Work. The never-ending laundry list of ‘To-Do’ items that greets us every day when we log on to our computer. Tasks seem to multiply in request queues faster than a soaking wet gremlin, yet they seem to eclipse the small delivery of items being completed.
We all have requests sitting in our work queues aging from days to weeks or months from their submission date. So how do we begin to make sense on which items can or should be done now? Is it better to tackle the quick wins by going after the low-hanging fruit? Or is it better to go after the larger corporate wins that may be more time-consuming but have the potential for a great impact? More importantly, how would we address unplanned activities (aka fire drills) or ever find the time to get to those bothersome back burner activities? These are some of the questions we will uncover as part of this blog series on work intake.
What Is Work Intake?
Work intake is a way of gathering requirement details to begin organizing, classifying, and prioritizing work efforts to truly understand what a customer is requesting. Over time, employing work intake strategies will help your customers formulate what they’re really asking for in a more consistent manner that will provide valuable downstream details to the engineers doing the requested work.
By employing work intake, we are gathering details, estimations, and business requirements to provide an effective strategy for making positive decisions and outcomes for the organization. Be careful, though, as an abundance of data or asking too many questions does not always translate to more effective results. Causal inference of the data becomes more valuable when it improves our understanding or outcomes. Therefore, using the right questions will help lead us to better decisions.
Where to Begin?
In order to see the complete picture from a request, we need to lay out all of the pieces of the puzzle. While no two requests are the same in nature, the types of questions to be asked of the customer should be in the same consistent and methodical process.
Throughout the series, we’ll use three separate and unique request examples to provide context around each work intake topic. These request examples, which are common requests across network services organizations, are:
Upgrading new infrastructure at a remote branch location
Migrating from SNMPv2 to SNMPv3
Automated provisioning of Data Center access ports
Starting Point
Critical details from the requester are typically fresh in a user’s mind as they are submitting a request. Employing a classroom technique called anchor charts with the 5 W’s + H of Who, What, When, Where, Why, How will help requesters visualize their request as well as lead to key insights which will be explored more in our next blog.
Taking the original use cases listed earlier, and applying the 5 W’s + H, would begin to provide necessary content to understand the requester’s ask. Here are some examples:
Upgrading new infrastructure at a remote branch location
Who: Remote branch users
What: Site refresh replacing legacy firewall, switch, and AP
When: October 31st
Where: Burbank remote location
Why: Legacy equipment is EoL (end of life) and is no longer supported
How: Replacement to include updates in SoT (Source of Truth) and monitoring
Migrating from SNMPv2 to v3
Who: Monitoring Team
What: Remediate 100+ network devices
When: Risk closure by Nov. 1st per Security Team
Where: All locations (35 sites)
Why: New security standard due to an internal audit
How: Device configurations moved to the new standard
Automate provisioning of Data Center access ports
Who: Network Implementation Team
What: Provide deployment of ports for new server build-outs
When: Servers to arrive Oct. 1st
Where: Brownfield DC
Why: Implementation team is
How: Automation to deploy
Does the 5 W’s + H anchor chart listed above provide valuable information to these use cases? Yes, it most certainly does. However, there are still meaningful questions and analysis that need to be understood in order to produce tangible artifacts for the engineering teams to process these requests. We’ll continue to delve deeper into this work intake analysis in future blogs, so stay tuned.
Conclusion
Throughout the next parts of the work intake series, we’ll continue to expand on our three examples above to shed light on their complexities, dependencies, and outcomes. We’ll also discuss potential risks and rewards (business value) along with acceptance criteria. Lastly, we’ll formulate assumptions and prioritizations as we tie everything together into working artifacts so our downstream engineers can hit the ground running. As always, if you have any questions or comments, we’re here to help! Come join us on the Network to Code Slack.
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Welcome back for Part 4 of the Telemetry Stack! series. The action is steadily ramping up and sticking with The Fast and the Furious analogy. We actually have two guest stars (read: services) featured in this blog. However, I don’t want to spoil the surprise, so you’ll just have to read on!
In this post we will focus on advanced alerting techniques, such as the deadman and standard deviation. Then we will see how we can utilize a few Prometheus / Alertmanager integrations for alert and incident management.
Prerequisites
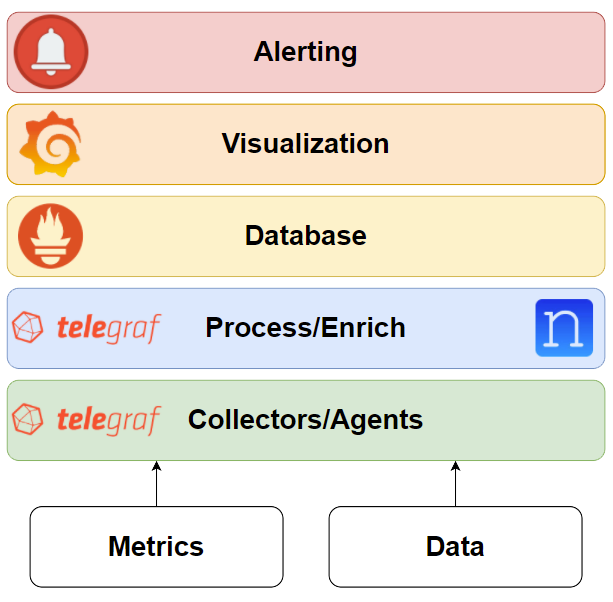
As this blog is part of a series, it builds on what we have explored in the previous posts. Knowledge of the telemetry stack TPG (Telegraf, Prometheus, Grafana) and the basics of metrics gathering and alerting is advised. These topics can all be explored or refreshed at the following links:
As perfectly stated in Xenia’s previous post, an alert is “an alarm or other signal of danger” and must be a “meaningful signal of urgency and not constant white noise that is often ignored”. There are many philosophies to alerting, but we tend to take a page from the Google SRE Book, specifically Ch. 6 – Monitoring Distributed Systems, as a guiding principle.
The power of metrics, and subsequently alerts generated from those metrics, can often encourage an “alert on all the things” behavior. And while it looks great on a coverage spreadsheet, I have found that ultimately it leads to alert oversaturation and on-call exhaustion. As an observability team, we must find a way to design meaningful alert and response contracts with our stakeholders. And as painful as it might sound, not every alert is critical. An overuse of critical or emergency will only serve to create the Cry-Wolf Phenomenon. In other words, assign severity with an overabundance of caution.
We will be exploring just a few concepts here that can turbocharge your alerting, keep your team sane, and perhaps work towards that ever lofty goal of simplicity over complexity.
Deadman Switch
Ahh, the infamous deadman switch. A powerful technique with a grotesque name that you might have interacted with at some point in your daily life! If you have ever operated a lawn mower, ridden a jet ski, or taken the subway, you have interacted with a deadman switch. It’s essentially a safety feature to disable the machine if the human operator becomes disabled for whatever reason.
The deadman switch is typically used in monitoring systems to indicate that something went wrong in your observability pipeline. It could be Telegraf failing to gather, Prometheus failing to store, or Alertmanager going offline. It can be a form of self-monitoring or watching the watcher.
The concept is actually quite simple: send an alert when a metric we expect to be there isnt! To be clear, we are not interested in the value of the metric but rather whether it ceases to exist.
Let’s look at some examples.
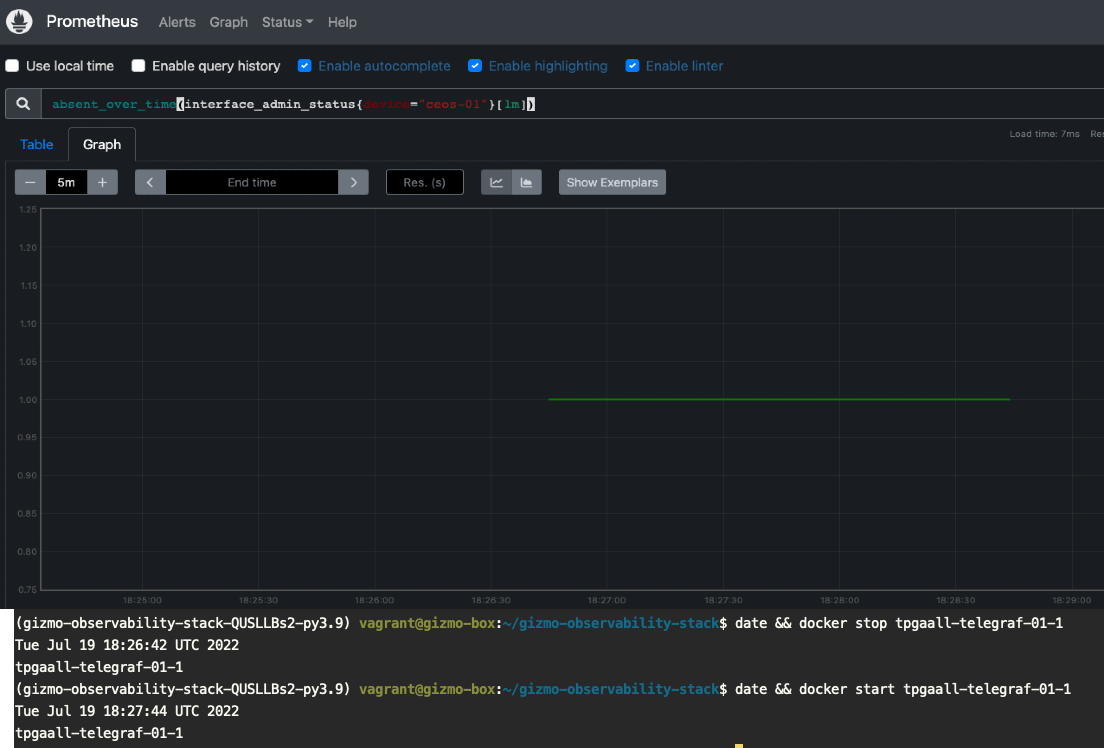
Here I will stop my Telegraf monitoring container, thus eliminating the gathering of interface metrics for device ceos-01. We will take advantage of the Absent() function, which returns an empty vector if the metric exists or a 1-element vector with the value of 1 if it does not exist. The screenshot shows the times and graph of our now missing metrics.
This could indicate that the device stopped responding to polling for numerous reasons, or if corresponded with an up{job="telegraf"} != 1, we could see whether the actual Telegraf poller stopped, which is exactly what happened.
Here is what an example alerting rule in Prometheus might look like utilizing Absent().
-name: Missing Device Metricsrules:-alert: MissingDeviceMetricsexpr:absent(interface_admin_status)for: 2mlabels:severity: highsource: telegrafenvironment: Productionannotations:summary:"Device metrics not being collected"description:"Metrics for {{ $labels.device }} are missing. Check device or collector"
Now that you have seen an example of a deadman alert, can you think of other ways you would use this in a metrics pipeline? Remember, alert when something is missing!
Recording Rules
“Recording rules allow you to precompute frequently needed or computationally expensive expressions and save their result as a new set of time series. Querying the precomputed result will then often be much faster than executing the original expression every time it is needed.” – Prometheus Docs
A great example of recording rules would be pre-calculating the rates of interface traffic over a period of time and then storing that as a separate metric for quick querying for alerting or graphing. In this example, I will set up a recording rule to gather the inbound interface traffic, but from six hours ago! This will allow us to graph historical on top of current, which could be done easily enough in this example with a query. However, think of the recording rule where you could compare traffic week by week or over the last month! This opens the doors for seasonality in your alerts.
Here is our recording rule. We take the rate of interface_in_octets, offset by 6H, and multiply by 8 to change our unit back to bps.
It is difficult to see, but the dotted blue line is the mgmt0 traffic from six hours ago.
Standard Deviation and Anomaly Detection
Let’s pretend that we have been tasked with creating a rule to alert on network device CPU usage for multiple device vendors in our environment. One manufacturer might set the “normal” CPU load at anything less than 80%, while another might consider anything higher than 60% to be a problem. How can we solve this without creating tens if not hundreds of threshold rules and variations of these rules? Answer: Standard deviation.
“In statistics, the standard deviation is a measure of the amount of variation or dispersion of a set of values.[1] A low standard deviation indicates that the values tend to be close to the mean (also called the expected value) of the set, while a high standard deviation indicates that the values are spread out over a wider range.” – Wikipedia
Standard deviation is a fantastic method to implement to find potentially anomalous behavior and further free ourselves from rule and alert overload. Instead of very tedious and specific threshold alerts, we can rely on basic statistics that are more generic, thus encompassing potentially more uses.
Another thing to note here is that threshold alerting is a fantastic (sarcasm) way to create false positives that will ultimately have your team ignoring these alerts and suffering mightily during an on-call rotation. In other words, use them with caution!
What does this mean? If we record (remember those recording rules?) the long running average of what we are interested in, we can determine whether the current (now) values are outside of the average (mean) by a number of deviations, which is called the z-score.
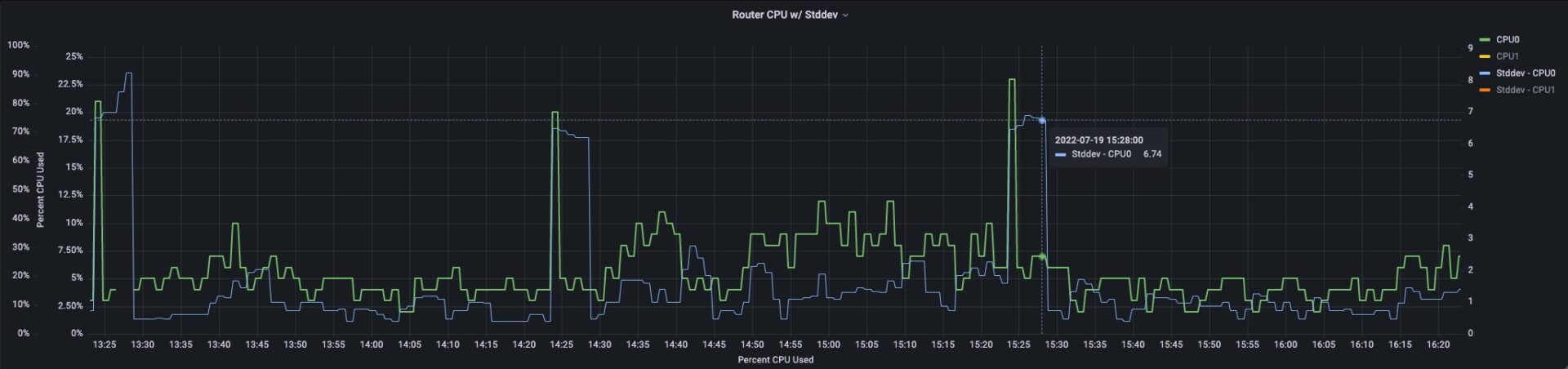
Here is an example of Percentage CPU used on a device (green line) and the plot of the standard deviation for a small average window (blue line). In this example, it is quite easy to see the CPU usage anomalies when the blue line exceeds ~3 on the right axis.
For z-score parameters, “Based on the statistical principles of normal distributions, we can assume that any value that falls outside of the range of roughly +3 to -3 is an anomaly.” – GitLab Anomaly Detection Using Prometheus
Therefore, we can create rules to record and alert when we have a z-score outside of +3/-3.
-name: CPU Used Anomalyrules:-alert: CpuUsedAnomalyexpr:abs((avg_over_time(cpu_used[5m]) - cpu:cpu_used:avg1d) / cpu_stddev:cpu_used:stddev1d) >=3for: 1mlabels:severity: mediumsource: telegrafenvironment: Productionannotations:summary:"Potential CPU Usage Anomaly Detected"description:"A CPU usage anomaly possibly detected for {{ $labels.device }} on {{ $labels.name }}"
Prometheus and Alertmanager Integrations
Prometheus and its alerting component Alertmanager benefit from a great number of popular integrations that can be leveraged by organizations. What exactly are integrations? Let’s use the example of the popular organization messaging application, Slack. Alertmanager has an integration to send messages to a Slack workspace and channel with a highly customizable message format.
Here is a short list of Alertmanager integrations:
email
opsgenie
pagerduty
slack
VictorOps
webhook
Prometheus itself has a great number of alert integrations available via its webhook receiver that can be explored here.
Another way that integrations can work with Alertmanager is if they are designed to utilize the Alertmanager API. One very useful tool for visualizing alerts comes to mind here: Karma. Karma is designed to visualize alerts using a very modern and unique method of grouping. You can take some action against the alerts, but it is probably best used as a visualization dashboard.
This brings us to Alerta. Let’s dive into Alerta, shall we?
Alerta
Alerta is a fully integrated alerting dashboard that allows NOC/SRE/NRE users to perform actions against alerts, create notes, create blackout windows, and generate reports. It supports a multitude of authentication and authorization mechanisms, alert grouping and correlation, and a rich API.
Configuring Alerta is as simple as defining it with a webhook_receiver in Alertmanager. For example:
Here, I cause a CPU usage anomaly with a slightly lower threshold for the purpose of actually generating an alert easily. First, the alert is detected and sent to Alertmanager by Prometheus.
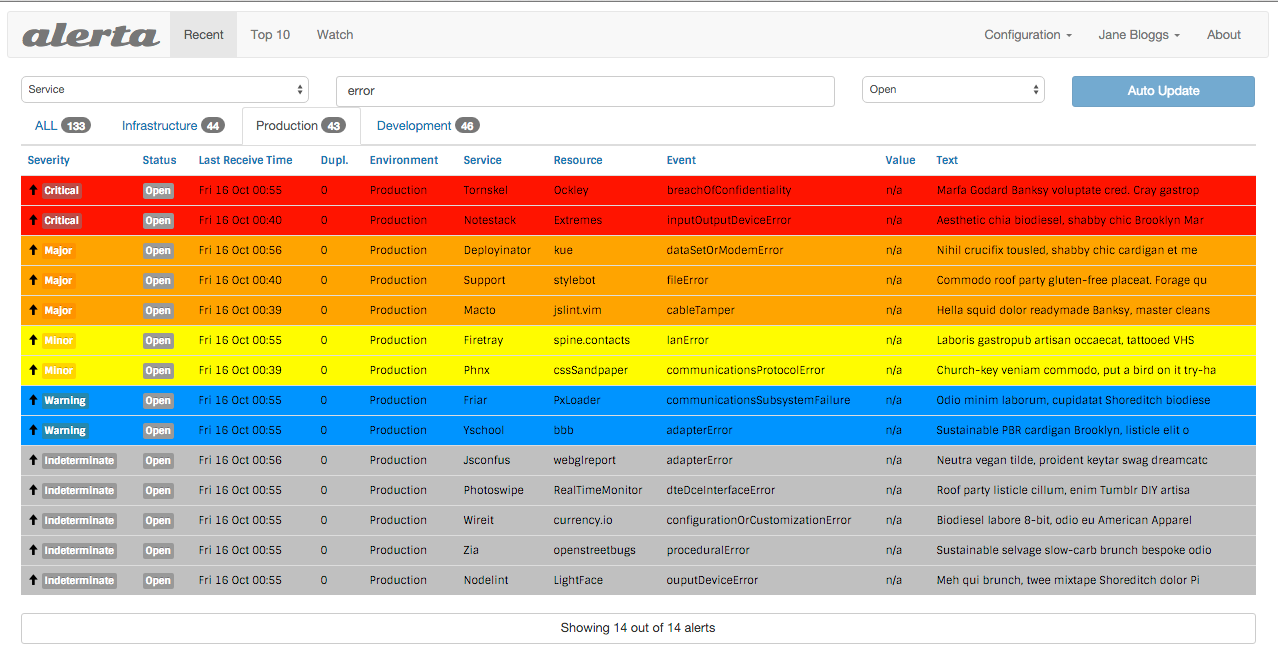
Then, Alerta routes the alert to Alerta based on the labels in the alert. Here, we see the alert list, and you can see the CPU Anomaly Alert.
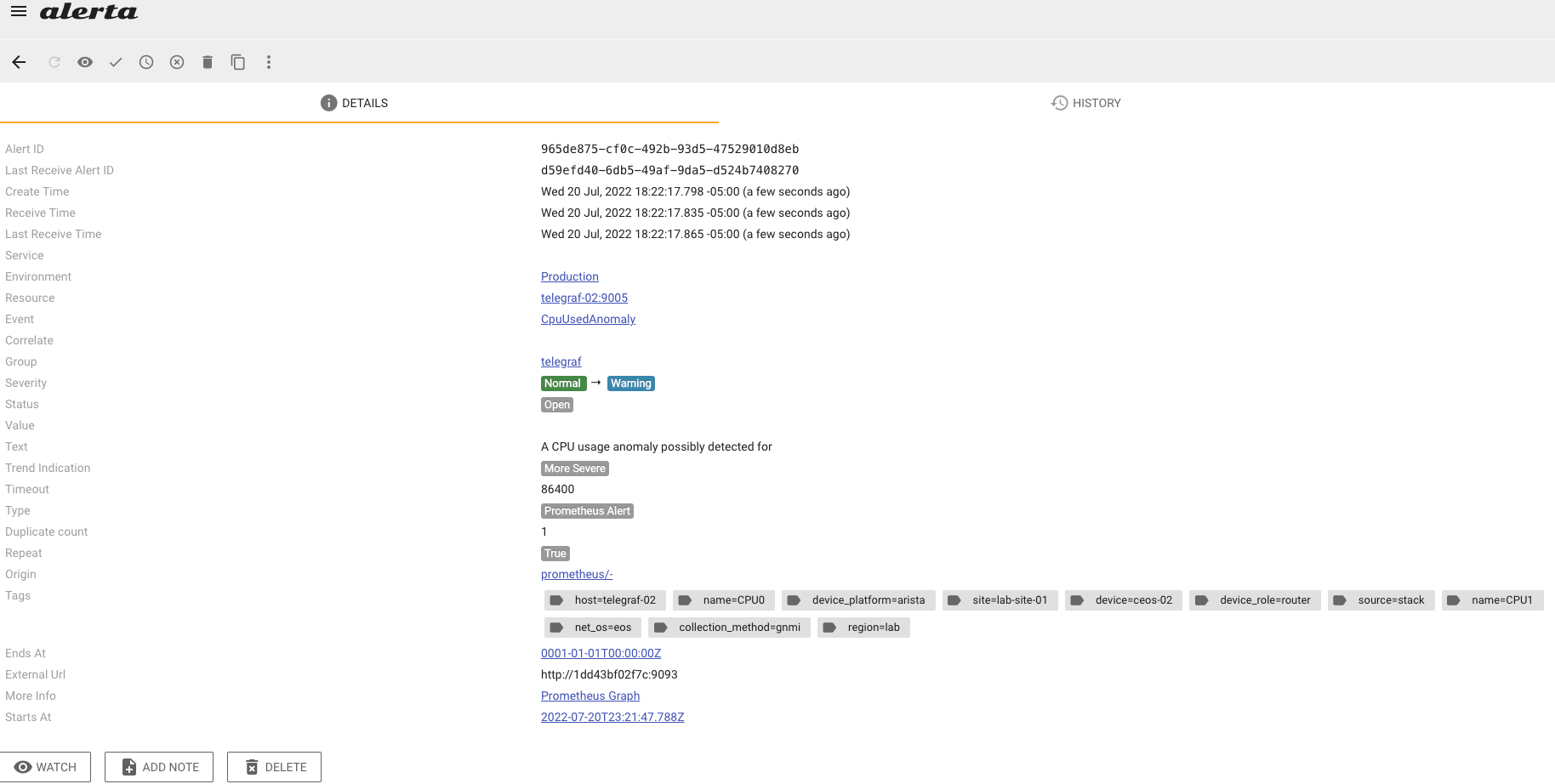
Clicking the alert will display it in detail along with all of the label sets and any other associated data.
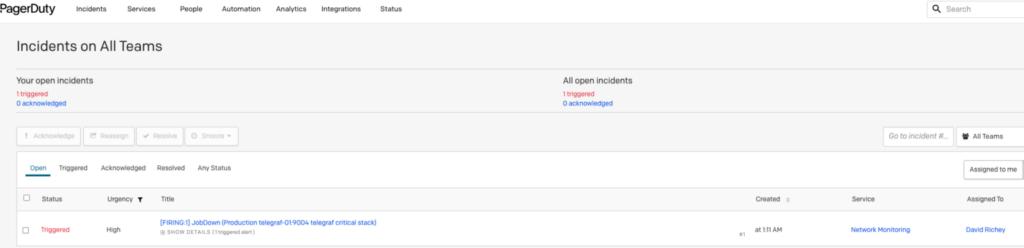
PagerDuty
PagerDuty is an industry-leading incident management system with over 650 integrations! It handles incidents, runbook automation, on-call, and bizops, all from a single SaaS platform.
In this section, I will demonstrate just how easy it is to integrate it with their EventsV2 endpoint that is fully supported by Alertmanager. We will configure our example to only send to PagerDuty for events labeled with critical. It is crucial to think of your on-call staff, SLAs, and alert exhaustion (not to mention on-call PTSD). I always try to approach severity classification with the following mantra: “Is this serious enough to wake someone up at 3am to respond?” Again, I fall back to the Google SRE Book, specifically Ch4. Service Level Objectives.
---global:resolve_timeout: 30mroute:# Let's set a default route, as requiredreceiver: alerta routes:-group_by:- alertnamematch:source: stackreceiver: alerta-group_by:- alertnamematch:source: stackseverity: criticalreceiver: pagerdutyreceivers:-name: pagerdutypagerduty_configs:-routing_key:<your_pager_duty_eventsv2_routing_key>- name: alerta webhook_configs: - url: http://alerta-01:8080/api/webhooks/prometheus send_resolved: true
Conclusion
Phew! Now that was a lot to cover in just one blog! As we could easily go down the rabbit hole on each of these topics, I will be providing a list of links for follow-up reading, especially around the anomaly detection, as it is an entire blog unto itself.
Together, we explored some advanced alerting concepts, such as the Deadman, where we learned that we could alert on missing metrics. Then came Recording Rules and their power to store pre-computed metrics that would otherwise become computationally expensive to query. These same recording rules then enabled us to move on to our next topic, standard deviation. That demonstrated how to get out of the threshold alert rule game and started exploring Standard Deviation based alerts that have the power to alert us to anomalous behavior.
Finally, our guest stars of the hour: We took a look at two of our favorite Prometheus alerting integrations (with an honorable mention of Karma) here at NTC, Alerta and PagerDuty. We saw how to leverage the power of Alerta for alert management with RBAC and hand-off and how to page our on-call staff when things are really critical.
I hope you enjoyed this blog post. Stay tuned for the next installment in our telemetry series! Rumor has it, a wild antlered animal is the main star!
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Just like The Fast and the Furious movies, we are going to be churning out sequels like no other! Welcome to Part 2 of the Telemetry Stack! series, where we walk you through the different stages of bringing insight into your infrastructure. Although there won’t be a special appearance from Ludacris in this sequel, you are in for a heck of a ride!
In this post we will focus on the concept of normalizing data between multiple systems and adding value with enrichment. To help follow along with some of the keywords used in this post, I recommend checking out Part 1 written by Nikos Kallergis for a refresher.
Normalization and Enrichment
During Part 1 we discussed the TPG stack, its different layers, and how to get started with Telegraf. Now it’s time to talk about processing those metrics into something more useful!
Have you ever run into the issue where different versions of software return different metric names like bgp_neighbor versus bgp-neighbor? What about metrics that don’t quite have all the data you’d like? This is where processing can help solve a lot of headaches by allowing you to normalize and enrich the metrics before passing them into your database.
Normalizing Data
One of the toughest situations to work with in telemetry is that almost every vendor is different. This means that sometimes your BGP metrics can come in with different labels or fields, which can introduce all kinds of trouble when trying to sort them in graphs or alerting. Normalizing the data allows you to adjust different fields and labels to either tune them to your environment, or to enforce naming standards.
Enriching Data
Enriching data can be very powerful and can take your metrics to a whole new level. Sure, some vendors do an amazing job at returning all the data you need, but what about the data that they can’t provide? With data enrichment you can add labels or fields to your metrics to track things like site location, rack location, customer IDs, and even SLA information for tenants.
NOTE: Prometheus uses labels to determine the uniqueness of a metric. If you change the label of an existing metric, you may lose graph history in Grafana. You would need to update your query to pull for both the old and new labels so that they are combined.
Normalizing Data Using Telegraf
Using our scenario from above, let’s normalize some BGP data and modify a few metric fields to make sure they match and are standard across the board.
[[processors.rename]]
# --------------------------------------------------- # Normalize BGP Data # --------------------------------------------------- [[processors.rename]] order =1 namepass = ["bgp*"] [[processors.rename.replace]] field ="installed" dest ="prefixes_installed" [[processors.rename.replace]] field ="sent" dest ="prefixes_sent" [[processors.rename.replace]] field ="received" dest ="prefixes_received"
It looks like a bit of a mess at first; but if you look closely, it’s pretty straightforward. [[processors.rename]]
order allows us to set the order in which processors are executed. It’s not required; but if you don’t specify, the order will be random.
namepass is an array of glob pattern strings. Only measurements’ names that match this pattern will be emitted.
With a simple processor like this, we are able to catch any BGP fields that come in as installed and transform them into prefixes_installed to ensure they match our metrics pulled from other agents.
Another powerful processor in Telegraf is enum. The enum processor allows the configuration of value mappings for field or tag values. The main use for this is for creating a mapping between strings and integers.
# --------------------------------------------------- # Normalize status codes # --------------------------------------------------- [[processors.enum]] order =3 namepass = ["storage"] [[processors.enum.mapping]] tag ="status" [processors.enum.mapping.value_mappings]1="READ_ONLY"2="RUN_FROM_FLASH"3="READ_WRITE"
With this enum config, all storage metrics will have their status tag updated so that the end result is no longer a number and is easier to read.
Sometimes even simple normalizations can save you from some of those dreaded late-night calls from your NOC. Changing a field into a more user-friendly field will prevent a lot of headaches during outages as well.
Enriching Data Using Telegraf
When it comes to enrichment you can either perform a what we call a static enrichment or a dynamic enrichment. Static enrichment is based on the Telegraf configuration file which means it is valid during the lifecycle of the configuration. Sometimes we like flexibility and not have a dependency on configuration or Telegraf deployments which is where dynamic enrichment comes in.
Static Enrichment
Telegraf has a lot of processors for enrichment but we will focus on the regex plugin. This plugin allows you to match a particular pattern for creating static labels and values.
This is great, but wouldn’t it be better if this label could be updated with a change inside Nautobot? Well, this is where dynamic enrichment comes in.
Dynamic Enrichment
With dynamic enrichment we can take it a step further by pulling values from a single source of truth like Nautobot. In the next example I will be giving you a glance into an upcoming project that’s still currently in work but hopefully will be released soon so keep a lookout for the blog post!
Let me give you a sneak peek into network-agent. The network-agent project is built as a ‘batteries included’ Telegraf/Python-based container targeted for network metrics consumption and processing. The network-agent container comes with a lot of features, but for now we will only focus on the Nautobot processor.
Key features of this processor:
GraphQL-based queries to Nautobot for simplicity and speed.
JMESPath query for easy data extraction.
LRU caching to reduce API calls for metric enrichment.
NOTE: The default cache TTL is set to 120 seconds. This means that the cache will remain valid until this timer has passed. After that, another GraphQL query to Nautobot is sent to check for new interfaces and roles.
This is what the configuration can look like:
[nautobot]# Nautobot URL and Token specified using environment variablesgraphql_query ="""query ($device: [String!]) {devices(name: $device) {nameinterfaces(tag: "intf_pri__tier1") {namecf_roletags{name}}}}"""[enrich.interface.tag_pass] device ='ceos-*' name ="interface*"[enrich.interface.extract] # JMESPATH interface_role ="devices[0].interfaces[?name==''].cf_role | [0]"
With this processor, we are able to query Nautobot for devices and filter the results to only interfaces with a intf_pri__tier1 tag. The information is then cached and can be used during the enrichment process.
[enrich.interface.tag_pass]
With the device and name options, we are able to control which specific metrics will get enriched with our new label.
[enrich.interface.extract]
This is where we define our new label that will get added to the metrics and the JMESPath query to grab our value. In this case, we will be taking the custom field called role out of Nautobot and adding it to all our interface metrics for our ceos devices.
Metric labels can be extremely powerful for both troubleshooting global infrastructure and capacity planning for companies. Whether you are using enrichment to add customer_id to BGP metrics or using normalization to remove those pesky special characters from your interface descriptions, telemetry can do it all.
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. In case of sale of your personal information, you may opt out by using the link Do not sell my personal information. Privacy | Cookies
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
__hssc
30 minutes
HubSpot sets this cookie to keep track of sessions and to determine if HubSpot should increment the session number and timestamps in the __hstc cookie.
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie records the user consent for the cookies in the "Advertisement" category.
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
CookieYes sets this cookie to record the default button state of the corresponding category and the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Cookie
Duration
Description
__cf_bm
30 minutes
Cloudflare set the cookie to support Cloudflare Bot Management.
li_gc
5 months 27 days
Linkedin set this cookie for storing visitor's consent regarding using cookies for non-essential purposes.
lidc
1 day
LinkedIn sets the lidc cookie to facilitate data center selection.
UserMatchHistory
1 month
LinkedIn sets this cookie for LinkedIn Ads ID syncing.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__hstc
5 months 27 days
Hubspot set this main cookie for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
1 year 1 month 4 days
Google Analytics sets this cookie to calculate visitor, session and campaign data and track site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognise unique visitors.
_gat_gtag_UA_*
1 minute
Google Analytics sets this cookie to store a unique user ID.
_gid
1 day
Google Analytics sets this cookie to store information on how visitors use a website while also creating an analytics report of the website's performance. Some of the collected data includes the number of visitors, their source, and the pages they visit anonymously.
AnalyticsSyncHistory
1 month
Linkedin set this cookie to store information about the time a sync took place with the lms_analytics cookie.
CONSENT
2 years
YouTube sets this cookie via embedded YouTube videos and registers anonymous statistical data.
hubspotutk
5 months 27 days
HubSpot sets this cookie to keep track of the visitors to the website. This cookie is passed to HubSpot on form submission and used when deduplicating contacts.
ln_or
1 day
Linkedin sets this cookie to registers statistical data on users' behaviour on the website for internal analytics.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
bcookie
1 year
LinkedIn sets this cookie from LinkedIn share buttons and ad tags to recognize browser IDs.
bscookie
1 year
LinkedIn sets this cookie to store performed actions on the website.
li_sugr
3 months
LinkedIn sets this cookie to collect user behaviour data to optimise the website and make advertisements on the website more relevant.
VISITOR_INFO1_LIVE
5 months 27 days
YouTube sets this cookie to measure bandwidth, determining whether the user gets the new or old player interface.
YSC
session
Youtube sets this cookie to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the user's video preferences using embedded YouTube videos.
yt-remote-device-id
never
YouTube sets this cookie to store the user's video preferences using embedded YouTube videos.
yt.innertube::nextId
never
YouTube sets this cookie to register a unique ID to store data on what videos from YouTube the user has seen.
yt.innertube::requests
never
YouTube sets this cookie to register a unique ID to store data on what videos from YouTube the user has seen.