

This post, the second in a series focused on using Telegraf, Prometheus, and Grafana for Network Telemetry, will focus on transforming data and making additional graphs within Grafana. This post will cover the following topics:
Here is where you can find the first post in the series on how to gather data from SNMP based devices.
The intent of this post is to demonstrate how to bring multiple telemetry gathering methods into one. In our experience, a successful telemetry & analytics stack should be able to collect data transparently from SNMP, telemetry Streaming (gNMI) and CLI/API. We covered SNMP and CLI gathering in previous posts. This post will focus on gathering telemetry data with gNMI. Beyond the collection of data, when we are collecting the same type of data from multiple sources it’s important to ensure that the data will have the format in the database. In this post, we’ll look at how Telegraf can help normalize and decorate the data before sending it to the database.
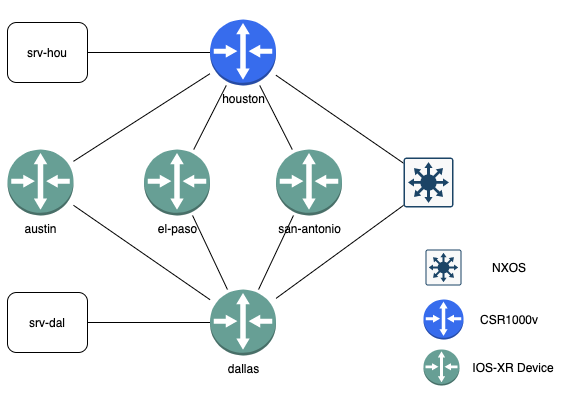
In the topology there is a mix of devices per the table below:
| Device Name | Device Type | Telemetry Source |
|---|---|---|
| houston | Cisco IOS-XE | SNMP |
| amarillo | Cisco NXOS | SNMP |
| austin | Cisco IOS-XR | gNMI |
| el-paso | Cisco IOS-XR | gNMI |
| san-antonio | Cisco IOS-XR | gNMI |
| dallas | Cisco IOS-XR | gNMI |
This blog post was created based on a Cisco-only environment, but if you’re interested in a multi-vendor approach check out @damgarros’s NANOG 77 presentation on YouTube. That video shows how to use only gNMI to collect data from Arista, Juniper, and Cisco devices in a single place. This topology used here is meant to show the collection from multiple sources (SNMP + gNMI) in one.
Software installation was covered in the previous post in this series, and I recommend taking a look at either that post for the particular installation instructions, or heading over to the product page referenced in the introduction.
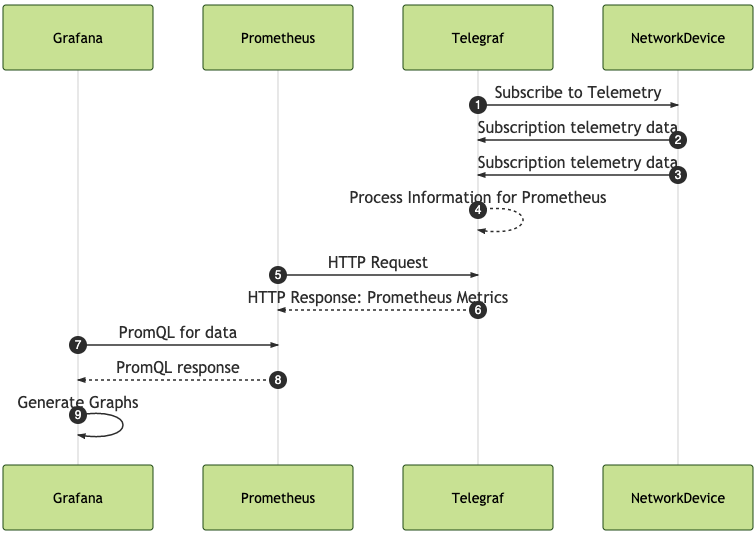
Here is the sequence of events that is being addressed in this post. I am starting with Telegraf gathering and collecting gNMI data from network devices. This is being processed into Prometheus metrics that will be scraped by a Prometheus server. Then Grafana will generate graphs on the data that is gathered and processed appropriately.
gNMI stands for gRPC (Remote Procedure Calls) Network Management Interface. gRPC is a standard developed by Google that leverages HTTP/2 for transport using Protocol Buffers. gNMI is a gRPC-based protocol to get configuration and telemetry from a network device. All messages are defined as protocol buffers that intend to keep data as small as possible in the definition to be as efficient as possible. The data is serialized into the proper format by the device and sent off. This can hold quite a bit of information and is read by the receiver. You can take a look at the gNMI reference for more detailed information.
gNMI can handle not only telemetry data that this post is about, but also is intended to transport configuration about the device as well.
So why use gNMI? gRPC is incredibly fast and efficient at transmitting data, and by extension gNMI is also fast and efficient.
gNMI is supported by many of today’s leading network vendors. As an example for configuring a Cisco IOS-XR device here are the configuration lines needed to enable gNMI in this demo environment:
grpc
port 50000
no-tls
Pretty straight to the point. If you wish to create a subscription model within the Cisco IOS-XR there are some more detailed configuration options available. Take a look at Cisco’s Guide to Configure Model-driven Telemetry
The first step that I will be walking through is setting up Telegraf to subscribe to gNMI data. This is specifically to collect telemetry data from IOS-XR devices in this lab scenario. With gNMI, like other streaming Telemetry subscriptions, you need to tell the network device that you want to subscribe to receive the data. The device will then send the periodic updates of telemetry data to the receiver. There is a periodic “keep-alive” message sent to keep the subscription active by the subscriber.
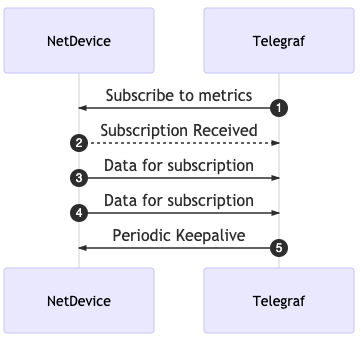
Telegraf has a plugin that will take care of the subscription and the input section looks like the code below. Note that the subscription port is defined within the addresses section.
[[inputs.cisco_telemetry_gnmi]]
addresses = ["dallas.create2020.ntc.cloud.tesuto.com:50000"]
username = <redacted>
password = <redacted>
## redial in case of failures after
redial = "10s"
tagexclude = ["openconfig-network-instance:/network-instances/network-instance/protocols/protocol/name"]
[[inputs.cisco_telemetry_gnmi.subscription]]
origin = "openconfig-interfaces"
path = "/interfaces/interface"
subscription_mode = "sample"
sample_interval = "10s"
[[inputs.cisco_telemetry_gnmi.subscription]]
name = "bgp_neighbor"
origin = "openconfig-network-instance"
path = "/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/state"
subscription_mode = "sample"
sample_interval = "10s"
[[outputs.prometheus_client]]
listen = ":9011"
The configuration shows that you define the address, username, and password. This configuration also shows a redial setup in case of a failure and particular subscriptions to be excluded from the request.
There are two subscriptions that we are subscribing to in this instance:
In each of these cases the sampling will be every 10 seconds in this demo, which means that the device will send the statistics every 10 seconds. Every 10 seconds there will be new metrics available to be scraped by Prometheus. The sample interval and Prometheus scrape interval should be the same interval.
To collect the telemetry for this demo we are once again using the Prometheus client output from Telegraf. Telegraf will collect, process, and format the data that will then be scraped by a Prometheus server. Let’s take a look at what that output looks like next.
I’m only going to take a look at a few of the items in the output here. There are too many that would fill up too much real estate in your screen to make it worthwhile.
# HELP bgp_neighbor_messages_received_UPDATE Telegraf collected metric
# TYPE bgp_neighbor_messages_received_UPDATE untyped
bgp_neighbor_messages_received_UPDATE{device="dallas",identifier="BGP",name="default",neighbor_address="10.0.0.1",peer_type="EXTERNAL",role="leaf"} 9
bgp_neighbor_messages_received_UPDATE{device="dallas",identifier="BGP",name="default",neighbor_address="10.0.0.17",peer_type="EXTERNAL",role="leaf"} 0
bgp_neighbor_messages_received_UPDATE{device="dallas",identifier="BGP",name="default",neighbor_address="10.0.0.25",peer_type="EXTERNAL",role="leaf"} 9
bgp_neighbor_messages_received_UPDATE{device="dallas",identifier="BGP",name="default",neighbor_address="10.0.0.9",peer_type="EXTERNAL",role="leaf"} 9
Some items were removed to assist in readability and message delivery
The output is what you would expect. A list of the neighbors identified by the neighbor_address key in the tags. With the BGP subscription you get:
There are a lot of statistics sent back with the interface subscription. We’ll be taking a look at just one of them, interface_state_counters_in_octets, in this instance. We get a look at each interface and its associated counter in the data.
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/0",role="leaf"} 3.2022595e+07
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/1",role="leaf"} 3.077077e+06
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/2",role="leaf"} 1.5683204947e+10
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/3",role="leaf"} 1.627459e+06
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/4",role="leaf"} 1.523158e+06
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/5",role="leaf"} 35606
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/6",role="leaf"} 35318
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/7",role="leaf"} 35550
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/8",role="leaf"} 35878
interface_state_counters_in_octets{device="dallas",name="GigabitEthernet0/0/0/9",role="leaf"} 36684
interface_state_counters_in_octets{device="dallas",name="MgmtEth0/RP0/CPU0/0",role="leaf"} 2.2033861e+07
interface_state_counters_in_octets{device="dallas",name="Null0",role="leaf"} 0
interface_state_counters_in_octets{device="dallas",name="SINT0/0/0",role="leaf"} 0
This is great information, and we have seen something similar with SNMP. Now to the transformations that Telegraf offers.
Telegraf has a couple of different processors available to process the data and get it into a format that is appropriate and consistent for your environment. Let’s take a look at a couple of them and how they are used in the use case here.
The first processor used is within the BGP data collection. When the data comes back from the subscription for a BGP session state, it comes back as a string value. It is great to be able to read the current state, but is not very helpful for a Time Series Data Base (TSDB). A TSDB is looking to get the data back represented as a number of some sort, either an integer or a float. The whole point is to measure information at a point in time.
The Telegraf process then looks like this:

To accommodate this, the use of the enum processor is put into action. The following is added to the configuration:
[[processors.enum]]
[[processors.enum.mapping]]
## Name of the field to map
field = "session_state"
[processors.enum.mapping.value_mappings]
IDLE = 1
CONNECT = 2
ACTIVE = 3
OPENSENT = 4
OPENCONFIRM = 5
ESTABLISHED = 6
Within the session_state any instances of the string IDLE will be replaced with the integer 1. This is then set up to store for the long term within a TSDB. This is the same then for all of the rest of the states as well, with ESTABLISHED states stored as the integer 6. Later in Grafana this number will be reversed into the word for representation on a graph.
The second processor that is used in this demo is the rename processor. This rename processor has a function to replace items. Below is what is used to rename the SNMP counters that are collected for SNMP devices and moved to match the names for gNMI.
[[processors.rename]]
[[processors.rename.replace]]
field = "ifHCInOctets"
dest = "state_counters_in_octets"
[[processors.rename.replace]]
field = "ifHCOutOctets"
dest = "state_counters_out_octets"
This states that if looking for ifHCInOctets – replace the field with state_counters_in_octets. And the same for the outbound with ifHCOutOctets replacing with state_counters_out_octets. Once Telegraf has replaced those fields, you can use the data gathered with SNMP and that with gNMI in the same queries!
Tagging data is one of the biggest favors that you can do for yourself. Tagging gives flexibility for future analysis, comparison, and graphing data points. For instance if you tag your BGP neighbors with the upstream peer provider, you will be able to easily identify the interfaces which belong to that particular peer. If you have four geographically diverse interfaces, this will allow you to quickly identify the interfaces based on the tag rather than manually deciding later at the time of graphing or alerting.
This brings us to the third Telegraf processor in this post regex processor. This processor will take a regex search pattern, and complete the replacement. Something new here is that if you use the result_key option, a new field will be created and not replace what is there, resulting in a whole new field. This regex replacement will add a new tag for intf_role using server as the definition.
[[processors.regex.tags]]
key = "name"
pattern = "^GigabitEthernet0\/0\/0\/2$"
replacement = "server"
result_key = "intf_role"
Looking at just this particular replacement in the output, there are now additional tags for graphing, alerting, and general data analysis.
interface_state_admin_status{device="dallas",intf_role="server",name="GigabitEthernet0/0/0/2",role="leaf"} 1
interface_state_counters_in_broadcast_pkts{device="dallas",intf_role="server",name="GigabitEthernet0/0/0/2",role="leaf"} 8
Throughout the upcoming Grafana section you will get to see a number of PromQL (Prometheus Query Language) queries. Take a look at the Prometheus.io basics page to get full documentation of the queries that are available. It is these queries that are being executed that will be used by Grafana to populate the data in the graphs.
Through the next several sections you will get to see how to build a dashboard using PromQL and variable substitution, among other topics to build these dashboards on a per device basis. From a device perspective dashboard, these two dashboards look different in the number of interfaces and neighbors displayed, but they are born out of the same dashboard configuration.
First, you’ll need to set up the variable device that is seen on the upper left hand corner of the dashboard. When I first started building dashboards I remember that this may be one of the most important skills when looking to level up your Grafana dashboards, as it will allow you to get significant amount of value while reducing re-work to keep adding additional devices into a panel.
To add a dashboard wide variable follow these steps:
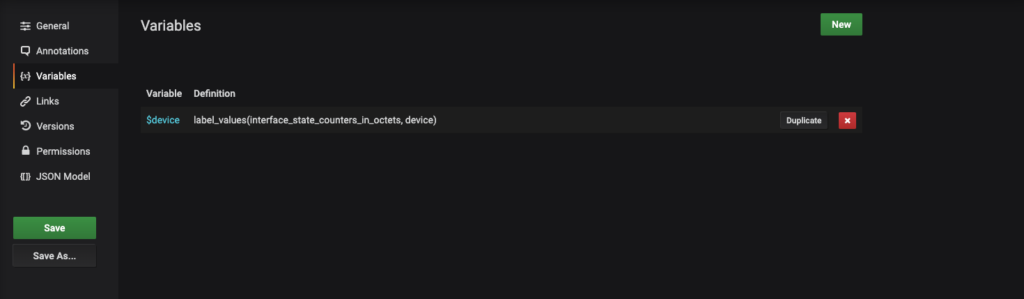
This image already had a variable added, which is the devices
Once in the new screen you will have the following image:
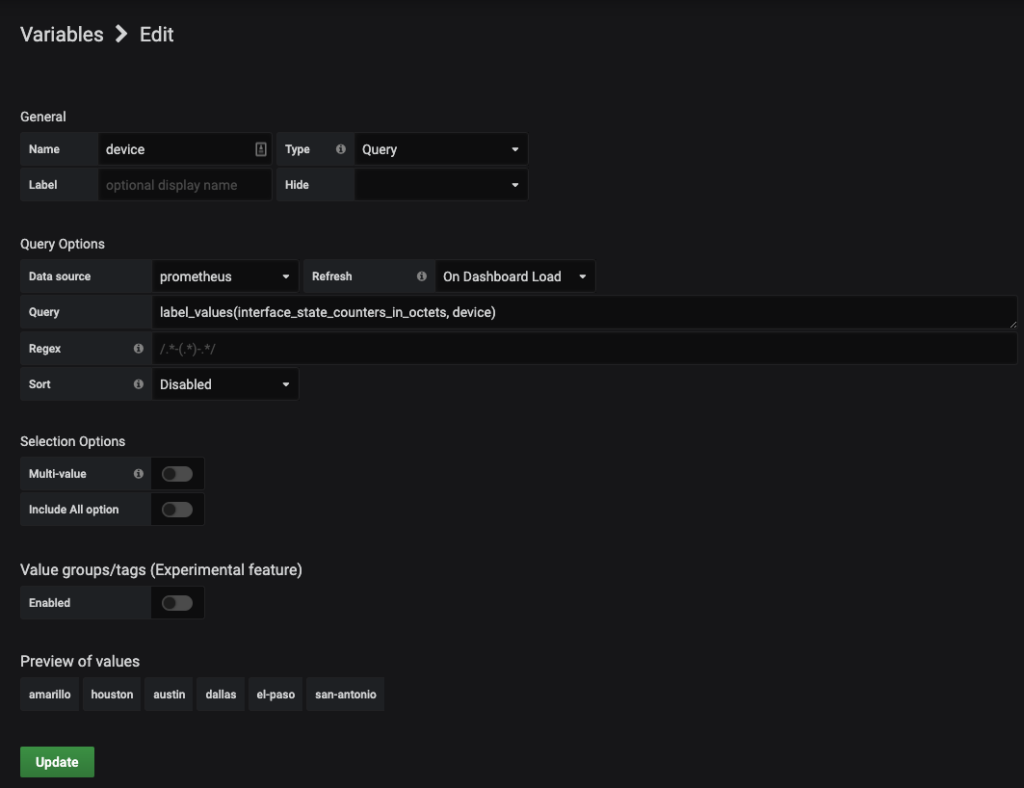
Here you will be defining a PromQL query to build out your device list. In the bottom section of the screen you see the heading of Preview of values. Here you will be able to observe a sample of what the query will result in for your variables.
The fields that you need to fill in include:
| Field | Information Needed |
|---|---|
| Name | Name of the variable you wish to use |
| Type | Query |
| Data source | Prometheus |
| Refresh | When would you like to refresh the variables? Use the dropdown to select which fits your org best |
| Query | PromQL to get the data points |
| Regex | Regex search to reduce the search results |
You can experiment with the rest of the fields as you see fit to get your variables defined properly.
Once you have your search pattern set, make sure to click Save on the left hand side of Grafana.
To reference the variables once they are created, you use the dollar sign ($) in front of the name for Grafana to execute that as a variable within a query. Within the Legend area the use of Jinja-like formatting of the double curly braces will identify as a variable.
Grafana is extensible via the use of plugins. There are quite a few plugins available for Grafana and I encourage you to take a look at the plugin page to be able to search for what you may want to use on your own. There are 3 types of plugins: Panel, Data Source, and App to help extend the Grafana capabilities.
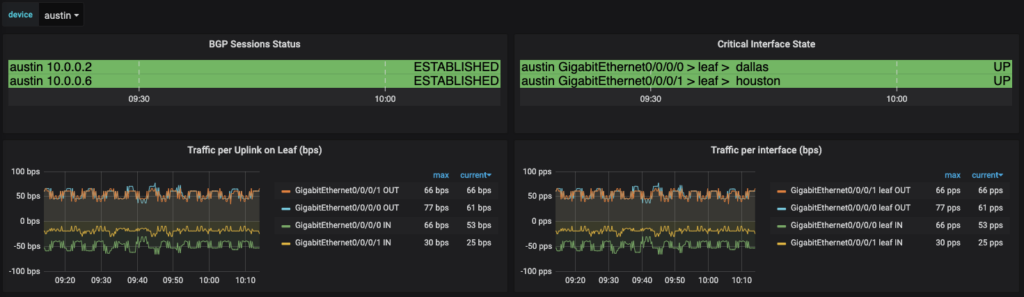
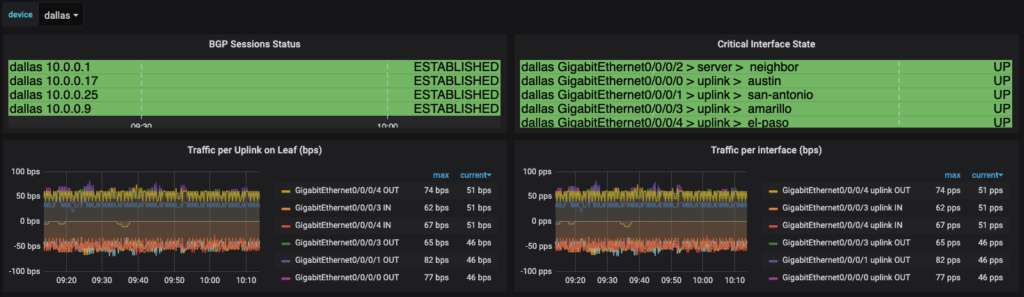
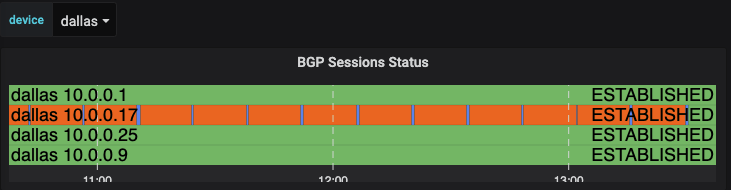
The next table to take a look at is using a feature within Grafana that allows you to add plugins. I’ll look at how we were able to build out the graph. This can help to identify issues quickly in your environment by just looking at the dashboard. Take a look at this where there was a BGP neighbor that was down. It is quickly identifiable on the dashboard and that action will be needed.
The two panels in the top row are using a Grafana plugin called Discrete. This provides data values in the color that is defined within the configuration over time. The panel then gives you the ability to hover over to see the changes over time. You install the plugin with the grafana-cli command:
grafana-cli plugins install natel-discrete-panel
sudo systemctl restart grafana
Once installed you can setup a new panel with the panel type of Discrete.
The panel will be created with the following parameters
Query: Prometheus data source
| Key | Value |
|---|---|
| Metrics | bgp_neighbor_session_state{device=”$device”} |
| Legend | {{ device }} {{ neighbor_address }} |
| Min step | |
| Resolution | 1/1 |
| Format | Time series |
| Instant | Unchecked |
You will note that in the Metrics section the variable reference is $device, noted by the dollar sign in the device name. The Legend has two variables included in both the device and neighbor_address within the Legend. This is what gets displayed in the discrete table for each line.

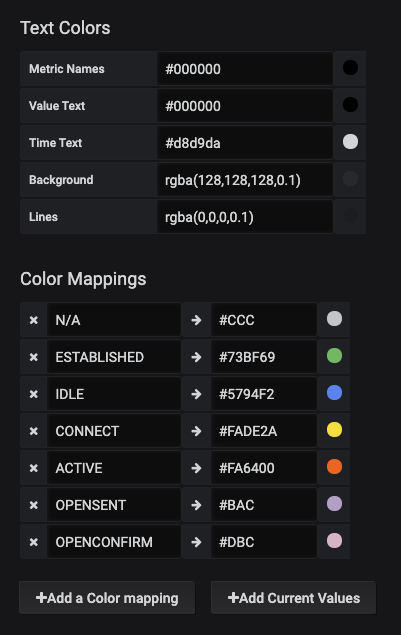
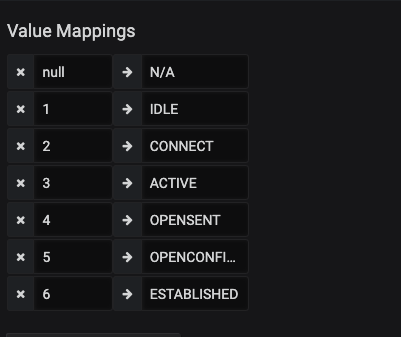
Now because the interfaces have been assigned a label, a discrete panel can be generated to show the interface state, along with the role. For demonstration, we are naming this panel Critical Interfaces, the interfaces for Servers or Uplinks to other network devices have been labeled as with server or uplink accordingly. By querying for any role we can get thi information into the panel. The legend has the value of {{device}} {{name}} > {{intf_role}} > {{neighbor}} to get to the appropriate mappings that are to be shown. This is the resulting panel:

To get to this panel we can see the following discrete panel settings. This panel build is a little bit smaller, but gets a lot of information added into a panel!

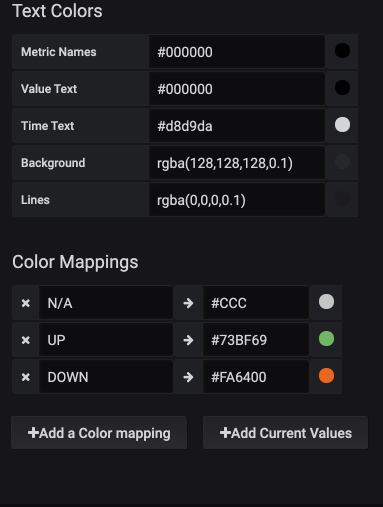
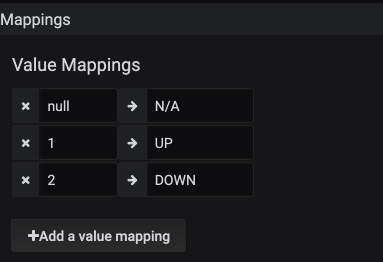
This is not a pick one over the other segment, rather this is saying that both should be present in your Grafana Dashboard setup.
In this post I have gone through and shown a lot of device-specific panels. The value here is that you are able to get to a device by device-specific view very quickly, without having to create a separate page for each and every device in your environment. That said, that the panels can be expanded by the use of variables to identify individual devices.
You should also look at using an environment dashboard where you are getting specific pieces of information to match your need. Need to know what an application performance looks like that includes Network, Server, Storage, and Application performance? You can work to build out these dashboards by hand, but this will take longer to build. As you leverage tags in the gathering of telemetry into your TSDB, you will be on your way to building dashboards in an automated fashion to get the big picture very quickly.
Hopefully this has been helpful. Again, check out the first post in the series if you need more information on these tools generally. In the next post, I will cover how to advance your Prometheus environment with monitoring remote sites and a I’ll discuss a couple of methodologies to enable alerting within the environment.
The next post will include how to alert using this technology stack.
-Josh
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.






Share details about yourself & someone from our team will reach out to you ASAP!