

Nautobot 1.1.0 is upon us! This release comes with a group of features that will offer time savings, and a customized experience for users. This post will introduce some of those features.
Additionally, be sure to check out the Nautobot 1.1.0 Key Feature Overview YouTube video, which also covers many of these features in more detail.
Computed fields allow users to create custom read-only fields from data already in the database. This new feature allows the user to specify the content type (object type) to apply the computed field to (Interface, Site, Device, etc.) and then define a Jinja2 template to create the computed field for the objects.
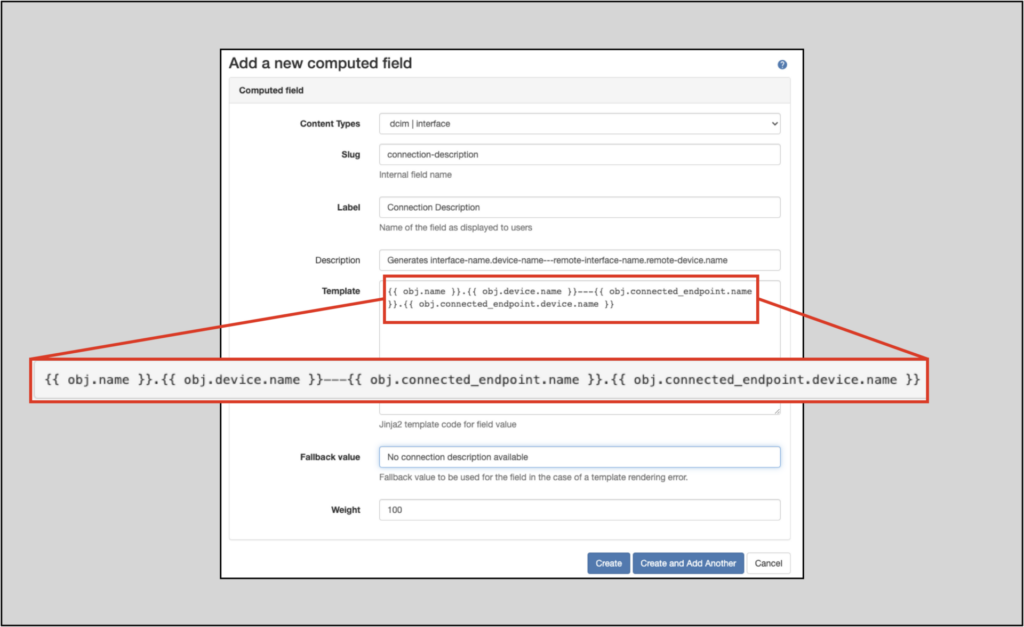
As soon as the computed field is defined, it will immediately apply to the specified content type. This example shows a computed field for Interface objects:
For more complex logic schemes, users can now define a custom Jinja2 filter for computed fields and custom links. Here is an example of a custom template with non-trivial logic:
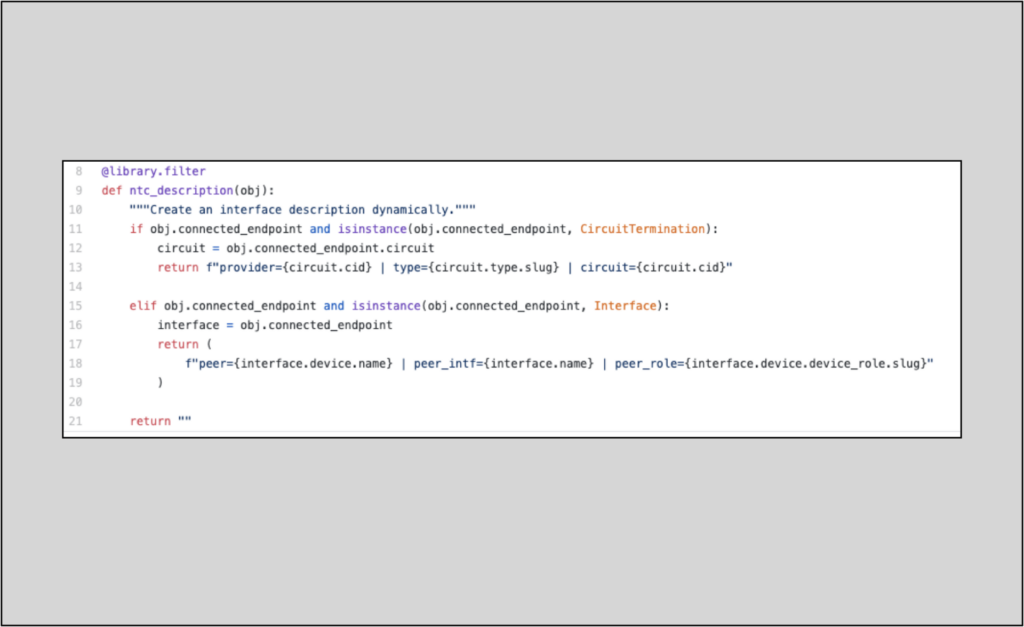
Nautobot’s documentation on including Jinja2 filters has more information on the custom Jinja2 templates and how to implement them.
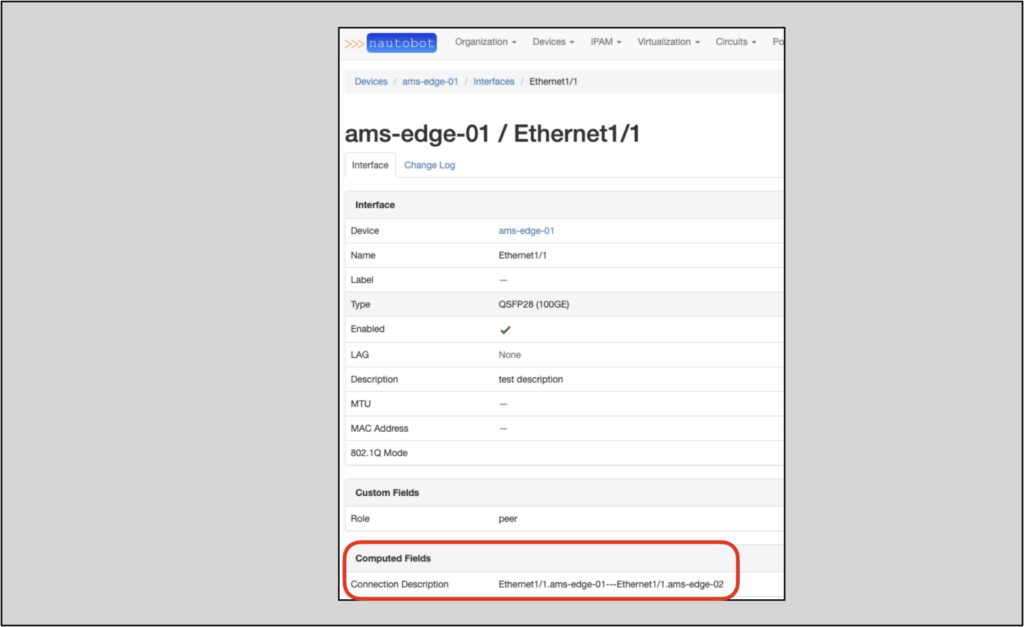
The computed fields feature also comes with an API enhancement, allowing the user to retrieve computed fields programmatically using the include query parameter:
http://127.0.0.1:8000/api/dcim/interfaces/?name=Ethernet1%2F1&device=ams01-edge-01&include=computed_fields
Here is a snip of the returned computed_fields output:
"computed_fields": {
"connection-description": "Ethernet1/1.ams01-edge-01---Ethernet1/1.ams01-edge-02",
},
Computed field data can also be retrieved via GraphQL queries using cpf_<computed_field_slug>:
query {
devices(name:["ams-edge-01"]) {
interfaces {
cpf_connection_description
}
}
}
Please see the Nautobot documentation on computed fields for more information.
Nautobot’s config context is an existing feature that allows arbitrary data to be stored in Nautobot. At scale, however, it can be helpful and necessary to apply constraints on the data structure to ensure consistency and avoid data entry errors.
In Nautobot 1.1.0, config context JSON schemas can provide such constraints.
In the example below, the config context schema applies the following constraints:
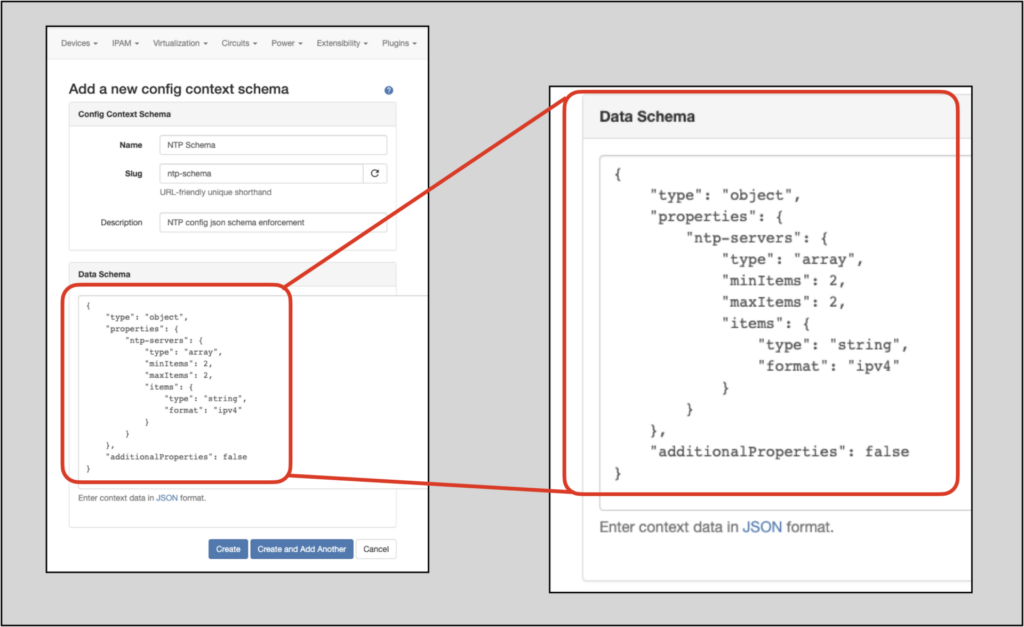
Now, when we define a new config context, we can specify the config context schema we just created. Nautobot will not allow the config context to be created if the data violates the applied schema:
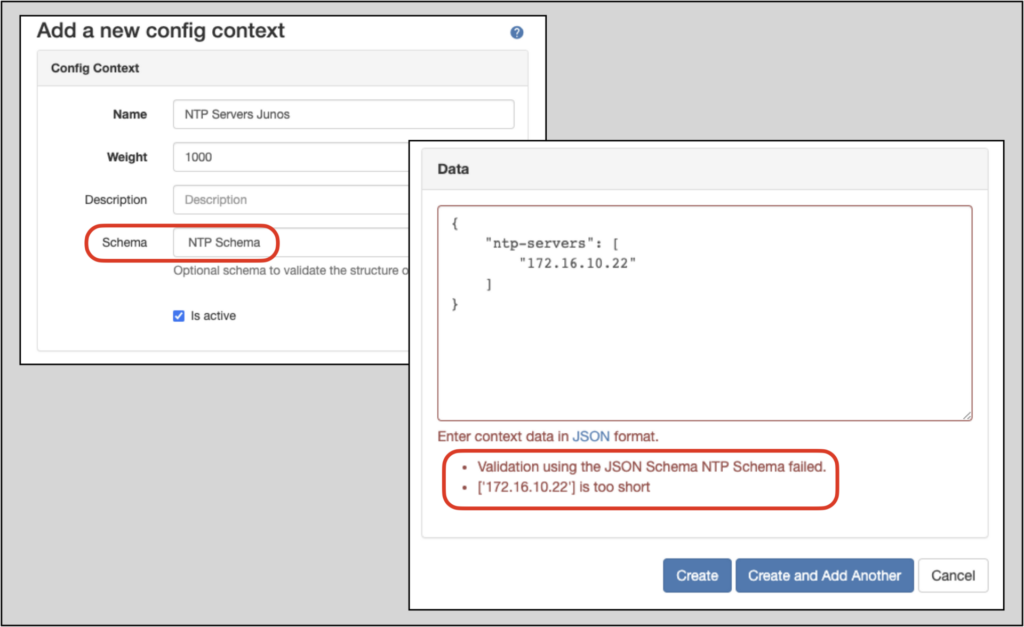
Once the config context conforms to the schema, it can be created.
Check out the Nautobot documentation on config context schemas for more info.
Nautobot 1.1.0 allows users to save GraphQL queries. This will save time and effort by eliminating the need to constantly re-create frequently-used GraphQL queries.
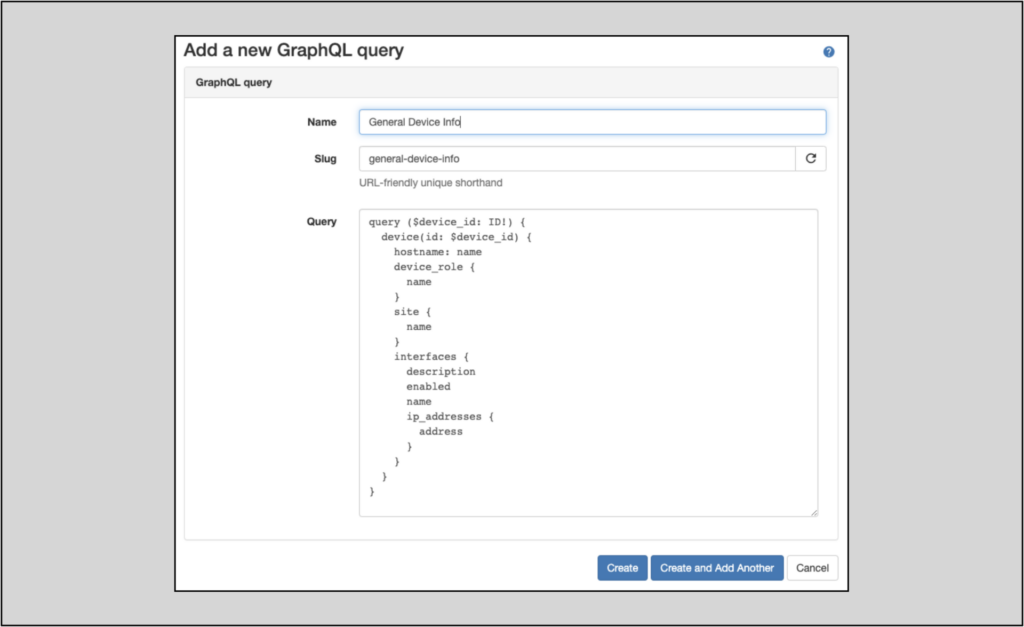
Users can craft the query in Nautobot’s GraphiQL interface. Once the query is properly tuned, creating a saved query is as easy as pasting the query into the Add a new GraphQL query form.
Once saved, each query will have its own main page:
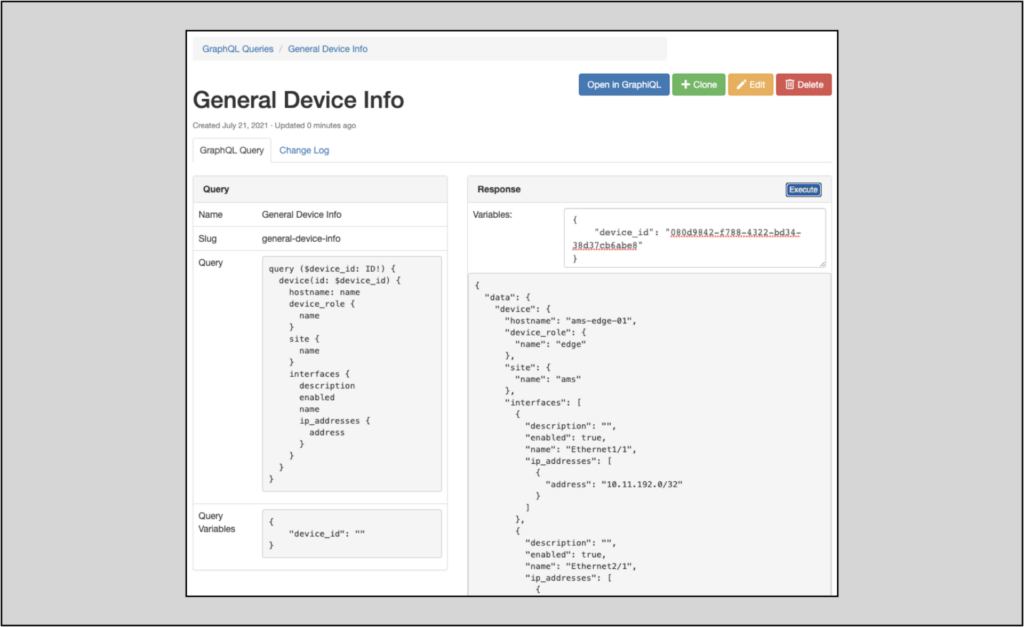
From the query’s main page, users can:
To execute a stored query via the REST API, a POST request can be sent to this endpoint:
/api/extras/graphql-queries/[slug]/run/
TIP: the slug is available on the query’s main page
Visit the Nautobot documentation on saved GraphQL queries for details.
Jobs can now be flagged as explicitly read-only to disallow committing of changes to the database. Developers can set the new read_onlyMeta class attribute to True, making the Job read-only.
Such Jobs have a “Read-only” badge and do not have the Commit changes checkbox, since the Job will hard-coded to prevent any changes.
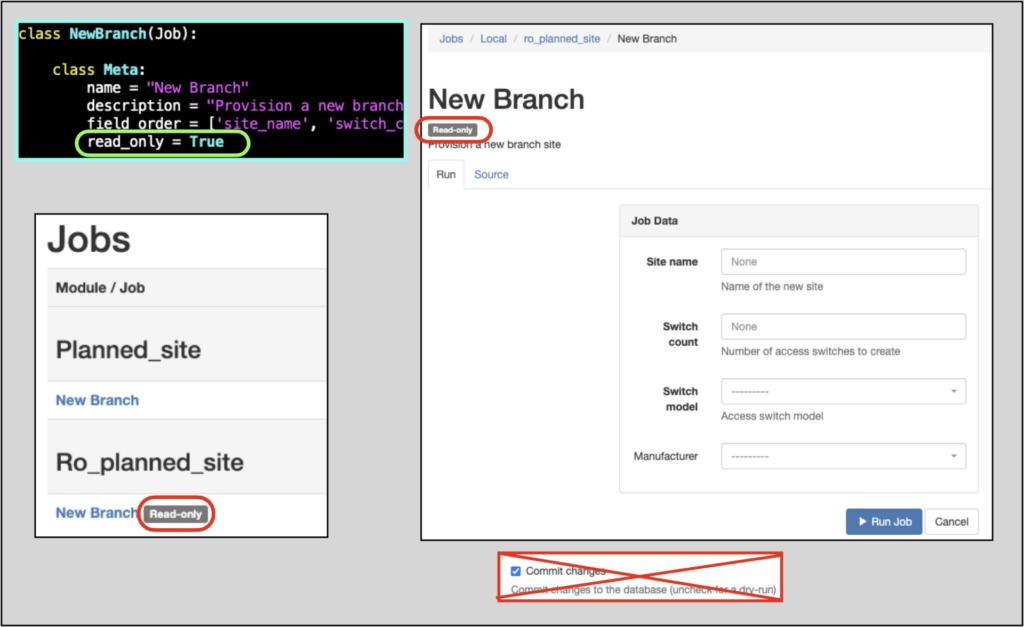
Read-only Jobs also eliminate log messages about database rollbacks, which will remove confusion for users.
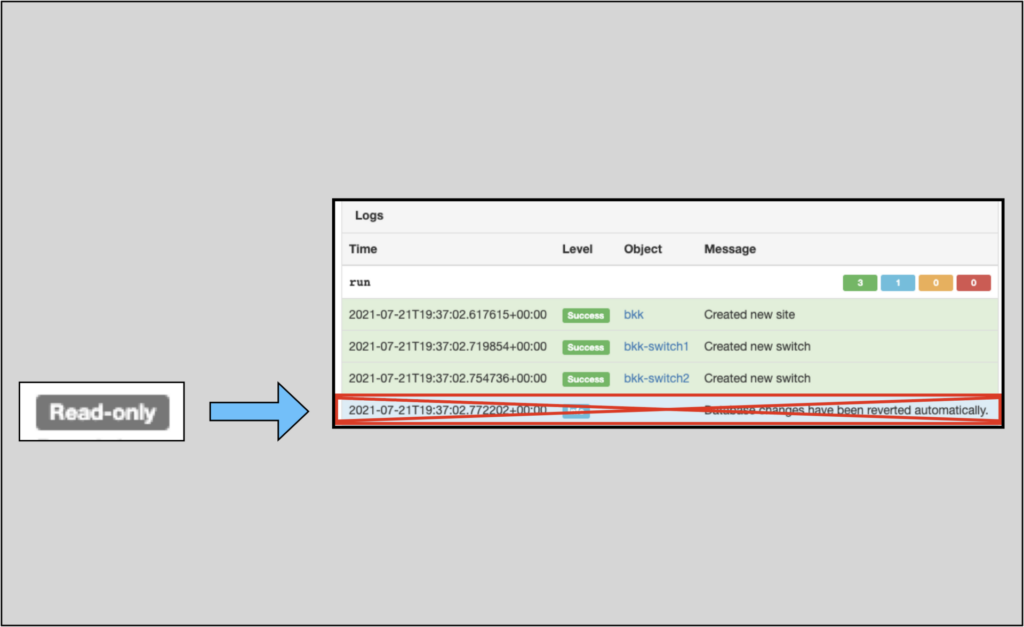
Users may also feel more confident about executing read-only Jobs because there is no chance of changing any data.
Reference Nautobot’s documentation on Jobs for more info on the read_only attribute and read-only Jobs.
In Nautobot 1.1.0, plugin authors can add tabs, groups, items, and buttons in the top navigation menu. This allows developers to customize the Nautobot navigation menu for their specific users.
In the example below, the Nautobot ChatOps NavMenuGroup gets promoted to a NavMenuTab named ChatOps:
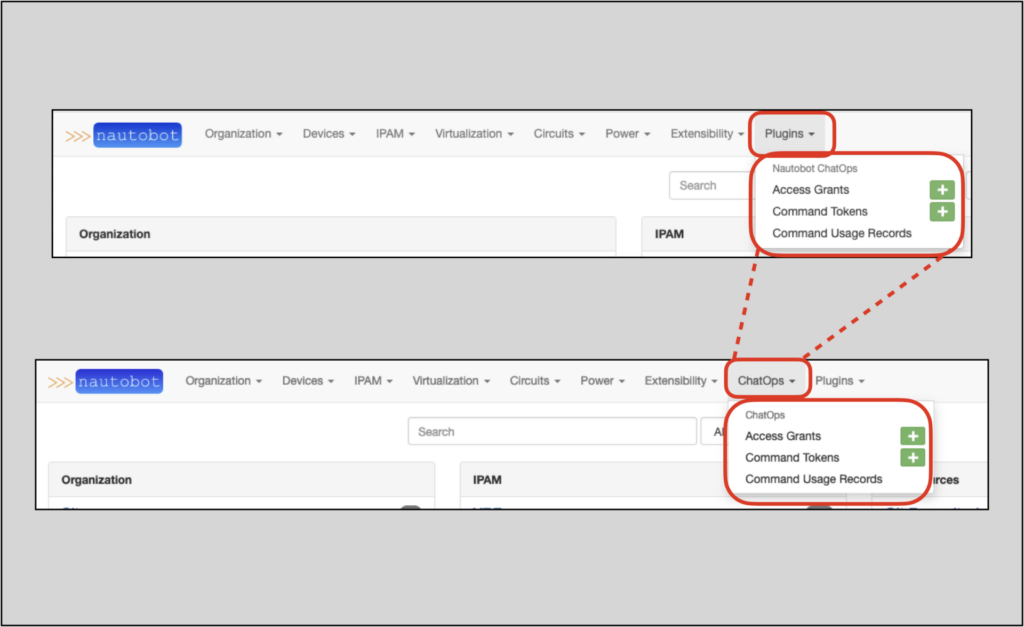
Find more info on this capability in Nautobot’s navigation menu development guide.
There are a couple of features to call out that will significantly expand the options and capabilities of a Nautobot deployment.
Celery replaces RQ for background test execution. RQ is deprecated starting in Nautobot 1.1.0.
RQ support for custom tasks is still supported to allow users to migrate to Celery or temporarily run Celery and RQ concurrently while custom tasks/plugins that use the RQ worker are migrated.
Nautobot now fully supports MySQL 8.x as a back-end database. PostgreSQL is also still fully supported. The user can choose which database option to run during installation.
A direct migration from PostgreSQL to MySQL is not supported. The transition requires a fresh start.
Please reach out to us at our #nautobot channel in our Network to Code public Slack workspace if you have any questions about these features!
Thank you, and have a great day!
-Tim
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.






Share details about yourself & someone from our team will reach out to you ASAP!