As Network Engineers, we get to use plenty of open sourced tools to help with our workflows. Open source projects like Linux, Python, and Netmiko are not only built by the code maintainer—many generous engineers contribute back to the source code. And if you find yourself using any open source tools extensively, it’s good practice (and even good karma) to try to give something back to these projects. However, contributing back to something like the Python source code can seem very daunting and scary if you’ve never contributed to an open source project before. No need to fear, though, because there are projects with an easy and simple way to get started! And all you need to know is a little Python and Regex. Sound exciting? Then let’s get you started on your way to contributing to your first open source project!
Open Source Parsers
I am of course talking about the wonderful world of CLI parsers. Projects like NTC Templates and Cisco Genie Parser aimed to take raw CLI outputs from our network devices and convert them into nice and clean structured data for other programs or scripts to use. They achieve this amazing feat by using custom Regex patterns for each and every command that could possibility be sent to network devices.
If this is your first time ever hearing about the magic of CLI Parsers, then boy am I excited for you! Our very own Mikhail Yohman has created an entire series to help you dive deep into Parsing Strategies! He goes very in depth on how these parsers work under the hood, so I won’t go into specifics here.
What I do want to highlight is that these projects encourage developers to submit custom Regex patterns for commands that are not in the project currently. This is an awesome opportunity to not only give to the community, but also to get your code into a major open source project! The post will walk you through how to develop a Regex pattern that can match an entire output.
Some Advanced Regex Commands
Okay, in order to write custom Regex patterns that can grab entire outputs, we first need to go over some Regex syntax that wasn’t covered in my previous post.
Metacharacters\s\d
First up are some shortcuts we call metacharacters that are built into Regex. The two we are going to talk about are \s and \d.
\s is a shortcut for any whitespace character. This, of course, includes the space character; but it can also capture characters like tab and new line!
\d is a quick one to understand because it just means any digit character. So instead of writing [0-9], we can just drop in \d to represent the same thing.
Any metacharacter can be capitalized to indicate you want to capture the opposite. So just as \s matches a whitespace character, a capital \S matches any NON-whitespace character. Super helpful when you want to grab something that maybe contains letters and numbers!
Quantifiers{}*+
If you want to match something 1 to 3 times, you can use quantifiers {} and write {1,3}. But you don’t have to be limited to just those two numbers. If you omit the last number like {3,}, you would match a pattern three or more times.
Regex has some cool shorthand for common quantifiers. We can use + instead of {1,} to match something one or more times and * instead of {0,} for zero or more times.
Named capture groups(?P<name>)
Capture groups are a really awesome feature in Regex because it allows us to assign the data that we parse with a pattern to a number so we can refer back to it later. Named capture groups are the same thing, but they let us assign a named key to a value instead of a number. We can let Regex know we want to use a named capture group by adding a ?P<some_name> to a normal capture group (). Altogether it would look something like this: (?P<some_name>)
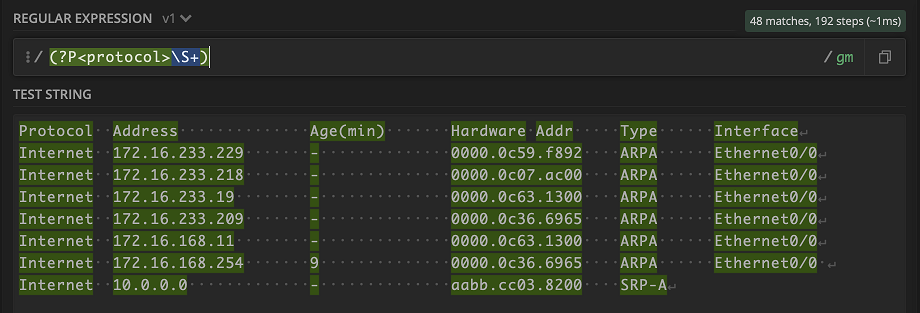
Let’s use the MAC address 0000.0c59.f892 to help explain. Like we discussed before, \S can match any non-whitespace character, so it is perfect for this case since MAC addresses can contain letters, numbers, and other special characters. We can then use the pattern (?P<mac_address>\S+) to capture the value and assign it a key name. This will produce the following key/value pair:
"mac_address": "0000.0c59.f892"
OR operator|
One last thing I want to go over is the OR operator. Sometimes you want to match more than one thing for a particular capture group. In those cases we can use the OR operator represented with |. So if you wanted to find Arista OR Cisco, you can use (Arista|Cisco) to search for both cases.
Let’s Try It Out
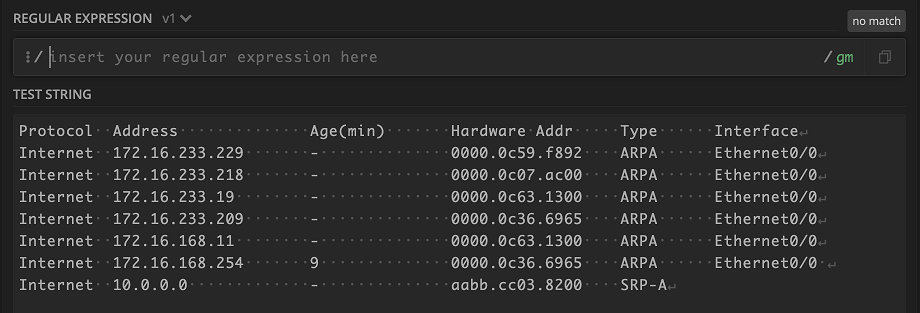
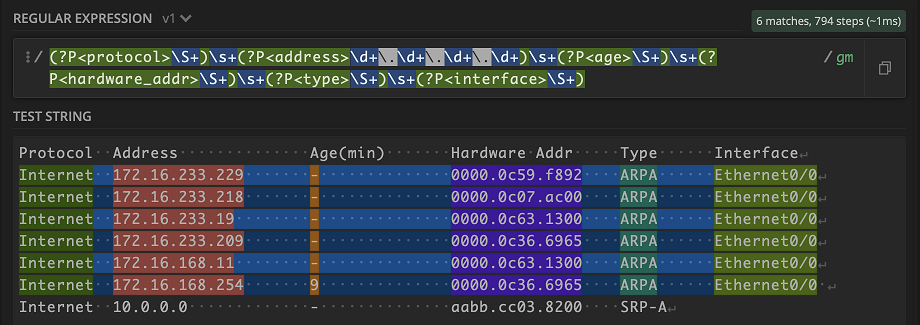
All right with all that down, let’s give it a try with an output from the command show ip arp. I like to use Regex101 to test out new parsers, so let’s drop our output in the text box.
In order to tackle the output, we just go piece by piece. Most Regex projects will parse line by line, so we can actually ignore the header of this output for now. We want to capture the value under Protocol Internet. Looks like a good candidate for \S+ for any non-whitespace character occurring one or more times.
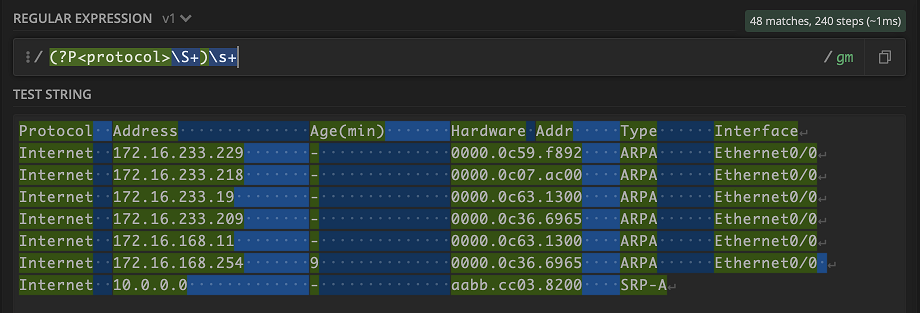
Whoa! Everything lit up. But really that makes sense, given what \S+ means. Don’t fret though, let’s keep going. Next is the whitespace that we can capture \s+
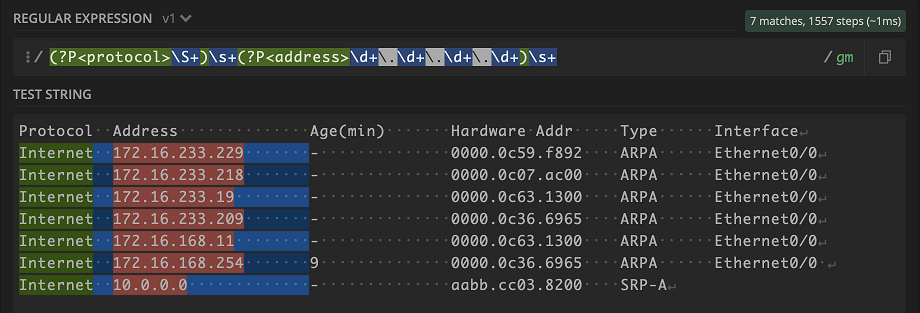
Let’s move on to the value under address Address. We can use the handy \d+ to grab any digit one or more times and use \. to backslash out the . in the IPv4 address.
Keep in mind that using \d+ is just a quick way to represent one octet in an IPv4 address. If you are validating user input, you might want to be more precise with the pattern. We can use it in this case because a network device should not output any weird IPv4 address like 999.999.999.999.
But awesome—look at that! For the next few values, I’m going to use our friend \S+ and match the names of our keys to the headers in the output. Remember to include the \s+ for the whitespace in between values.
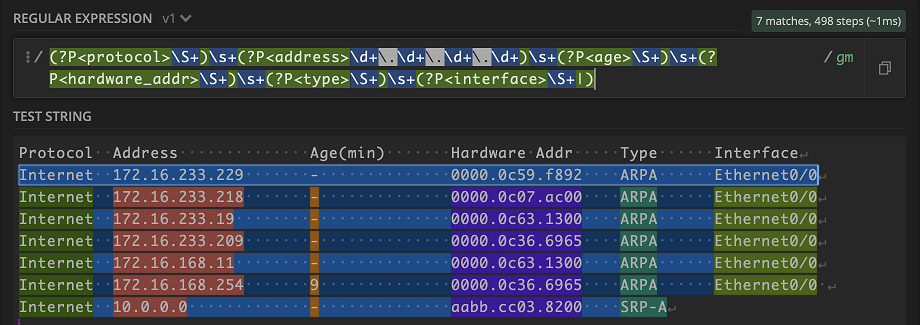
Looking good! That last line isn’t working because Interface has a case where there may be no output. No worries, we can account for this by using the | for cases with no output.
Awesome! Our final pattern can now match an entire line of different patterns!
Contributing to Projects
I hope that was fun! If this at all interested you, I encourage you to take a look at the contribution pages for NTC Templates and Cisco Genie Parser. Both projects use Regex in very different ways, so you’re going to have to get a little familiar with the particular project you want to contribute to before starting your first parser. Cisco Genie Parser uses the Regex library that is built into Python, which is what we walked through in the example above. NTC Templates leverages TextFSM, which has a language all its own. A lot of the same concepts apply, you just may need to get yourself familiar with TextFSM before starting.
Go More in Dept
If you want to go little more in depth than what we did here, again, Mikhail Yohman has an entire series on different parsing strategies and even talks specifically about both NTC Templates and Cisco Genie Parser.
Knox Hutchinson also has an awesome video on Genie Parser from SCRATCH, in which he walks you through the entire process of making the parser and actually creating a pull request to have it merge into the source code.
Conclusion
I hope you enjoyed this quick peek into the wonderful world of parsers. This post is just meant to give you some inspiration to make your first contribution to an open source project. It can be a rewarding and fulfilling process that I think every engineer should experience in their career. Thanks for reading, and I look forward to seeing whatever you create!
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Thank you for joining me for Part 2 of the parsing strategies blog series. This post will dive deeper into using NTC Templates to parse unstructured data into usable, structured data. NTC Templates uses TextFSM under the hood to be able to parse the data obtained from traditional networking devices by using Regular Expressions (RegEx). We will go over what a TextFSM template looks like, how it works, and how we can use the template in Ansible to perform topology assertions against our lab topology.
TextFSM Primer
TextFSM was created by Google to process semi-structured data from network devices into structured data that can be easily accessed programmatically. TextFSM is a Domain Specific Language (DSL) using RegEx under the hood to parse the data. This means that some RegEx knowledge is required, but there are helpful websites such as https://regexr.com or https://regex101.com that can help get you started with understanding RegEx. These websites are a great help when it comes troubleshooting my TextFSM templates and why something may not be capturing the way I would expect it to.
Let’s take a look at a TextFSM template and then break it down to better understand how TextFSM works. Below is the cisco_ios_show_lldp_neighbors.textfsm template from NTC Templates that we will be using for this post.
Value Required NEIGHBOR (\S{0,20})Value Required LOCAL_INTERFACE (\S+)Value CAPABILITIES (\S*)Value Required NEIGHBOR_INTERFACE (\S+)Start^Device.*ID -> LLDP # Capture time-stamp if vty line has command time-stamping turned on^Load\s+for\s+^Time\s+source\s+isLLDP^${NEIGHBOR}\s*${LOCAL_INTERFACE}\s+\d+\s+${CAPABILITIES}\s+${NEIGHBOR_INTERFACE}-> Record^${NEIGHBOR}^\s+${LOCAL_INTERFACE}\s+\d+\s+${CAPABILITIES}\s+${NEIGHBOR_INTERFACE}-> Record
We’ll cover the template it more detail below, but I want to show you what the raw data looks like and how it looks after it has been parsed with TextFSM.
Capability codes: (R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device (W) WLAN Access Point, (P) Repeater, (S) Station, (O) OtherDevice ID Local Intf Hold-time Capability Port IDS2 Fa0/13120 B Gi0/13Cisco-switch-1 Gi1/0/7120 Gi0/1Juniper-switch1 Gi2/0/1120 B,R 666Juniper-switch1 Gi1/0/1120 B,R 531Total entries displayed:4
Here is the output returned after parsing semi-structured data using NTC Templates.
As you can see in the output we received, the Value in the template is used as the key (column) in each dictionary (row) that is returned.
There are a few keywords that can modify how the value is processed, such as the following:
Required: The record (row) is only saved into the table if this value is matched.
Filldown: The previously matched value is retained for subsequent records (unless explicitly cleared or matched again). In other words, the most recently matched value is copied to newer rows unless matched again.
List: The value is a list, appended to on each match. Normally a match will overwrite any previous value in that row.
Key: Declares that the field’s contents contribute to the unique identifier for a row. This can be used to tie data from multiple templates together into a single structure.
Fillup: Like Filldown, but populates upwards until it finds a non-empty entry. Not compatible with Required.
At the end of the line is where we will specify the RegEx that will match our semi-structured text for that specific Value. Depending on the data, this can be as generic as \S+, when the data is well known, or as complex as needed.
\S+ matches any non-whitespace which requires the data to either be controlled or well known as stated above.
To recap what we just discussed, here is a breakdown of a Value line: Value {KEYWORD} {VALUE_NAME} (RegEx).
States
The State definitions come after the Value definitions and are separated from the values by a blank line. The lines indented after each State are the state rules that are specified to match the Value definitions specified at the beginning of the template. States are helpful to break up your template into easier to read chunks if the semi-structured data is complex. There is no upper limit to the amount of states you have in your TextFSM template, but Start is always required.
State Rules
The rules define the lines we want to capture with the Value definitions at the beginning of the template. Each rule line must start with a carat (^). The rules don’t have to end with a -> rule action, but it might be required depending on the data. The -> denotes a rule action and tells TextFSM what to do with the data captured up to this point. We will discuss the rule actions shortly. The values are denoted by ${VALUE_NAME} within the state rules which will be expanded out with the RegEx from the Value definition.
Keep in mind that the whole line does not have to be RegEx or values (${NEIGHBOR}), but can also be regular text to match on. Behind the scenes, TextFSM converts each rule to a complete RegEx string. If we take a look at the first line under the LLDP state, it would look like the following behind the scenes: ^(\S{0,20})\s*(\S+)\s+\d+\s+(\S*)\s+(\S+)
The state rule does not have to match the whole line which we can see within our template with the ` . ^Load\s+for\s+, which will match any line that starts with Load for `.
Rule and Line Actions
Rule actions can be applied per state rule line, but will affect the behavior and the placement within the states must be considered carefully. There are line actions which tell TextFSM to do with the current line while it’s processing and then rule actions tell TextFSM what to do with the captured values. Per the default action, any line that does not contain a ->, is Next.NoRecord. To better understand this, let’s dive into what options we have when it comes to using the line and rule actions by specifying ->.
Line Actions
Next (Default): Finish with the input line, read in the next line and start matching again from the start of the state. This is the default behavior if no line action is specified.
Continue: Retain the current line and do not resume matching from the first rule of the state. Continue processing rules as if a match did not occur (value assignments still occur).
Using the Continue line action is not a common use case when building a template, but taking a look at the cisco_ios_show_vlan.textfsm shows a use case when you want to capture multiple values that are on the same line.
Here is an example of the template:
Value List INTERFACES ([\w\./]+)..omitted for brevityVLANS^\d+-> Continue.Record^${VLAN_ID}\s+${NAME}\s+${STATUS}\s*$$^${VLAN_ID}\s+${NAME}\s+${STATUS}\s+${INTERFACES},*-> Continue^\d+\s+(?:\S+\s+){3}${INTERFACES},*-> Continue^\d+\s+(?:\S+\s+){4}${INTERFACES},*-> Continue^\d+\s+(?:\S+\s+){5}${INTERFACES},*-> Continue^\d+\s+(?:\S+\s+){6}${INTERFACES},*-> Continue^\d+\s+(?:\S+\s+){7}${INTERFACES},*-> Continue
Here is an example of the semi-structured data that will be parsed:
By using the Continue for each line, we can keep the value we captured, as well as the line it’s currently processing, and then move onto the next state rule within the State to capture the additional values on the line.
This means our structured data will look like the following:
NoRecord (Default): Do nothing. This is the default behavior if no record action is specified.
Record: Record the values collected so far as a row in the return data. Non Filldown values are cleared. Note: No record will be output if there are any ‘Required’ values that are unassigned.
Clear: Clear non Filldown values.
Clearall: Clear all values.
State: Transition to a different state.
Error: This is a built-in state and will discard any captured values and return an exception.
We use the Error rule action to help troubleshoot our templates and make sure our templates are accounting for the correct data. Here is the way we use it: ` ^. -> Error`, which will provide an exception with the line that does not match any defined state rule. If you have any other questions, we provide a FAQ
` -> Continue.State` is not allowed to prevent loops within TextFSM.
If we look at the template, under the LLDP state, we see two -> Record options within it. This allows us to capture the appropriate values, but by parsing slightly different output.
We’re also able to combine the line action with the rule action. The syntax for this is LineAction.RuleAction. You can take a look at this template to see it in action and look at the raw data to get a better idea of how it’s being used.
Hopefully this overview of TextFSM provides a clearer picture when deciphering a template or when you start to create your own. Let’s move onto a quick overview of the topology and then get right into our verification playbook.
The definitions provided for value keywords, line and rule actions above were taken from the Google TextFSM wiki.
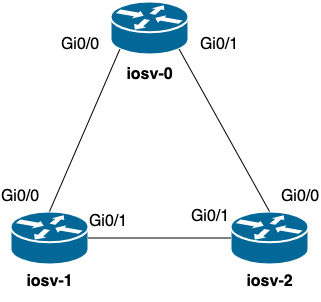
The Topology
Below is a picture of the topology we will be using to validate LLDP neighbors within our lab topology. This is a simple topology with three Cisco IOS routers that are connected together and have LLDP enabled.
Ansible Setup
Luckily our topology and the subsequent inventory will both be simple. We have the routers in a group called ios which then has a corresponding ios.yml file within the group_vars folder that has variables pertinent to connecting to these devices that I will show shortly. We then have {hostname}.yml files for each router that hold the approved_neighbors variable that we will use to validate the neighbors we see from our parsed LLDP data. Below is the tree of our directory that contains the Ansible playbook and inventory.
Here is the contents of ios.yml file. This specifies the user we want to connect to the routers with a well as the ansible_network_os to tell Ansible what kind of networking device we will be connecting to.
If you notice, this is different than Ansible <= 2.9 syntax and uses a path to cisco.ios.ios rather than just ios. This is because we’re running Ansible 2.10 and migrating to using the syntax that Ansible will be enforcing in the future. You will notice some differences with using Ansible 2.10 in our playbook as well.
Now let’s take a look at pb.validate.neighbors.yml.
----hosts:"ios"connection:"ansible.netcommon.network_cli"gather_facts:"no"tasks:-name:"PARSE LLDP INFO INTO STRUCTURED DATA" ansible.netcommon.cli_parse:command:"show lldp neighbors"parser:name: ansible.netcommon.ntc_templatesset_fact:"lldp_neighbors"-name:"ASSERT THE CORRECT NEIGHBORS ARE SEEN"assert:that:-"lldp_neighbors | selectattr('local_interface', 'equalto', item['local_intf']) | map(attribute='neighbor') | first == item['neighbor']"loop:"{{ approved_neighbors }}"
The playbook starts off with defining our hosts as the ios group in our inventory file which consists of our three IOS routers. The connection method uses the >= Ansible 2.10 syntax for network_cli and we have disabled gathering facts.
Let’s breakdown the two tasks we’re using to assert our operational data for LLDP neighbors matches the defined approved_neighbors variable we have for each host.
The first task uses the ansible.netcommon.cli_parse module to run the command against the device and then parse the data with our defined ansible.netcommon.ntc_templates parser. This output is saved as lldp_neighbors due to the set_fact directive on the task.
If you’re looking to run this same playbook, make sure you have ntc-templates installed via pip install ntc-templates.
The next task will loop over our approved_neighbors variable and then attempt to find a match in our parsed data by looking for an entry that has a value for the key local_interface that matches what we have set for local_intf in approved_neighbors and that the neighbor key also matches our neighbor value. Our playbook will fail if any of the neighbors do not match what we have defined in approved_neighbors.
The way Ansible is evolving and the methodologies we have used within the playbook do not limit the playbook’s potential to just ios and we can in fact swap out the ios hosts definition for all or any number of groups and hosts that are multivender. This is due to the magic behind the scenes that ansible.netcommon.cli_parse is performing with the ansible_network_os variable we set in group vars. It uses that variable to determine which nos_command module to run to connect to the device and which template to use to parse the returned data.
Playbook Output
Let’s go ahead and run the playbook and see what output we get.
I ran this playbook with some verbosity to be able to show what each task returns and the format of our parsed data.
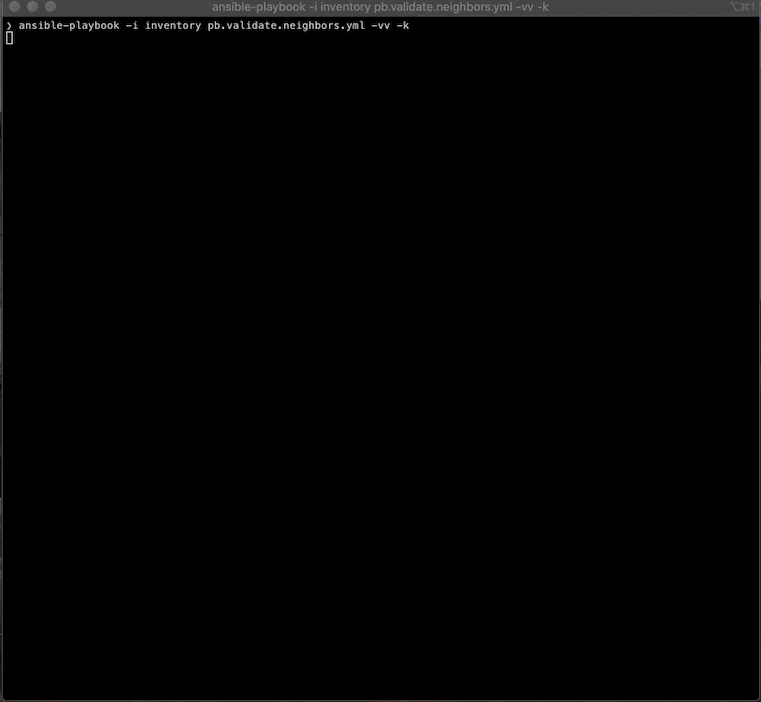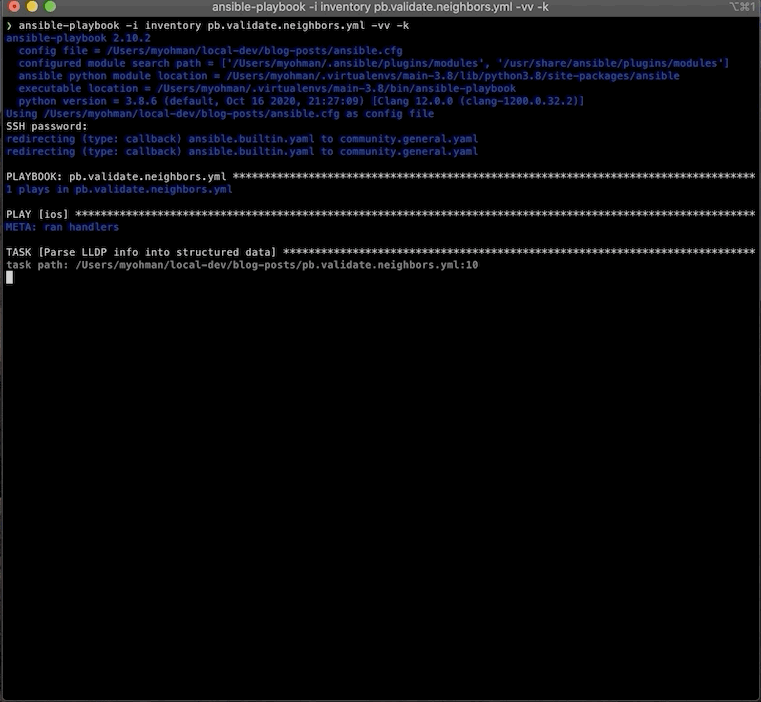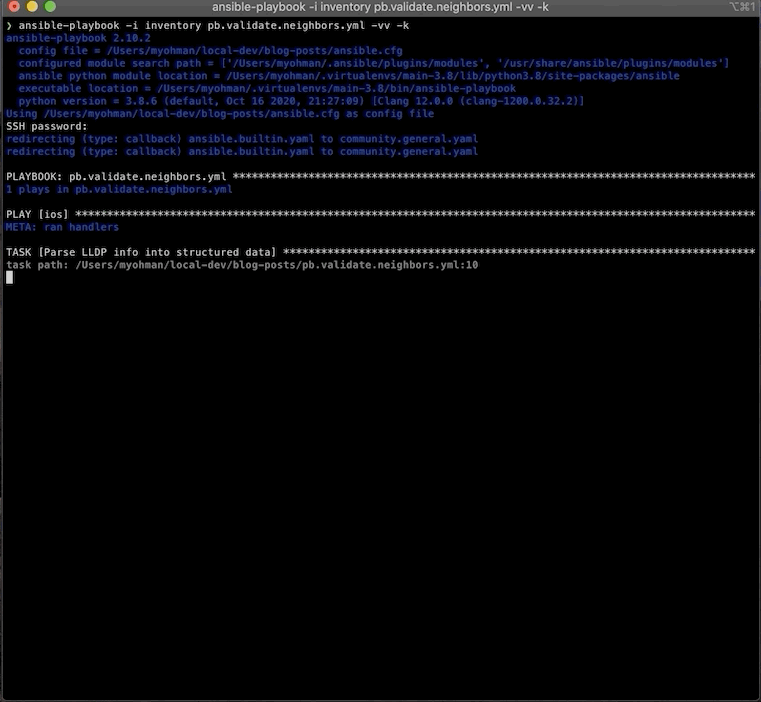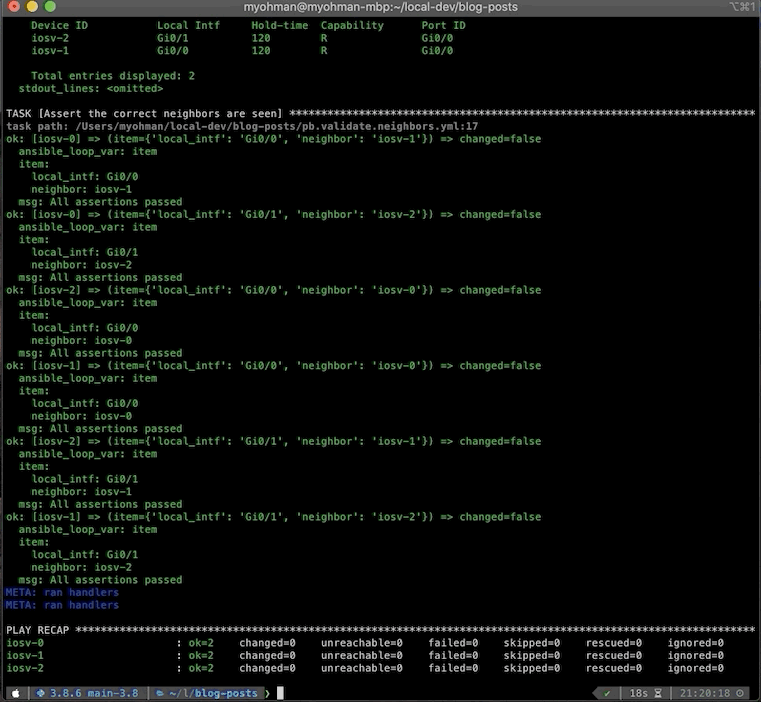
If we take a closer look at the output of the first task, we can see under the parsed key as well as setting the fact (lldp_neighbors), that we have our structured data from running the raw output through NTC Templates.
The second task shows the loop for each host and the item that it is using during the loop. If you look back at our playbook, we’re using both the local_intf and neighbor for our assertions from our approved_neighbors variable.
Conclusion
I hope you enjoyed this blog post and understand a little bit more about TextFSM, NTC Templates, and how easy they are to use with Ansible. The ease of use is not unique to Ansible as this can also easily be achieved with Netmiko or raw Python, but used Ansible due to the industry adoption of Ansible. The next post in this series will be going over PyATS Genie parsing and using it within Ansible. Our biggest change in the next post will be the assertions as the structured data will not be the same as NTC Templates and that is OK. The point of these posts it to help you decide which parsing strategies you can use throughout your journey and which ones may be more suitable for specific situations.
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Welcome to the first post in this series about parsing unstructured data into structured data. When beginning your automation journey, you may start with quick wins that may not need to act upon operational data from show commands, but as you progress quickly through your journey, you will find the need to be able to parse the unstructured data obtained from your devices into structured data.
Unfortunately at this time, not all of us have been able to replace our “legacy” network equipment with all the newer networking products that come with APIs, streaming telemetry, etc. that help us programmatically interact with our network.
There are several parsing strategies that we will cover in greater detail along with methods to consume them:
We’ve covered parsing lightly in previous posts that use the parsing of unstructured data such as this post, to transform the data into something useable by other systems. This series will take us deeper into the “how” of parsing unstructured data.
Before we start diving too deep into the implementations, let’s discuss why parsing unstructured data into structured data is beneficial.
Why Do I Need Structured Data From My CLI?
Parsing is the act of translating a language (unstructured data that humans can easily read) to another language (structured data that a computer can easily read). Below is an example of how we’d do some form of validation with unstructured data:
>>> unstructured_data ="""... Capability codes:... (R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device... (W) WLAN Access Point, (P) Repeater, (S) Station, (O) Other...... Device ID Local Intf Hold-time Capability Port ID... S2 Fa0/13120 B Gi0/13... Cisco-switch-1 Gi1/0/7120 Gi0/1... Juniper-switch1 Gi2/0/1120 B,R 666... Juniper-switch1 Gi1/0/1120 B,R 531...... Total entries displayed:4""">>> neighbors = [..."S2",..."Cisco-switch-1",..."Juniper-switch1",]>>> for neighbor inneighbors:...if neighbor inunstructured_data:...print(f"{neighbor} on router")S2 on routerCisco-switch-1 on routerJuniper-switch1 on router>>> neighbors = [...{"name":"S2","intf":"Fa0/13"},...{"name":"Cisco-switch-1","intf":"Gi1/0/7"},...{"name":"Juniper-switch1","intf":"Gi2/0/1"},...{"name":"Juniper-switch1","intf":"Gi1/0/1"},... ]>>> for neighbor inneighbors:... for cfg_line in unstructured_data.splitlines():...if neighbor["name"] in cfg_line and neighbor["intf"] incfg_line:...print(f"Neighbor {neighbor["name"]} is seen on {neighbor["intf"]}")Neighbor S2 is seen on Fa0/13Neighbor Cisco-switch-1 is seen on Gi1/0/7Neighbor Juniper-switch1 is seen on Gi2/0/1Neighbor Juniper-switch1 is seen on Gi1/0/1
Luckily, we can parse this data and perform meaningful comparisons on the data once we have transformed it into structured data. This gives us the ability to assert, with confidence, that the neighbors that are seen match the expected interfaces. This check can be critical in making sure that the correct configuration exists on the correct interfaces for each device.
Here is a short list that provides a few use cases as to why you may want to turn your unstructured data into structured data.
The ability to store the structured data in a Time Series Database (TSDB) for telemetry and analytics that can help you quickly determine the root cause of an issue that the network is experiencing.
Perform specific actions depending on the operational data you retrieved from the device such as bringing down an interface or bringing up a BGP peer.
Making sure each device is compliant operationally, such as determining that each device is seeing the proper neighbors on each of it’s interfaces.
Summary
Each of the following posts will work with the unstructured LLDP data obtained from csr1000v routers and used to assert that the neighbors that the device sees are valid neighbors per a variable we will define within the next post. This will help to determine which neighbors we’re expecting to see connected to each router. We will want to do two different checks; that each neighbor is what we are expecting to see, and that there aren’t any extra neighbors that we’re not expecting to see.
After reading these posts, you should be able to parse any unstructured data obtained from devices into structured data that is meaningful to you along your network automation journey!
Conclusion
The next post in this series will go over the topology we’ll be using throughout this series and take a dive into NTC Templates with Ansible.
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. In case of sale of your personal information, you may opt out by using the link Do not sell my personal information. Privacy | Cookies
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
__hssc
30 minutes
HubSpot sets this cookie to keep track of sessions and to determine if HubSpot should increment the session number and timestamps in the __hstc cookie.
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie records the user consent for the cookies in the "Advertisement" category.
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
CookieYes sets this cookie to record the default button state of the corresponding category and the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Cookie
Duration
Description
__cf_bm
30 minutes
Cloudflare set the cookie to support Cloudflare Bot Management.
li_gc
5 months 27 days
Linkedin set this cookie for storing visitor's consent regarding using cookies for non-essential purposes.
lidc
1 day
LinkedIn sets the lidc cookie to facilitate data center selection.
UserMatchHistory
1 month
LinkedIn sets this cookie for LinkedIn Ads ID syncing.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__hstc
5 months 27 days
Hubspot set this main cookie for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
1 year 1 month 4 days
Google Analytics sets this cookie to calculate visitor, session and campaign data and track site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognise unique visitors.
_gat_gtag_UA_*
1 minute
Google Analytics sets this cookie to store a unique user ID.
_gid
1 day
Google Analytics sets this cookie to store information on how visitors use a website while also creating an analytics report of the website's performance. Some of the collected data includes the number of visitors, their source, and the pages they visit anonymously.
AnalyticsSyncHistory
1 month
Linkedin set this cookie to store information about the time a sync took place with the lms_analytics cookie.
CONSENT
2 years
YouTube sets this cookie via embedded YouTube videos and registers anonymous statistical data.
hubspotutk
5 months 27 days
HubSpot sets this cookie to keep track of the visitors to the website. This cookie is passed to HubSpot on form submission and used when deduplicating contacts.
ln_or
1 day
Linkedin sets this cookie to registers statistical data on users' behaviour on the website for internal analytics.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
bcookie
1 year
LinkedIn sets this cookie from LinkedIn share buttons and ad tags to recognize browser IDs.
bscookie
1 year
LinkedIn sets this cookie to store performed actions on the website.
li_sugr
3 months
LinkedIn sets this cookie to collect user behaviour data to optimise the website and make advertisements on the website more relevant.
VISITOR_INFO1_LIVE
5 months 27 days
YouTube sets this cookie to measure bandwidth, determining whether the user gets the new or old player interface.
YSC
session
Youtube sets this cookie to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the user's video preferences using embedded YouTube videos.
yt-remote-device-id
never
YouTube sets this cookie to store the user's video preferences using embedded YouTube videos.
yt.innertube::nextId
never
YouTube sets this cookie to register a unique ID to store data on what videos from YouTube the user has seen.
yt.innertube::requests
never
YouTube sets this cookie to register a unique ID to store data on what videos from YouTube the user has seen.