ways to approach data modeling.
Data models are abstractions—they detail the information and relationships we need to take into account that, when combined with assumptions, come up with the entire description of the subject. Data modeling is more of an art than a science. Coming up with a data model will almost always be an iterative approach: having too much and paring back or having too little and adding.
Generally, there are two approaches to modeling:
- Top-down: Starting with what you want and expanding/refining
- Bottom-up: Starting with what you have and refining
In top-down modeling, you typically try to come up with the data that you think you’ll need; likely it won’t be all or the same data that you end up with. In this case, the data modeling exercise is much like developing a new design.
In bottom-up modeling, you will have many more points of data than your model will end up describing. The beginning of a bottom-up process would likely be a configuration itself. As you see as we begin to cover in our example, we start to peel the layers back as we make assumptions and take into account certain facts or axioms about our data, design, and configurations.
Diving into Topologies
We’re going to cover more of the bottom-up process today since that’s where a lot of NetDevOps are starting: with existing networks, data, and configurations that need to be reasoned over and modeled.
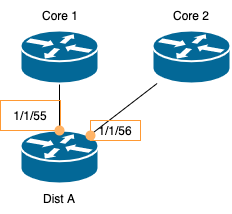
We’ll go over an example focused on modeling Devices’ Connections and what we need to model in order to derive their configurations. Consider the diagram below. It is a typical campus design where a location aggregation or distribution router aggregates all of the connections from the building and then connects to the core. This is a very common network design pattern. We’re interested in modeling the Layer 3 interfaces of Dist A in the diagram below. Generally, this modeling exercise should be applicable to most other Layer 3 interfaces in the network, but especially other Layer 3 interfaces connected to core devices on distribution switches.
Configurations
Because our design has been ruthlessly standardized, the topology above is a good example for all of our campus buildings. From the diagram, we can immediately determine that our two distribution switches should have some standard ports dedicated to certain functions: 1 uplink to the campus core, 2 cross-connects, and 2 downlinks to access switches for each distribution switch. Here’s a snippet of the configuration for dist-a.
interface 1/1/55 no shutdown mtu 9198 qos trust none description Connection to C.Core 1 ip mtu 9198 ip address 10.10.1.2/30 arp timeout 600
interface 1/1/56 no shutdown mtu 9198 qos trust none description Connection to C.Core 2 ip mtu 9198 ip address 10.10.1.5/30 arp timeout 600
Keep in mind that we’re trying to get the minimum amount of data that will be able to regenerate the configuration above.
From this configuration, we could start with a model like this:
[{
"name": "1/1/55",
"shutdown": False,
"lag": None,
"mtu": 9198,
"qos-trust": "none",
"description": "Connection to C.Core 1",
"routing": True,
"trunking-mode": None,
"allowed-vlan": "all",
"native-vlan": None,
"ip-mtu": 9198,
"ip-address": "10.10.1.2/30",
"arp-timeout": 600
},
{
"name": "1/1/56",
"shutdown": False,
"lag": None,
"mtu": 9198,
"qos-trust": "none",
"description": "Connection to C.Core 2",
"routing": True,
"trunking-mode": None,
"allowed-vlan": "all",
"native-vlan": None,
"ip-mtu": 9198,
"ip-address": "10.10.1.5/30",
"arp-timeout": 600
}]
For data above, it is very verbose, touching on each possible configuration across most of the interfaces. This would quickly get out of hand if we need to create and manage this for every interface across all the switches across a campus. Let’s pare the model back some for our specific interface above.
We can start with taking away properties we can assume at the point of use (in the template or when building out the data) or assumed defaults:
If there is an IP, routing will be enabled and trunking will not.
All of our configured interfaces will be enabled.
The MTU will always be 9198.
If there is an IP, we need an IP-MTU statement.
ARP Timeout will always be 600.
With these assumptions, our model would look something like this
[{
"name": "1/1/55",
"description": "Connection to C.Core 1",
"ip-address": "10.10.1.2/30",
},
{
"name": "1/1/56",
"description": "Connection to C.Core 2",
"ip-address": "10.10.1.5/30",
}]
Our resulting data model above is much less verbose, making it easier to read and manage. Keep in mind the data that we will put into the model for rendering must be stored somewhere, so the fewer points of data we need for each interface the better.
Usage
After developing the data model, we can easily input the data and use it in a template such as the interface template below. While this specific template may match a certain switch model, the data input should or could match across different models of switches.
interface {{ interface["name"] }}
mtu 9198
{% if interface["description"] | length > 1 %}
description {{ interface["description"] }}
{% endif %}
{% if interface["ip_addresses"] | length > 0 %}
no switchport
{% endif %}
{% if interface["ip_addresses"] | length > 0 %}
{% for addr in interface["ip_addresses"] %}
{% if addr["address"] is defined %}
ip address {{ addr["address"] }}
{% endif %}
{% endfor %}
ip mtu 9198
ip arp timeout 600
{% endif %}
no shutdown
Process
While developing the model, it may be helpful to keep track of the model in a spreadsheet or table. Every property of the model can be kept in a spreadsheet, to make it easier to view the model all at once. Keeping the expected variable types, whether a property is required or is optional, the source of the variable in an instance of the model, and finally an example of the property value are all helpful to explain and work with the data model.
Here is an example of values to keep track of for the data model above.
| property | attribute type | required | example | system of record | description / notes |
|---|---|---|---|---|---|
| name | string | required | 1/1/55 | nautobot | |
| description | string | optional | Connection to access sw 1 | nautobot | determined by cable connection in nautobot |
| ip_addresses | string | optional | 10.10.1.2/30 | nautobot | from nautobot device interface |
Conclusion
We went over what data modeling is, how to get started with the data modeling process for network interfaces, how the data model could be used, and how to keep track of the model. In future blogs, we’ll go over the process for modeling other aspects of configuration and how the data model could be represented and/or derived from a Source of Truth. Thanks for reading!
Stephen Corry
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!