

This is the third part of the telemetry stack introduction. In the first part, we discussed the stack big picture and how we collect data using Telegraf and network plugins such as SNMP and gNMI. In the second part, we addressed data normalization and enrichment. In this third part, we will get into alerting and observing the network.
Alerting is an art and a science. It is a science because it can be deterministic, based on profiling data, and subjected to strong statistical analysis. It is an art because it needs to be based on strong context, subject matter expertise, and sometimes, intuition. Alerting is encountered in almost any area in computing, such as information security, performance engineering, and of course, networking. There is a multiplicity of tools for generating alerts based on AI, machine learning, and other hot technologies. But, what makes a good alert? The answer is: triggering on symptoms not causes, simplicity, visualization that can point to root cause, and actionability.
In this blog, we analyze the alerting systems’ architecture, focus on how to generate meaningful alerts with Alertmanager, and how to create clean visualizations that help us point out alerts before they even get triggered. We start with basic definitions and move to the details of implementing alerts using the Telegraf, Prometheus, Grafana, Alertmanager (TPGA) stack.
Prerequisites
This blog is part of a series. You can read this independently of the series if you are familiar with the Telemetry stack TPG (Telegraf, Prometheus, Grafana) and the basics of collecting telemetry with modern techniques, such as streaming. However, you can start your journey from the beginning with Introduction to a Telemetry Stack – Part 1 and then Introduction to a Telemetry Stack – Part 2, which covers normalization and enrichment.
What Is an Alert?
An alert according to Merriam-Webster dictionary is: “an alarm or other signal of danger” or “an urgent notice.” That is exactly why an alert for a computing system has to be a meaningful signal of urgency and not constant white noise that is often ignored.
In computing, alerts are used to offer awareness of issues in a timely manner. Alerts may notify about the interruption of a service, an intrusion, or a violated baseline performance threshold. They are usually part of a monitoring system and can be paired with an automated action to reduce or eliminate the event that caused the alert.
Types of Alerts
There are two types of alerts:
- Scheduled: Scheduled alerts occur at specific time periods. An example may be an alert for weekly maintenance of system patching.
- Real-time: Real-time alerts are triggered by events. Events occur randomly, and therefore continuous monitoring is required to capture these.
Alert Triggers
The triggering events that generate alerts can be grouped in the following categories:
- Status: This is a binary on/off trigger that indicates the status of a system. Context matters in the case of binary triggers regarding whether one should page a human or automation because of these alerts.
- Threshold: These are continuous metrics that are based on the profile of normal operation. They are instantaneous violations of a continuous spectrum of values, e.g., CPU passed the threshold of 80%. Again, context matters here. Is this normal for the device or exceptional? Profiling helps define what normal operation is.
- Aggregation: This trigger is similar to threshold, however in this case values are aggregated over a sliding time window. This can be a double-edged sword. On one hand, these triggers may offer a more complete picture in aggregating metrics for an alert. On the other hand, sliding windows have overlap, and this may cause unnecessary alerts.
How Does an Alerting System Work?
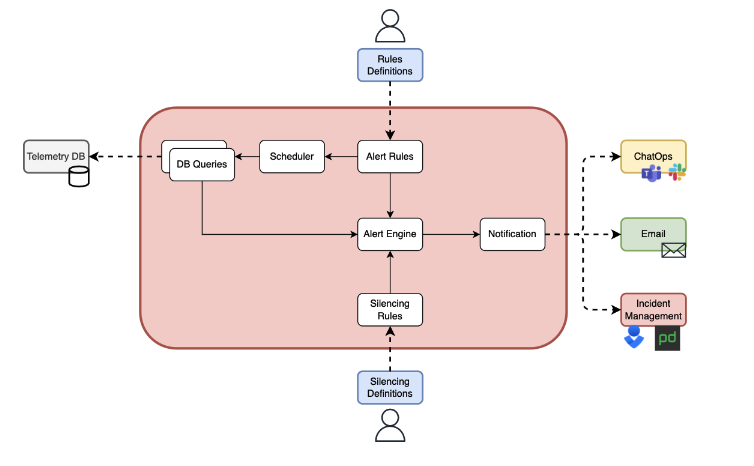
The figure below depicts how an alerting system works. The alert engine is the heart of the system and it takes three inputs: user-defined alert rules, database data related to events that can trigger the alerts, and silencing rules that are used to avoid unnecessary alerts. The output of the alert engine is a notification that is sent to outside systems, such as ChatOps, email, or incident management tools.
Metrics for a good alert?
Objective metrics are used to measure if an alert that adds value and is in turn actionable. These metrics are: the sensitivity and specificity. We define the sensitivity as “How many relevant events are reported by our alerts?” and measure it using the following formula: True_Positives / (True_Positives + False_Positives). Intuitively, if the sensitivity is high, our alert is pretty good, right? The more real alerts compared to “crying wolf” alerts, the better off we are with our pagees getting alerted and actually waking up to take care of business. We define specificity as True_Negatives / (True_Negatives + False_Negatives). Intuitively, this means that our alerts are detecting actual value and ignore the non-value adding events. In the figure below, the first half of the square calculates sensitivity and the second part specificity.

Implementing alerts with Alertmanager
In this section, we will review the TPGA stack used for alerting, then analyze the Alertmanager architecture, and finally we will demonstrate with examples how it can be used for alerting.
TPGA observability stack
We use the TPGA stack as seen in the figure below. We deploy two instances of Telegraf agent to collect the relevant data to our stack. This choice is common in network topologies, dedicating a lightweight agent for each device that is being monitored. In our case, each agent is monitoring an Arista cEOS router. The Telegraf gNMI plugin is used to gather interface operating status information and the execd plugin is used to capture BGP status. If you are not familiar with these plugin configurations, you can read the first part of the telemetry series. Prometheus is the Time Series Database (TSDB) of choice for its synergy with Alertmanager. Finally, Grafana is the visualization tool that we have selected since it specializes in time series depiction.

What is Alertmanager?
Alertmanager is a meta-monitoring tool that uses the Prometheus TSDB events to generate alerts. Note that the Alertmanager is a separate instance from Prometheus with a good reason. First, scalability of multiple Prometheus instances and one Alertmanager instance can achieve centralization of events and avoid excessive notifications, i.e., noise. Second, decoupling of the Alertmanager maintains modularity in the design and functionality.
The Alertmanager has three main functions:
- Grouping: Grouping is one of its most attractive features, since it contributes to reducing noise by combining multiple alarms and bundling them to one.
- Inhibition: This is another function that aims at reducing noise by stopping sending error alarms once an initial alarm is issued.
- Silences: Finally, silences stop sending repeated alarms within a time window.
Alertmanager has two main parts in its architecture: the router and the receiver. An alert passes through a routing tree, i.e., set of hierarchically organized rules, and then it is distributed to the corresponding receiver.
How to Configure Alertmanager and Prometheus?
First, we need to edit the configuration.yml file that has the basic configuration of Prometheus and add the following:
---
# other config
rule_files:
- rules/*.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager-01:9093
The rule files are a key to alerting, since this is where we place the alert rules in YAML syntax. In addition, the Alertmanager is defined by its name, in our case alertmanager-01, and the port 9093 where it listens. We can have a list of Alertmanager instances and rule locations.
Then the Alertmanager’s routes and receivers need to be configured in the alertmanager.yml configuration file:
---
global:
resolve_timeout: 30m
route:
receiver: empty_webhook
routes:
- group_by:
- alertname
match:
source: testing
receiver: empty_webhook
receivers:
- name: empty_webhook
webhook_configs:
- send_resolved: true
url: http://localhost:9999
Note that we have added an empty route because, for now, our alert is not going to notify another system, such as a chat client or incident response. In the last part of the telemetry series, you will see how to configure the receivers and generate notifications.
Alert Use Case 1: Interface Down
First we will show the Grafana visualization tools that we can use to alert an operator that the interface is down. I have chosen two specific types of graphs in this case. The first is a table that indicates the status of interfaces, the second is a state timeline of the status of all interfaces that belong to a device. These graphs in themselves are a good way of alerting an operator. However, we want notifications and eventually actions, that is why we need the Alertmanager.

To configure the Alertmanager, we add the following rule in rules/device_rules.yml and based on the above configuration of Prometheus, this rule is included into its Alertmanager instance:
groups:
- name: Interface Down
rules:
- alert: InterfaceDown
expr: interface_oper_status{} == 2
for: 1m
labels:
severity: critical
source: stack
environment: Production
annotations:
summary: "Interface is down"
description: "Interface for host <{{ $labels.instance }}> is down!"
This alert will fire after querying the Prometheus metric interface_oper_status and finding out that the state is down or equal to 2. Note that this rule will trigger every minute based on the keyword for. We can specify different labels for additional meta information and add a meaningful message in the description. Below you can see a short demo of how the alert fires.

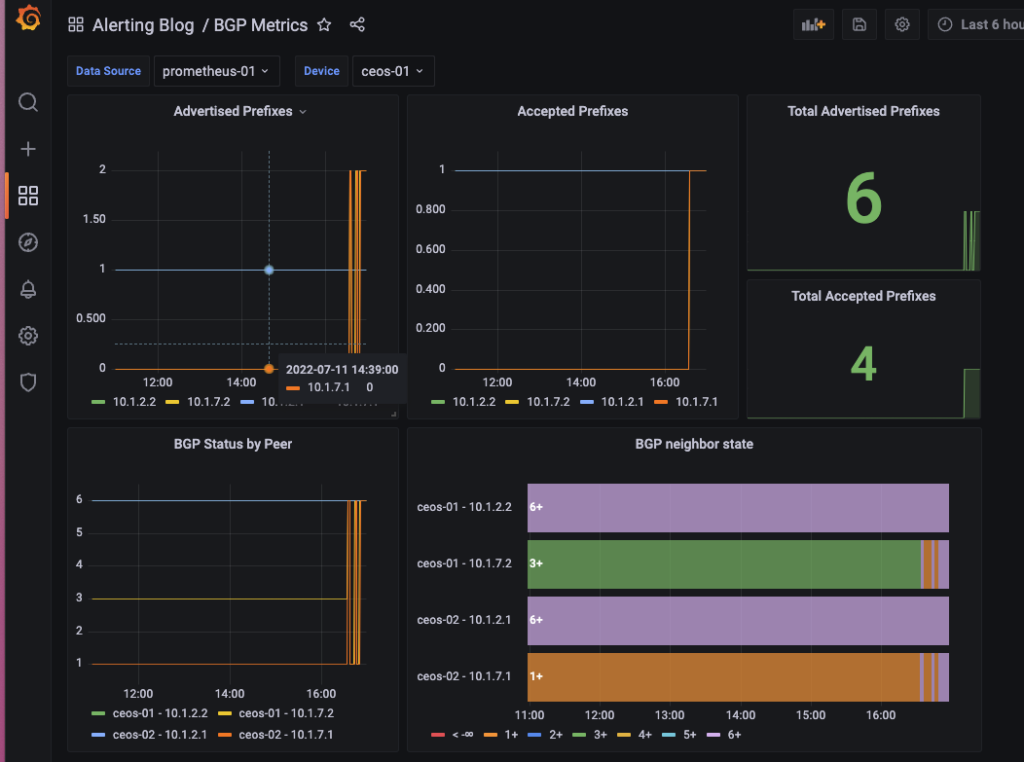
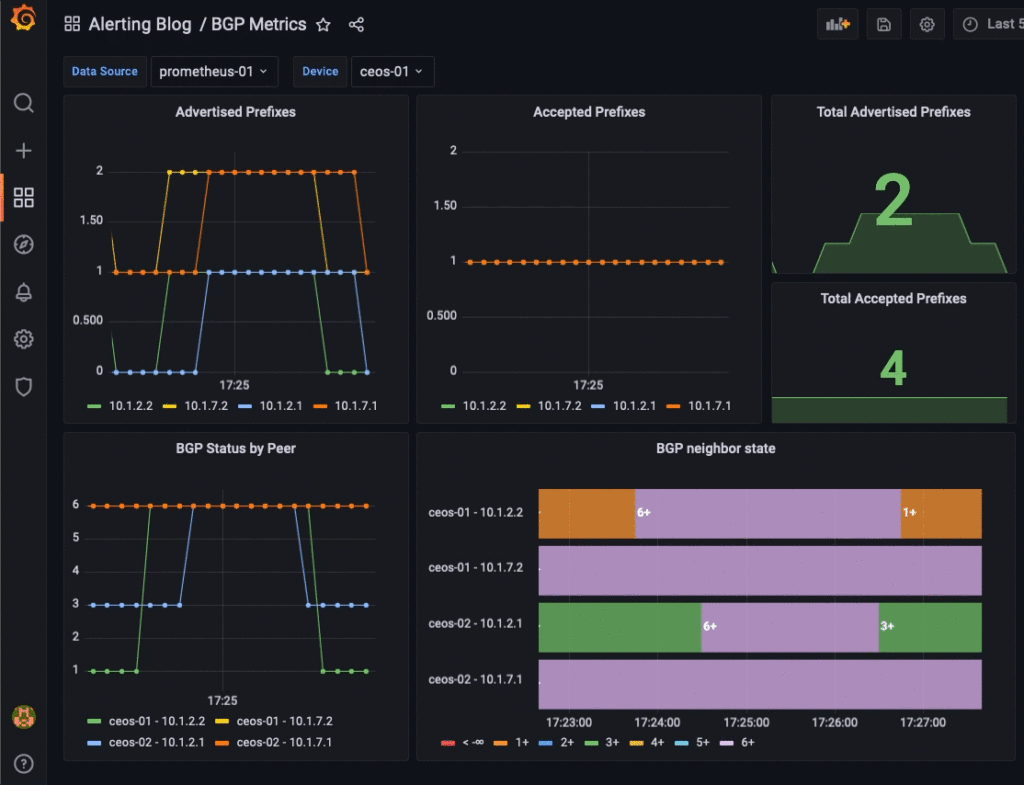
Alert Use Case 2: BGP Neighbor Unreachable
Again, a picture is worth a thousand words. In our case, the Grafana graphs offer color coded information of what is in the BGP state. The state information can be found in the list below:
IDLE = 1
CONNECT = 2
ACTIVE = 3
OPENSENT = 4
OPENCONFIRM = 5
ESTABLISHED = 6
The configuration for this alert can also be placed in: rules/device_rules.yml.
groups:
- name: BGP Neighbor Down
rules:
- alert: BGPNeighborDown
expr: bgp_session_state{device="ceos-01"} == 1
for: 1m
labels:
severity: warning
source: stack
environment: Production
annotations:
summary: "BGP Neighbor is down"
description: "BGP Neighbor for host <{{ $labels.instance }}> is down!"
The difference of this alert is in the severity message, and as you can see, we are only interested in the ceos-01 device neighbors based on the Prometheus query. For more information about PromQL queries and syntax, you can reference one of my older blogs, Introduction to PromQL.
Recap & Announcement
We have reviewed the basics of alerting systems and how to configure Prometheus and Alertmanager. If you enjoyed this series of blogs for Telemetry, this is not the end! There is one more upcoming blog about advanced alerting techniques.
Conclusion
We have some exciting news for you as well. If you want to learn how to setup your own telemetry stacks and scale it in production grade environments by NTC automation experts, check the NEW course on telemetry deep dive by NTC training.
-Xenia
Resources
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!