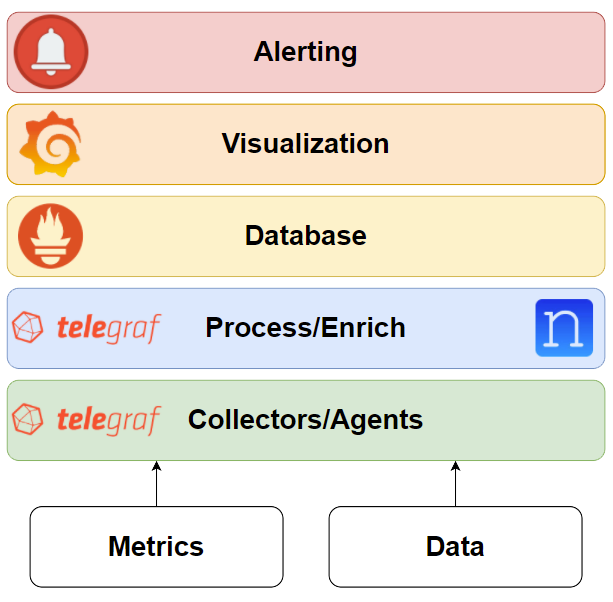
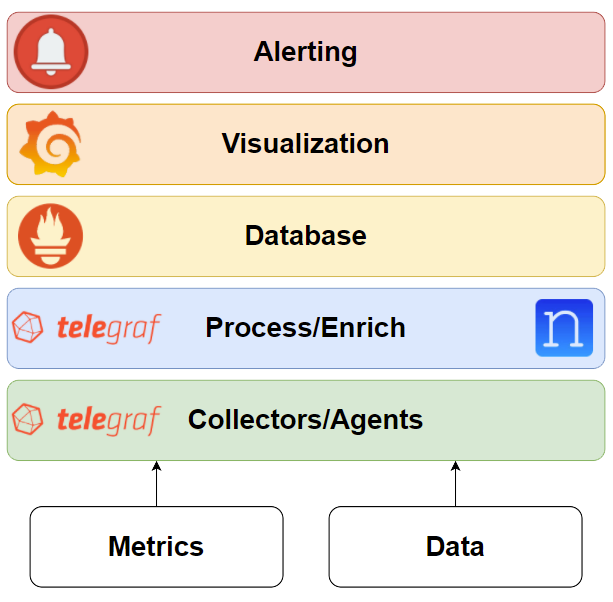
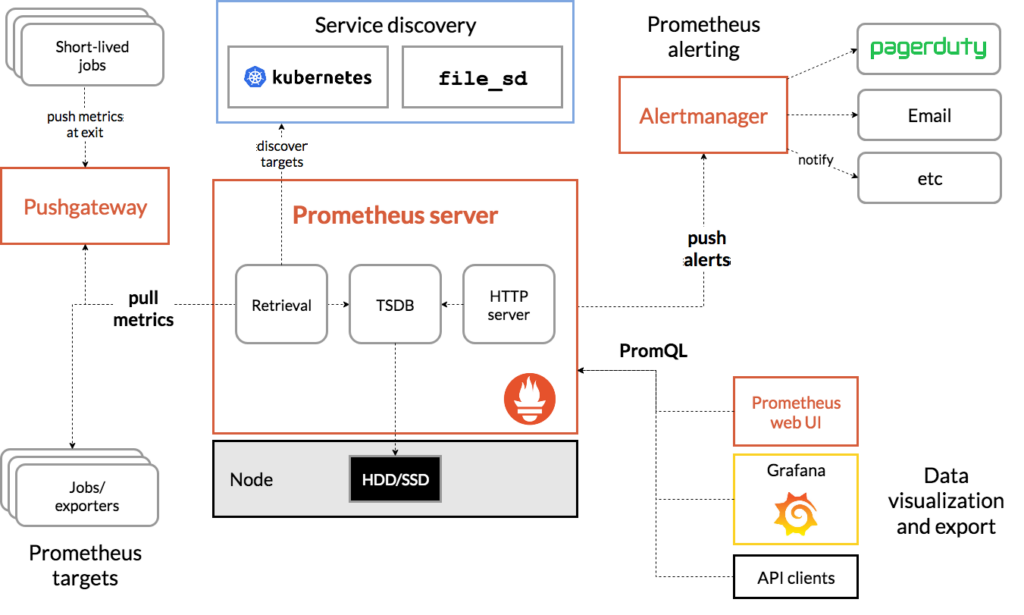
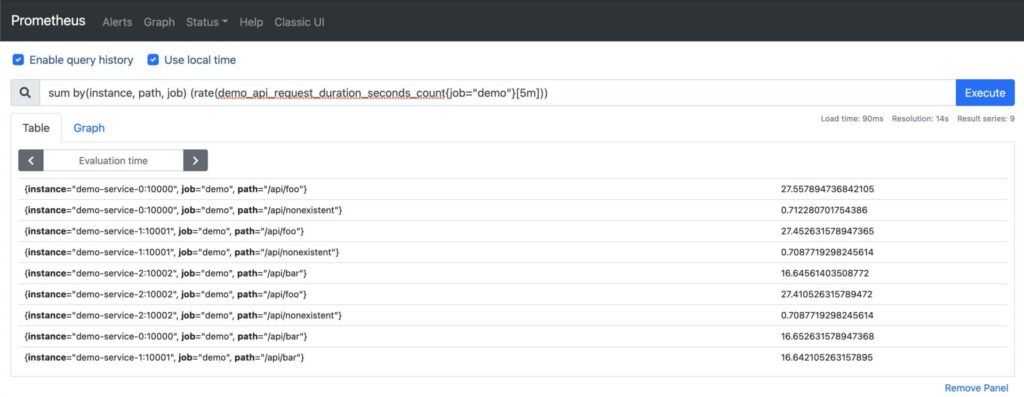
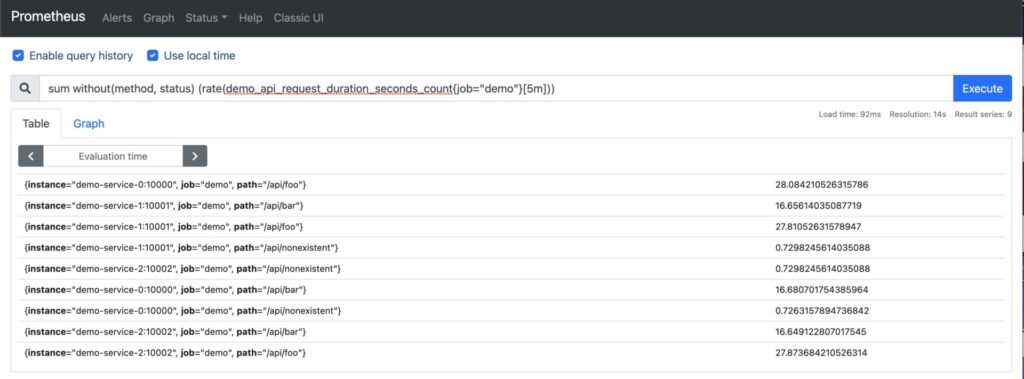
You know that “bookending” technique in movies like Fight Club and Pulp Fiction where they open up with the chronologically last scene? Well, this is more or less the same, but instead of a movie it’s the Telemetry Stack! NTC blog post series. And this is what your network monitoring solution could look like. Well, maybe not exactly like this but you get the idea, right?
This series of blog posts that will be released during the coming weeks dives into detail on how to build a contemporary network monitoring system using widely accepted open-source materials like Telegraf, Prometheus, Grafana, and Nautobot. Also, lots of “thanks” go to Josh VanDeraa and his very detailed blog posts that have served as a huge inspiration for this series!
In part 1 of the series, we’ll focus on two aspects:
- Introduction to the Telemetry Stack!
- Capturing metrics and data using Telegraf
Introduction to the Telemetry Stack!
During the blog post series, we’ll explore the components that comprise the TPG (Telegraf, Prometheus, Grafana) Telemetry Stack!
Telegraf
In short, Telegraf is a metrics and events collector written in Go. Its simple architecture and plethora of built-in modules allow for easy capturing of metrics (input modules), linear processing (processor modules), and storing them to a multitude of back-end systems (output modules). For the enrichment part, Nautobot will be leveraged as the Source of Truth (SoT) that holds the additional information.
Prometheus
As already mentioned, Prometheus will be the TSDB of choice for storing our processed metrics and data.
Grafana
In order to present the data in a human-friendly form, we’ll be visualizing them using Grafana. Dashboard design is an art of its own, but we’ll attempt to present a basic set of dashboards that could serve as inspiration for creating your own.
Alertmanager
Using Grafana dashboards sprinkled with sane thresholds, we’re able to create alerting mechanisms triggered whenever a threshold is crossed.
Capturing Metrics and Data Using Telegraf
The rest of this post is dedicated on using Telegraf to get data from network devices. Now, one (or probably more) may wonder “why Telegraf?” and that’s indeed a question we also asked ourselves when designing this series. We decided to go with Telegraf based on the following factors:
- it works and we like it
- its configuration is comparatively easy to generate using templates
- it’s a very flexible solution, allowing us to do SNMP, gNMI, and also execute Python scripts
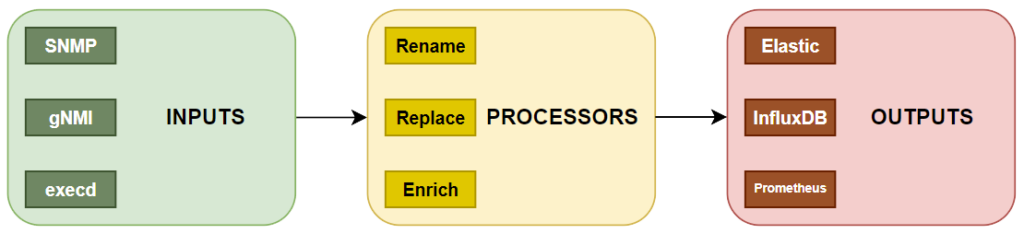
- it uses a very simple basic flow between its components
Inputs: Telegraf provides a ton of various input methods out of the box, like snmp, gnmi, and execd. These are the components that enable us to capture metrics and data from our targets. Incidentally, this is also the main topic in the second half of this post, so more details may be found there.
Processors: As with inputs, Telegraf also comes loaded with a bunch of processor modules that allow us to manipulate our collected data. In this blog post series, our focus will be normalization and enrichment of the captured metrics. This will be the main topic in the second post of the series.
Outputs: Last, once we’re happy with the processors result, we use outputs to store the transformed data. Three of the most common Time Series Databases (TSDBs), used for storing metrics are InfluxDB (from the same manufacturer as Telegraf), Elasticsearch, and of course Prometheus which will be the output used throughout the series.
For the purposes of this blog post, we’ll be using two Arista cEOS machines. So, with all that out of our way, let’s dive into our various input methods!
Like the old-time gray-beards that we are, we’ll begin our journey using SNMP to perform a simple metrics capture.
# ------------------------------------------------
# Input - SNMP
# ------------------------------------------------
[[inputs.snmp]]
agents = ["ceos-02"]
version = 2
community = "${SNMPv2_COMMUNITY}"
interval = "60s"
timeout = "10s"
retries = 3
[inputs.snmp.tags]
collection_method = "snmp"
device = "ceos-02"
device_role = "router"
device_platform = "arista"
site = "lab-site-01"
region = "lab"
net_os = "eos"
# ------------------------------------------------
# Device Uptime (SNMP)
# ------------------------------------------------
[[inputs.snmp.field]]
name = "uptime"
oid = "RFC1213-MIB::sysUpTime.0"
# ----------------------------------------------
# Device Storage Partition Table polling (SNMP)
# ----------------------------------------------
[[inputs.snmp.table]]
name = "storage"
# Partition name
[[inputs.snmp.table.field]]
name = "name"
oid = "HOST-RESOURCES-MIB::hrStorageDescr"
is_tag = true
# Size in bytes of the data objects allocated to the partition
[[inputs.snmp.table.field]]
name = "allocation_units"
oid = "HOST-RESOURCES-MIB::hrStorageAllocationUnits"
# Size of the partition storage represented by the allocation units
[[inputs.snmp.table.field]]
name = "size_allocation_units"
oid = "HOST-RESOURCES-MIB::hrStorageSize"
# Amount of space used by the partition represented by the allocation units
[[inputs.snmp.table.field]]
name = "used_allocation_units"
oid = "HOST-RESOURCES-MIB::hrStorageUsed"
Note: A detailed line-by-line explanation of the Telegraf configuration may be found in the excellent Network Telemetry for SNMP Devices blog post by Josh.
Now that we’ve covered the capabilities of old-school MIB/OID-based NMS, let’s jump to what all the cool kids are playing with these days: gRPC (Remote Procedure Calls) Network Management Interface. Bit of a mouthful! The main benefits of using gNMI for telemetry are its speed and efficiency. Thanks to the magic of Telegraf, we are able to capture data with just a few more lines of code.
# ------------------------------------------------
# Input - gNMI
# ------------------------------------------------
[[inputs.gnmi]]
addresses = ["ceos-02:50051"]
username = "${NETWORK_AGENT_USER}"
password = "${NETWORK_AGENT_PASSWORD}"
redial = "20s"
tagexclude = [
"identifier",
"network_instances_network_instance_protocols_protocol_name",
"afi_safi_name",
"path",
"source"
]
[inputs.gnmi.tags]
collection_method = "gnmi"
device = "ceos-02"
device_role = "router"
device_platform = "arista"
site = "lab-site-01"
region = "lab"
net_os = "eos"
# ---------------------------------------------------
# Device Interface Counters (gNMI)
# ---------------------------------------------------
[[inputs.gnmi.subscription]]
name = "interface"
path = "/interfaces/interface/state/counters"
subscription_mode = "sample"
sample_interval = "10s"
[[inputs.gnmi.subscription]]
name = "interface"
path = "/interfaces/interface/state/admin-status"
subscription_mode = "sample"
sample_interval = "10s"
[[inputs.gnmi.subscription]]
name = "interface"
path = "/interfaces/interface/state/oper-status"
subscription_mode = "sample"
sample_interval = "10s"
# ---------------------------------------------------
# Device Interface Ethernet Counters (gNMI)
# ---------------------------------------------------
[[inputs.gnmi.subscription]]
name = "interface"
path = "/interfaces/interface/ethernet/state/counters"
subscription_mode = "sample"
sample_interval = "10s"
# ----------------------------------------------
# Device CPU polling (gNMI)
# ----------------------------------------------
[[inputs.gnmi.subscription]]
name = "cpu"
path = "/components/component/cpu/utilization/state/instant"
subscription_mode = "sample"
sample_interval = "10s"
# ----------------------------------------------
# Device Memory polling (gNMI)
# ----------------------------------------------
[[inputs.gnmi.subscription]]
name = "memory"
path = "/components/component/state/memory"
subscription_mode = "sample"
sample_interval = "10s"
Note: Another great blog from Josh touches on the same subjects: Monitor Your Network With gNMI, SNMP, and Grafana.
The third and last input that we’ll examine in this blog is execd; even cooler than the gNMI cool kids! Practically, it’s a way for Telegraf to run scripts and capture the data that are output in a metrics format. In our case though, the script is in reality a container image that makes it easy to collect metrics using a multitude of different methods. In the following simple example, it is used to collect BGP information over EOS RESTful API.
# ------------------------------------------------
# Input - Execd command
# ------------------------------------------------
[[inputs.execd]]
interval = "60s"
signal = "SIGHUP"
restart_delay = "10s"
data_format = "influx"
command = [
'/usr/local/bin/network_agent',
'-h',
'ceos-02',
'-d',
'arista_eos',
'-c',
'bgp_sessions::http', ]
[inputs.execd.tags]
collection_method = "execd"
device = "ceos-02"
device_role = "router"
device_platform = "arista"
site = "lab-site-01"
region = "lab"
net_os = "eos"
Collected Data
At this point, we’ve managed to collect various metrics and data from our target devices. We still have to process them, store them, and visualize them but these are the topics of the blog posts that will follow. For now, we may take a peek into the collected data to verify that they’ve been captured successfully, before “passing” them to the normalization/enrichment step of the process.
# HELP snmp_uptime Telegraf collected metric
# TYPE snmp_uptime untyped
snmp_uptime{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",net_os="eos",region="lab",site="lab-site-01"} 14082
# HELP storage_allocation_units Telegraf collected metric
# TYPE storage_allocation_units untyped
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Core",net_os="eos",region="lab",site="lab-site-01"} 4096
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Flash",net_os="eos",region="lab",site="lab-site-01"} 4096
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Log",net_os="eos",region="lab",site="lab-site-01"} 4096
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM",net_os="eos",region="lab",site="lab-site-01"} 1024
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Buffers)",net_os="eos",region="lab",site="lab-site-01"} 1024
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Cache)",net_os="eos",region="lab",site="lab-site-01"} 1024
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Unavailable)",net_os="eos",region="lab",site="lab-site-01"} 1024
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Root",net_os="eos",region="lab",site="lab-site-01"} 4096
storage_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Tmp",net_os="eos",region="lab",site="lab-site-01"} 4096
# HELP storage_size_allocation_units Telegraf collected metric
# TYPE storage_size_allocation_units untyped
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Core",net_os="eos",region="lab",site="lab-site-01"} 400150
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Flash",net_os="eos",region="lab",site="lab-site-01"} 2.5585863e+07
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Log",net_os="eos",region="lab",site="lab-site-01"} 400150
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM",net_os="eos",region="lab",site="lab-site-01"} 1.6005976e+07
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Buffers)",net_os="eos",region="lab",site="lab-site-01"} 1.6005976e+07
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Cache)",net_os="eos",region="lab",site="lab-site-01"} 1.6005976e+07
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Unavailable)",net_os="eos",region="lab",site="lab-site-01"} 1.6005976e+07
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Root",net_os="eos",region="lab",site="lab-site-01"} 2.5585863e+07
storage_size_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Tmp",net_os="eos",region="lab",site="lab-site-01"} 16384
# HELP storage_used_allocation_units Telegraf collected metric
# TYPE storage_used_allocation_units untyped
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Core",net_os="eos",region="lab",site="lab-site-01"} 0
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Flash",net_os="eos",region="lab",site="lab-site-01"} 7.955702e+06
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Log",net_os="eos",region="lab",site="lab-site-01"} 14989
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM",net_os="eos",region="lab",site="lab-site-01"} 7.242028e+06
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Buffers)",net_os="eos",region="lab",site="lab-site-01"} 953836
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Cache)",net_os="eos",region="lab",site="lab-site-01"} 2.134188e+06
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="RAM (Unavailable)",net_os="eos",region="lab",site="lab-site-01"} 4.148248e+06
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Root",net_os="eos",region="lab",site="lab-site-01"} 7.955702e+06
storage_used_allocation_units{collection_method="snmp",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Tmp",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP cpu_instant Telegraf collected metric
# TYPE cpu_instant untyped
cpu_instant{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="CPU0",net_os="eos",region="lab",site="lab-site-01"} 3
cpu_instant{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="CPU1",net_os="eos",region="lab",site="lab-site-01"} 5
cpu_instant{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="CPU2",net_os="eos",region="lab",site="lab-site-01"} 3
cpu_instant{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="CPU3",net_os="eos",region="lab",site="lab-site-01"} 3
# HELP interface_in_broadcast_pkts Telegraf collected metric
# TYPE interface_in_broadcast_pkts untyped
interface_in_broadcast_pkts{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_crc_errors Telegraf collected metric
# TYPE interface_in_crc_errors untyped
interface_in_crc_errors{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_discards Telegraf collected metric
# TYPE interface_in_discards untyped
interface_in_discards{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_errors Telegraf collected metric
# TYPE interface_in_errors untyped
interface_in_errors{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_fcs_errors Telegraf collected metric
# TYPE interface_in_fcs_errors untyped
interface_in_fcs_errors{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_fragment_frames Telegraf collected metric
# TYPE interface_in_fragment_frames untyped
interface_in_fragment_frames{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_jabber_frames Telegraf collected metric
# TYPE interface_in_jabber_frames untyped
interface_in_jabber_frames{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_mac_control_frames Telegraf collected metric
# TYPE interface_in_mac_control_frames untyped
interface_in_mac_control_frames{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_mac_pause_frames Telegraf collected metric
# TYPE interface_in_mac_pause_frames untyped
interface_in_mac_pause_frames{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_multicast_pkts Telegraf collected metric
# TYPE interface_in_multicast_pkts untyped
interface_in_multicast_pkts{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 25
# HELP interface_in_octets Telegraf collected metric
# TYPE interface_in_octets untyped
interface_in_octets{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 4349
# HELP interface_in_oversize_frames Telegraf collected metric
# TYPE interface_in_oversize_frames untyped
interface_in_oversize_frames{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_in_unicast_pkts Telegraf collected metric
# TYPE interface_in_unicast_pkts untyped
interface_in_unicast_pkts{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 21
# HELP interface_out_broadcast_pkts Telegraf collected metric
# TYPE interface_out_broadcast_pkts untyped
interface_out_broadcast_pkts{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_out_discards Telegraf collected metric
# TYPE interface_out_discards untyped
interface_out_discards{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_out_errors Telegraf collected metric
# TYPE interface_out_errors untyped
interface_out_errors{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_out_mac_control_frames Telegraf collected metric
# TYPE interface_out_mac_control_frames untyped
interface_out_mac_control_frames{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_out_mac_pause_frames Telegraf collected metric
# TYPE interface_out_mac_pause_frames untyped
interface_out_mac_pause_frames{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_out_multicast_pkts Telegraf collected metric
# TYPE interface_out_multicast_pkts untyped
interface_out_multicast_pkts{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_out_octets Telegraf collected metric
# TYPE interface_out_octets untyped
interface_out_octets{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP interface_out_unicast_pkts Telegraf collected metric
# TYPE interface_out_unicast_pkts untyped
interface_out_unicast_pkts{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Ethernet1",net_os="eos",region="lab",site="lab-site-01"} 0
# HELP memory_available Telegraf collected metric
# TYPE memory_available untyped
memory_available{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Chassis",net_os="eos",region="lab",site="lab-site-01"} 1.6390119424e+10
# HELP memory_utilized Telegraf collected metric
# TYPE memory_utilized untyped
memory_utilized{collection_method="gnmi",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",name="Chassis",net_os="eos",region="lab",site="lab-site-01"} 7.414636544e+09
# HELP bgp_sessions_prefixes_received Telegraf collected metric
# TYPE bgp_sessions_prefixes_received untyped
bgp_sessions_prefixes_received{collection_method="execd",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",local_as="65111",neighbor_address="10.1.2.2",net_os="eos",peer_as="65222",peer_router_id="10.17.17.2",peer_type="external",region="lab",router_id="10.17.17.1",routing_instance="default",session_state="established",site="lab-site-01"} 1
bgp_sessions_prefixes_received{collection_method="execd",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",local_as="65111",neighbor_address="10.1.7.2",net_os="eos",peer_as="65222",peer_router_id="0.0.0.0",peer_type="external",region="lab",router_id="10.17.17.1",routing_instance="default",session_state="active",site="lab-site-01"} 0
# HELP bgp_sessions_prefixes_sent Telegraf collected metric
# TYPE bgp_sessions_prefixes_sent untyped
bgp_sessions_prefixes_sent{collection_method="execd",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",local_as="65111",neighbor_address="10.1.2.2",net_os="eos",peer_as="65222",peer_router_id="10.17.17.2",peer_type="external",region="lab",router_id="10.17.17.1",routing_instance="default",session_state="established",site="lab-site-01"} 1
bgp_sessions_prefixes_sent{collection_method="execd",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",local_as="65111",neighbor_address="10.1.7.2",net_os="eos",peer_as="65222",peer_router_id="0.0.0.0",peer_type="external",region="lab",router_id="10.17.17.1",routing_instance="default",session_state="active",site="lab-site-01"} 0
# HELP bgp_sessions_session_state_code Telegraf collected metric
# TYPE bgp_sessions_session_state_code untyped
bgp_sessions_session_state_code{collection_method="execd",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",local_as="65111",neighbor_address="10.1.2.2",net_os="eos",peer_as="65222",peer_router_id="10.17.17.2",peer_type="external",region="lab",router_id="10.17.17.1",routing_instance="default",session_state="established",site="lab-site-01"} 6
bgp_sessions_session_state_code{collection_method="execd",device="ceos-01",device_platform="arista",device_role="router",environment="dev",host="telegraf-01",local_as="65111",neighbor_address="10.1.7.2",net_os="eos",peer_as="65222",peer_router_id="0.0.0.0",peer_type="external",region="lab",router_id="10.17.17.1",routing_instance="default",session_state="active",site="lab-site-01"} 3