

As Network Automation becomes more popular and companies decide on Nautobot to fit the Network Source of Truth (NSoT) component within their reference architecture, the next crucial problem to solve is data population. This allows organizations quick automation wins that upper management wants to see! The starting point of population for most organizations is “Devices.” Up until now that process was probably a mix of manual populations, CSV imports, nautobot-app-device-onboarding, and most likely the Python library “network-importer” to extend that data further. All these methods have their own pros and cons, but one of the most common asks was to make onboarding devices to Nautobot easier and more flexible. Introducing the Device Onboarding app 4.0!
This revamp of the Onboarding app exposes two new SSoT jobs to simplify the device onboarding process. The first job will onboard basic device information from an IP address. The second job extends the data gathered by pulling in Interface data including VLANs, VRFs, IP addresses (creating prefixes if needed), descriptions, and more! Onboarding 4.0 retains the original implementation for users who are making use of that framework, so you can try out the new features while retaining your existing workflow. I will discuss the new release in more detail throughout this blog post.
Why?
Populating a device inventory into Nautobot takes time. The time commitment is multiplied by the need for a number of different methods, applications, and libraries just to get a decent level of metadata assigned to devices. Onboarding 4.0 addresses these and additional concerns as outlined below.
- The original OnboardingTask job in the plugin was capable of getting only basic device data into Nautobot.
- Setting up network-importer as an external program felt disjointed and required additional infrastructure resources.
- The dependency on Batfish was a challenge, as it required Batfish and its dependency on Docker to be able to be run in the environment.
- The diffsync dependency didn’t have access to many of the new “contrib” features that nautobot-app-ssot exposes.
- Adding new support for additional operating systems and data was difficult.
- Extending an existing platform’s capabilities required additional Python modules to be installed into the environment.
- The same challenge existed for adding new platform support.
- Extending an existing platform’s capabilities required additional Python modules to be installed into the environment.
- The original Onboarding extension framework required a custom app and/or Python library to be available in the environment, which, depending on the deployment method used, can result in delays and complications.
What About the Original Extension Framework?
The original OnboardingTask job and its extension framework will remain available in Onboarding 4.0. We understand that this application has been around since the release of Nautobot, and many users have invested resources into extending the application using the original framework. A deprecation of the OnboardingTask job is planned for the future; but for now, the only change users of the original extension framework need to be aware of is that this job is now hidden by default.
To find the hidden job, simply navigate to Jobs–>Jobs. Click on the Filter button and select “hidden=Yes”.
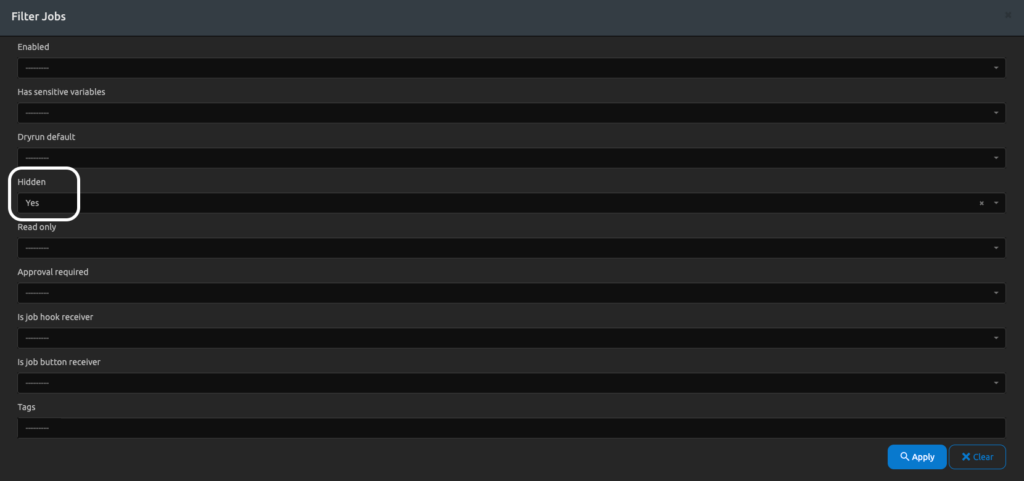
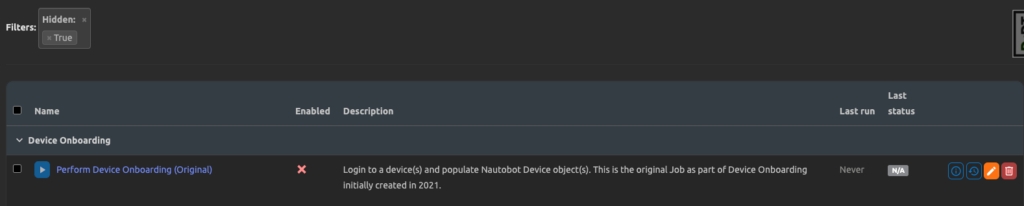
Revealing the hidden job will allow you to run it and edit job attributes as usual.
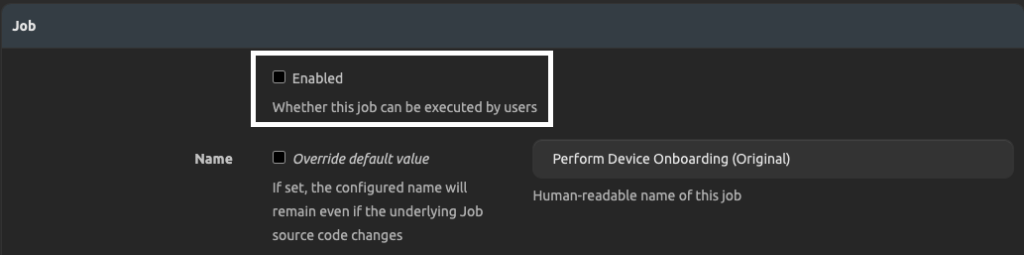
First enable the job.
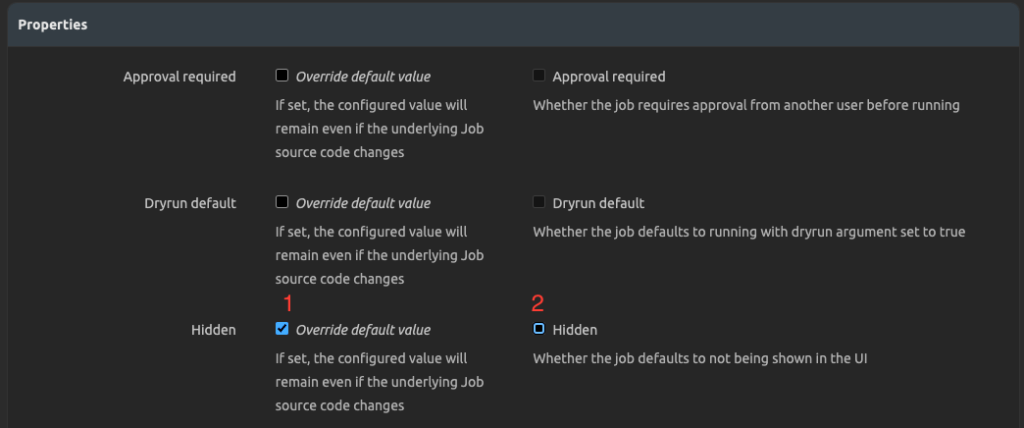
Next, feel free to override the property of the job to un-hide it by overriding the default.
The New SSoT Jobs Explained
The biggest change implemented in the 4.0 release is the use of the Single Source of Truth (SSoT) framework. The SSoT app (nautobot-app-ssot) uses a combination of diffsync, SSoT contrib, and other tools to diff inputs from disparate data sources and then sync data between those systems. This allows us to not only onboard device data but compare and update as needed. There are two new SSoT jobs to accomplish this.
- Sync devices from network – Mimics what the original onboarding task did, including creation of device(s), serial number, MGMT IP, and interface.
- Sync data from network – Mimics what the old NTC library network-importer did—syncs interfaces, their MTU, description, IP address, type, status, etc. There is a toggle option to sync VRFs and add them to interfaces as well as a toggle for VLANs that can sync VLANs and add tagged/untagged VLANs to ports.
How It Works
This section will describe the newer SSoT jobs that this App exposes and how they work.
Frameworks in Use
- Nautobot SSoT – Utilizing the existing Nautobot SSoT framework allows a common pattern to be reused and offers a path forward to add additional support and features.
- Nautobot App Nornir – Utilized for Nornir Inventory plugins for Nautobot (specifically for Sync Network Data Job).
- Nornir Netmiko – Used to execute commands and return results.
- jdiff – Used to simplify parsing required data fields out of command outputs returned from command parser libraries like textFSM. Specifically extract_data_from_json method.
- Parsers – Initially NTC Templates via textFSM, but support for pyATS, TTP, etc. is planned for the future.
YAML Definition DSL
The key extensibility feature in the new release is the ability to add new platform support by creating a single YAML definition file. The application comes with some logical defaults, but these can be overloaded and new platforms can be added via Git repositories.
File Format
Let’s review a few of the components of the file:
- ssot job name – Name of the job to define the commands and metadata needed for that job. (choices: sync_devices or sync_network_data)
- root key data name – Is fully defined in the schema definition.
- commands – List of commands to execute in order to get the required data.
- command – Actual show command to execute.
- parser – Whether to use a parser (TextFSM, pyATS, TTP, etc.). Alternatively,
nonecan be used if the platform supports some other method to return structured data, e.g.,| display jsonor an equivalent. - jpath – The JMESPath (specifically jdiff’s implementation) to extract the data from the parsed JSON returned from parser.
- post_processor – Jinja2-capable code to further transform the returned data post jpath extraction.
- iterable_type – A optional value to enforce type casting.
As an example:
---
sync_devices:
hostname:
commands:
- command: "show version"
parser: "textfsm"
jpath: "[*].hostname"
post_processor: ""
..omitted..
How the SSoTSync Devices From NetworkJob Works
- The job is executed with inputs selected.
- List of comma-separated IP/DNS names is provided.
- Other required fields are selected in the job inputs form.
- The SSoT framework loads the Nautobot adapter information.
- The SSoT frameworks network adapter load() method calls Nornir functionality.
- The job inputs data is passed to the InitNornir initializer. Because we only have basic information, a custom EmptyInventory Nornir inventory plugin is packaged with the App. This gets initialized in the InitNornir function, but actually initializes a true inventory that is empty.
- Since Platform information may need to be auto-detected before adding a Nornir Host object to the inventory, a create_inventory function is executed that uses the SSH-Autodetect via Netmiko to try to determine the platform so it can be injected into the “Host” object.
- Finally, all the platform-specific commands to run plus all the JPath post_processor information loaded from the platform-specific YAML files must be injected into the Nornir data object to be accessible later in the extract/transform functions.
- Within the code block of a Nornir with_processor context manager, call the netmiko_send_commands Nornir task.
- Access the loaded platform-specific YAML data and deduplicate commands to avoid running the same command multiple times; e.g., multiple required data attributes come from the same Show command.
- Utilize native Nornir Processor to overload functionality on task_instance_completed() to run command outputs through extract and transformation functions.
- This essentially is our “ET” portion of an “ETL” (Extract, Transform, Load) process.
- Next, the JSON result from the show command after the parser executes, e.g., Textfsm, gets run through the jdiff function extract_data_from_json() with the data and the jpath from the YAML file definition.
- Finally, an optional post_processor Jinja2-capable execution can further transform the data for that command before passing it to finish the SSoT synchronization.
How the SSoTSync Network Data From NetworkJob Works
For those looking to deep dive into the technical details or troubleshooting, here is how it works:
- The job is executed with inputs selected.
- One or multiple device selection.
- Other required fields are selected in the job inputs form.
- Toggle certain metadata booleans to True if you want more data synced.
- The SSoT framework loads the Nautobot adapter information.
- The SSoT framework’s network adapter load() method calls Nornir functionality.
- The job inputs data is passed to the InitNornir initializer. Because devices now exist in Nautobot, we use NautobotORMInventory. Nornir inventory plugin comes from nautobot-plugin-nornir.
- Finally, all the platform-specific commands to run plus all the jpath post_processor information loaded from the platform-specific YAML files must be injected into the Nornir data object to be accessible later in the extract/transform functions.
- Within the code block of a Nornir with_processor context manager call the netmiko_send_commands Nornir task.
- Access the loaded platform-specific YAML data and deduplicate commands to avoid running the same command multiple times; e.g., multiple required data attributes come from the same Show command.
- Utilize native Nornir Processor to overload functionality on subtask_instance_completed() to run command outputs through extract and transformation functions.
- This essentially is our “ET” portion of an “ETL” (Extract, Transform, Load) process.
- Next, the JSON result from the show command after the parser executes, e.g., Textfsm, gets run through the jdiff function extract_data_from_json() with the data and the jpath from the YAML file definition.
- Finally, an optional post_processor Jinja2-capable execution can further transform the data for that command before passing it to finish the SSoT synchronization.
Extending Platform Support
Adding support can be done by adding a file that parses data into the proper schema. There is a new Git datasource exposed that allows the included YAML files to be overwritten or new platform support to be added for maximum flexibility.
For simplicity, a merge was not implemented for the Git repository functionality. Any file loaded in from a Git repo is preferred. If a file in the repo exists that matches what the app exposes by default, e.g., cisco_ios.yml, the entire file from the repo becomes preferred. So keep in mind if you’re going to overload a platform exposed by the app, you must overload the full file! No merge will happen between two files that are named the same. Additionally, Git can be used to add new support. For example, if you have Aruba devices in your environment, and you want to add that functionality to device onboarding, this can be done with a custom YAML file. Simply create a Git repo and create the YAML file (name it aruba_osswitch.yml), and you’ve just added support for Aruba in your environment.
The filenames must be named <network_driver_name>.yml. See configured choices in the Nautobot UI under a platform definition.
Even better if you follow that up with a PR into the main application!
Conclusion
As the device onboarding application continues to mature, we expect to add further platform support to the defaults the app exposes. We hope the new DSL- and YAML-based extension framework makes it quick and easy to add support and load it in via Git.
Happy automating!
-Jeff, David, Susan
Tags :
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!