

Forecasting is a fascinating concept. Who does not want to know the future? Oracles from the ancient times, a multitude of statistical forecasting models, and machine learning prediction algorithms have one thing in common: the thirst to know what is going to happen next. As fascinating as forecasting is, it is not an easy conquest. There are phenomena that can be predicted, because we understand what causes them and we have a large amount of historical data. An example is electricity consumption: it exhibits seasonality and predictability. On the other hand, there are phenomena that are difficult to predict, such as market trends that depend on human emotion and unpredictable world events (wars for example).
Where does the network fall in the spectrum of forecasting ease and accuracy? How easily and effectively can we predict the next outage, a big dip in performance, or an anomaly that may point to an attack? Starting from the assumption that we have a large amount of data (and events mostly depend on machine behavior), the network can be quite predictable. A variety of events, such as outages, are predictable—some planned and some caused by happenstances, such as an overload or human error.
As any human, the network engineer would like to have an oracle at their disposal to let them know about the future occurrence of important events. Deciding on the size and availability of network resources based on forecasting traffic and usage models, knowing how often one should update or reconfigure with minimal disruption, and planning maintenances based on traffic patterns are some powerful use cases for a network operator. Hence this blog, which gives programmatic tools for the network engineer to automate forecasting of the network with Python Pandas.
Prerequisites
This blog is part of a series. You can read this independently of the series if you are familiar with Pandas and how to use Jupyter notebooks. However, you can start your journey from the beginning, especially if you want to actively read and work out the examples. I recommend starting with Jupyter Notebooks for Development and then Introduction to Pandas for Network Development. You can also read the Intro to Pandas (Part 2) – Exploratory data analysis for network traffic, however this part is not necessary in order to understand forecasting.
What Is Statistical Forecasting?
Statistical forecasting is the act of creating a model to predict future events based on past experience with a certain degree of uncertainty. In this blog, we will focus on statistical forecasting methods. A variety of machine learning forecasting is analyzed in other blogs; however simple is better, as has been shown by studies for the past 40 years in the M competition and analysis. Statistical methods are less computationally complex, and the best Machine Learning fitting methods are not always optimal for forecasting.
Basic Forecasting Methods
Below is a list of basic forecasting methods and their definitions:
- Straight line: this is a naive prediction that uses historical figures to predict growth and only applies to an upward trend.
- Moving averages: one of the most popular methods that takes into account the pattern of data to estimate future values. A well known implementation of moving averages is the Auto Regressive Integrated Moving Average (ARIMA).
- Linear regression: in this case as well, a straight line is fitted to the data; however this time it can predict upward or downward trends.
- Multiple linear regression: if we want to use two or more variables to predict the future of another variable, for example use holidays and latency to predict network traffic patterns, multiple linear regression is our friend.
We will review implementations of the two most popular techniques: moving averages and linear regression with Pandas libraries.
How to Implement Forecasting
These basic steps are part of almost every forecasting implementation:
- Preprocessing: it may include removing
NaN, adding metadata, or splitting your data in two distinct parts: thetrainingdata, which is used to make predictions, and thetestdata, which is used to validate predictions. Splitting your data is a whole article or two on its own: should you split data in half, in random chunks, etc. - Pick your poison…ehm…model: this may be the most difficult part, and some Exploratory Data Analysis may be required to pick a good algorithm.
- Analyze the results: analysis is usually performed visually with graphical methods.
- Iterate: periodic fine-tuning of the forecasting method may include changing algorithm parameters.
Forecasting the Network Example
Now that we know the basics about the theory of forecasting, let’s implement all the steps and apply moving averages and linear regression to a network dataset.
Dataset
The dataset that we will use is a the Network Anomaly Detection Dataset. It includes Simple Network Management Protocol (SNMP) monitoring data. SNMP is the de facto protocol when it comes to telemetry for network appliances and can track a variety of interesting data related to machine performance, such as bytes in/out, errors, packets, connection hits, etc.
You will find the code referenced in the examples at the Pandas Blog GitHub repository.
Preprocessing
Preprocessing of the data includes cleaning and adding metadata. We need to add dates to this specific dataset.
We begin with the necessary imports and loading the csv file to a Pandas data frame:
import numpy as np
import pandas as pd
network_data = pd.read_csv("../data/network_data.csv")
network_data.columns
Index(['ifInOctets11', 'ifOutOctets11', 'ifoutDiscards11', 'ifInUcastPkts11',
'ifInNUcastPkts11', 'ifInDiscards11', 'ifOutUcastPkts11',
'ifOutNUcastPkts11', 'tcpOutRsts', 'tcpInSegs', 'tcpOutSegs',
'tcpPassiveOpens', 'tcpRetransSegs', 'tcpCurrEstab', 'tcpEstabResets',
'tcp?ActiveOpens', 'udpInDatagrams', 'udpOutDatagrams', 'udpInErrors',
'udpNoPorts', 'ipInReceives', 'ipInDelivers', 'ipOutRequests',
'ipOutDiscards', 'ipInDiscards', 'ipForwDatagrams', 'ipOutNoRoutes',
'ipInAddrErrors', 'icmpInMsgs', 'icmpInDestUnreachs', 'icmpOutMsgs',
'icmpOutDestUnreachs', 'icmpInEchos', 'icmpOutEchoReps', 'class'],
dtype='object')
The table column titles printed above include characteristic SNMP data (such as TCP active open connections, input/output packets, and UDP input/output datagrams) that offer a descriptive picture of performance status and potential anomalies in network traffic. After this we can add a date column or any other useful metadata. Let’s keep it simple here and add dates spaced evenly to days using a column of our data, the ipForwDatagrams:
dates = pd.date_range('2022-03-01', periods=len(network_data["ipForwDatagrams"]))
We are ready to review the fun part of forecasting, by implementing Moving Average.
Moving Average
Pandas has a handy function called rolling that can shift through a window of data points and perform a function on them such as an average or min/max function. Think of it as a sliding window for data frames, but the slide is always of size 1 and the window size is the first parameter in the rolling function. For example, if we set this parameter to 5 and the function to average, we will calculate 5 averages in a dataset with 10 data points. This example is illustrated in the following figure, where we have marked the first three calculations of averages:
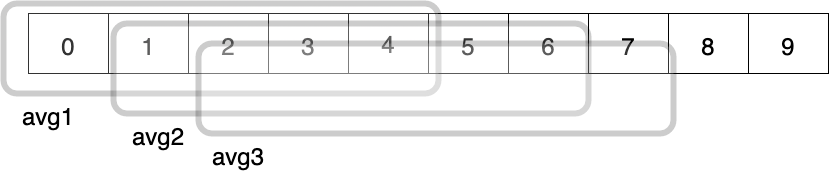
How does this fit with forecasting? We can use historic data (last 5 data points in the above example), to predict the future! Every new average from this rolling function, gives a trend for what is coming next. Let’s make this concrete with an example.
First we create a new data frame that includes our metadata dates and the value we want to predict, ipForwDatagrams:
df = pd.DataFrame(data=zip(dates, network_data["ipForwDatagrams"]), columns=['Date', 'ipForwDatagrams'])
df.head()
Date ipForwDatagrams
0 2022-03-01 59244345
1 2022-03-02 59387381
2 2022-03-03 59498140
3 2022-03-04 59581345
4 2022-03-05 59664453
Then we use the rolling average. We apply it on the IP forward Datagrams column, ipForwDatagrams, to calculate a rolling average every 1,000 data points. This way we use historic data to create a trend line, a.k.a. forecasting!
df["rolling"] = df["ipForwDatagrams"].rolling(1000, center=True).mean()
Finally, we will visualize the predictions:
# Plotting the effect of a rolling average
import matplotlib.pyplot as plt
plt.plot(df['Date'], df['ipForwDatagrams'])
plt.plot(df['Date'], df['rolling'])
plt.title('Data With Rolling Average')
plt.show()

The orange line represents our moving average prediction and it seems to be doing pretty well. You may notice that it does not follow the spikes in the data, it is much smoother. If you experiment with the granularity, i.e., smaller than 1,000 rolling window, you will see an improvement in predictions with loss to additional computations.
Linear Regression
Linear regression fits a linear function to a set of random data points. This is achieved by searching for all possible values for the variables a, b that define a line function y = a * x + b. The line that minimizes the distance from the dataset data points is the result of the linear regression model.
Let’s see if we can calculate a linear regression predictor for our SNMP dataset. In this case, we will not use time series data; we will consider the relationship, and as a consequence the predictability, of a variable using another. The variable that we consider as a known, or historic data, is the TCP input segments tcpInSegs. The variable that we are aiming to predict is the output segments, tcpOutSegs. Linear Regression is implemented by linear_model in the sklearn library, a powerful tool for data science modeling. We set the x var to tcpInSegs column from the SNMP dataset and the y var to tcpOutSegs. Our goal is to define the function y = a * x + b, specifically a and b constants, to determine a line that predicts the trend of output segments when we know the input segments:
from sklearn import linear_model
import matplotlib.pyplot as plt
x = pd.DataFrame(network_data['tcpInSegs'])
y = pd.DataFrame(network_data['tcpOutSegs'])
regr = linear_model.LinearRegression()
regr.fit(x, y)
The most important part of the above code is the use of linear_model.LinearRegression() function that does its magic behind the scenes and returns a regr object. This object gives us a function of a, b variables, that can be used to forecast the number of TCP out segments based on the number of input TCP segments. If you do not believe me, here is the plotted result:
plt.scatter(x, y, color='black')
plt.plot(x, regr.predict(x), color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()

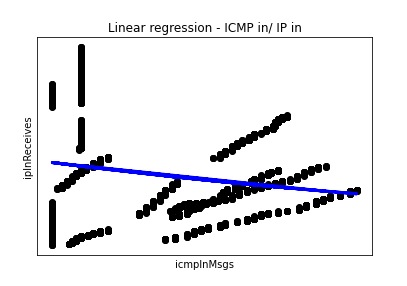
The blue line indicates our prediction, and if you ask me, it is pretty good. Now how about trying to predict IP input received, ipInReceives, from ICMP input messages (icmpInMsgs)? Would we achieve such good forecasting? Let’s just change the x and y variables and find out:
x = pd.DataFrame(network_data['icmpInMsgs'])
y = pd.DataFrame(network_data['ipInReceives'])
regr = linear_model.LinearRegression()
regr.fit(x, y)
We use the same code as above to generate the plot. This one does not look nearly as accurate. However, the blue line indicates the decreasing trend of the IP in received packets based on ICMP inputs. That is a good example of where another forecasting algorithm could be used, such as dynamic regression or a nonlinear model.
Conclusion
We have reviewed two of the most popular forecasting methodologies, moving averages and linear regression, with Python Pandas. We have noticed the benefits and accuracy of forecasting as well as its weaknesses.
This concludes the Pandas series for Network Automation Engineers. I hope you have enjoyed this as much as I have and added useful tools for your ever growing toolbox.
-Xenia
Resources
Tags :
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
Share :






Contact Us to Learn More
Share details about yourself & someone from our team will reach out to you ASAP!