Blog Detail


Over the last two years, in our Telemetry blog posts series we discussed many telemetry and observability concepts, showing characteristics of modern network telemetry. The telemetry stack and its architectural components: collector, database, visualization, and alerting make the network telemetry and observability the real evolution of the network monitoring. You probably also already heard from us about Telegraf, Prometheus, Data Enrichment, and Data Normalization. Each of these functions has been already introduced in our blog series.
Introduction to Architecture of the Network Telemetry and Observability
In this blog post, we will focus on the Architecture of Telemetry and Observability. Over the last years at Network to Code we developed the Network Automation Framework, which is also composed of the Telemetry & Observability element. The Network Telemetry and Observability stack is a critical piece of any network automation strategy and is a prerequisite to building advanced workflows and enabling event-based network automation. While I mentioned a few of the tools above, it is important to note that not every telemetry stack is the same, the elements are composable. Due to rapid development growth, many interesting and valuable tools have been made available in the last years.
While we introduced the architecture elements: collector, database, visualization, please refer for the details in Nikos’ blog post. In this particular blog, let’s discuss what we take into consideration while architecting a telemetry and observability solution.
The process of architecting a telemetry system starts with the analysis of requirements. Most common challenges with respect to the telemetry systems are as follows:
- Heterogeneous data – data coming from different sources, in different formats (CLI, SNMP, gNMI, other)
- Quality of the data within telemetry system (e.g., decommissioned devices, lack of normalization and enrichment)
- Quality of the exposed data (i.e., lack of meaningful dashboards)
- Lack of correlation between events
- Number of tools involved (including legacy, not deprecated)
- System configuration overhead (i.e., missing devices)
As you might notice, most of our challenges are due to data quality or complexity, not necessarily due to tools or software used. Those challenges are often the triggers for the telemetry system overhaul or even a complete replacement.
Architecting the Telemetry System
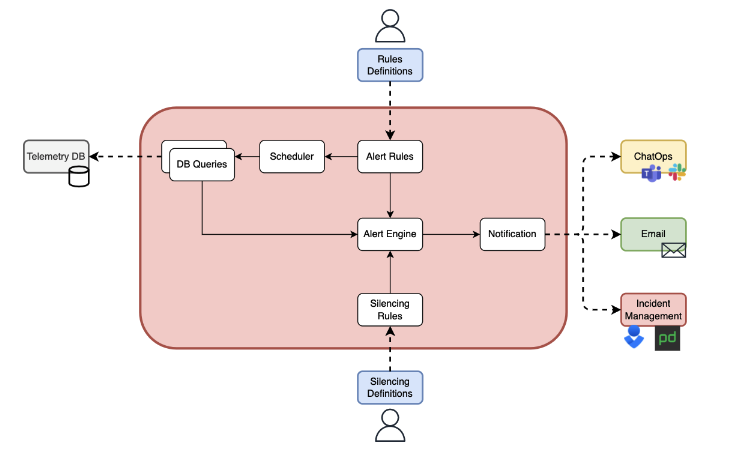
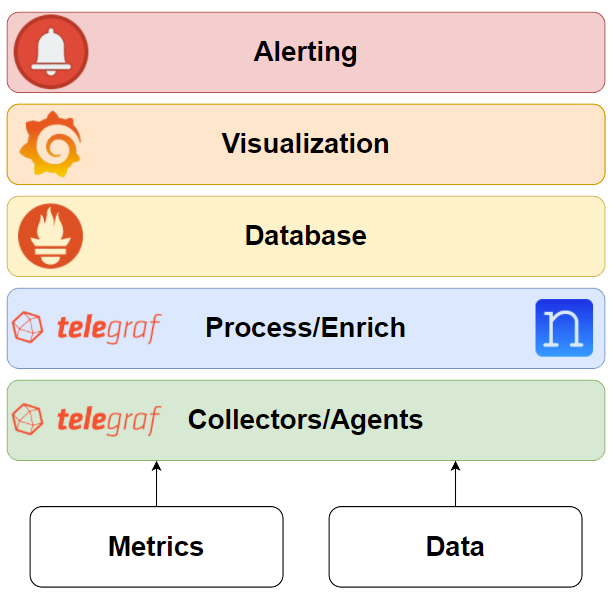
Telemetry Stack Components
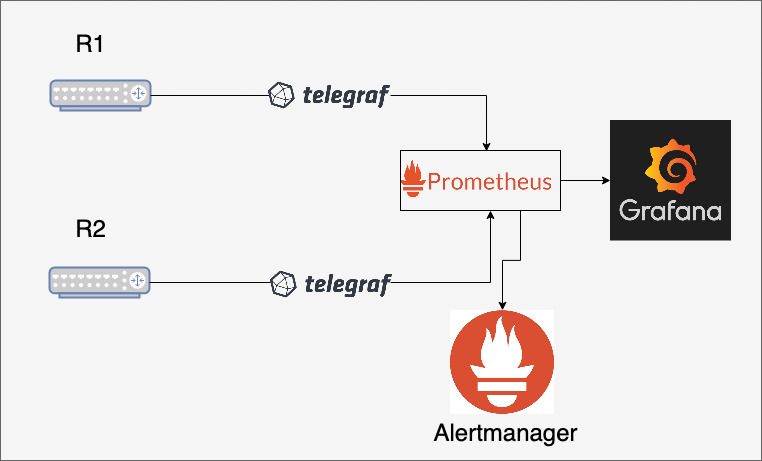
During the architecture process, we follow the stack architecture presented below. We consider the stack as composed of the following elements: collector, database, visualization, and alerting. For the detailed information about each of those, please refer to our previous blog posts.
Understanding Requirements
To start the architecture process, we have to define and understand constraints, dependencies, and requirements. Not every system is the same, each one has unique needs and serves a unique purpose.
Dividing requirements with regard to the specific components allows viewing the system as a set of functions, each serving a different purpose. Below, I present just a set of example requirements; while the list is not full, it might give you ideas about how many architectures we could design with different components fitting the use cases. Telemetry stacks are customizable, each of the functions can be implemented in a number of ways, including the integrations between components.
General Requirements – Examples
- What is the data to be collected? (Logs? Flows? Metrics?)
- What is the extensibility of the designed system?
- What is the scalability of the designed system? Is horizontal scalability needed?
- What is the expected access? (API? UI? CLI?)
- Who will use the system, and how will they use it? (Capacity Planning Team? NOC? Ad hoc users?)
- How will the system’s configuration be generated? (Collectors?)
- How will the system’s load be distributed? (Regional pods?)
- How does the organization deploy new applications?
- How are users trained to use new applications?
Collector
- What is the expected data resolution?
- What is the expected data collection method? (gNMI? SNMP?)
- What is the expected data? (BGP? System metrics?)
- What is the deployment model? (Container on the network device? Stand-alone?)
- Are the synthetic metrics needed?
Data Distribution and Processing
- Which data will be enriched and normalized?
- What are the needed methods to perform data manipulations? (Regex? Enum?)
- How will the data flow between systems? (Kafka?)
- How will the data be validated?
Database
- What is the preferred query language? (Influx? PromQL?)
- What are the backfilling requirements?
- What are the storage requirements? (Retention period?)
- What is the preferred database type? (Relational? TSDB?)
Visualization
- Can we correlate events displayed?
- Can we create meaningful, role-based, useful dashboards?
- Can we automatically generate dashboards? (IaaC?)
- Can we use source-of-truth data (e.g., site names) in the dashboards?
Alerting
- What are the available integrations? (Automation Orchestrator? Email? Slack?)
- How will the alerts be managed?
- Can we use source-of-truth data (e.g., interface descriptions, SLAs) with the alerts?
Designing the System
The process of designing a telemetry system is preceded by understanding and collecting specific requirements, preparing the proof of concept (“PoC”) plan, and delivering the PoC itself. The PoC phase allows for verifying the requirements, testing the integrations, and visually presenting the planned solution. PoC is aligned with the design documentation, where we document all the necessary details of the architected telemetry and observability system. We find answers for and justify all the requirements: constraints, needs, and dependencies.
Implementing the System
Implementing a telemetry system requires us to collaborate with various teams. As we introduce the new application, imagine we have to communicate with:
- Network Engineering (system users)
- Security (access requirements)
- Platform (system deployment and operations)
- Monitoring (system users)
Telemetry and observability systems are critical to every company. We must ensure the implemented system meets all the organization’s requirements. Not only do we have to map existing functionalities into the new system (e.g., existing Alerts), we have to ensure all the integrations work as expected.
Telemetry and observability implementation involves the application deployment and configuration management. To achieve the best user experience through an integration, we can leverage the Source of Truth systems while managing the configurations. This means a modern telemetry and observability solution has the Source of Truth at its center. The configuration files are generated in a programmable way, utilizing data fetched from the SoT system to ensure that only information within the scope of the SoT is used to enrich or normalize the telemetry and observability system.
Using the System
While the system is implemented, we work on ensuring the system is being used properly. There are several use cases for the telemetry and observability, thus some of the usage examples involve:
- Collecting from a new data source or new data (metric)
- Scaling the collector system for a new planned capacity
- Presenting new data on a dashboard or building a new dashboard
- Adding a new alert or modifying an existing one
- Receiving and handling (silencing, aggregating) an alert
Conclusion
As we recognize the potential challenges of any new system being introduced, we ensure the system’s functions are well known for system users. This is critical for telemetry and observability systems, as those typically introduce a set of protocols, standards, and solutions that might be new in a certain environment.
-Marek
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!