Time series databases and their query languages are tools with increasing popularity for a Network Automation Engineer. However, sometimes these tools may be overlooked by network operators for more “pressing” day-to-day workflow automation. Time series databases offer valuable network telemetry that will reveal important insights for network operations, such as security breaches, network outages, and slowdowns that degrade the user experience.
In this post, we will review the Prometheus Query Language (PromQL) to demonstrate the value and capabilities of processing time series. This review will offer use cases of PromQL for network engineers and data scientists.
What is Prometheus?
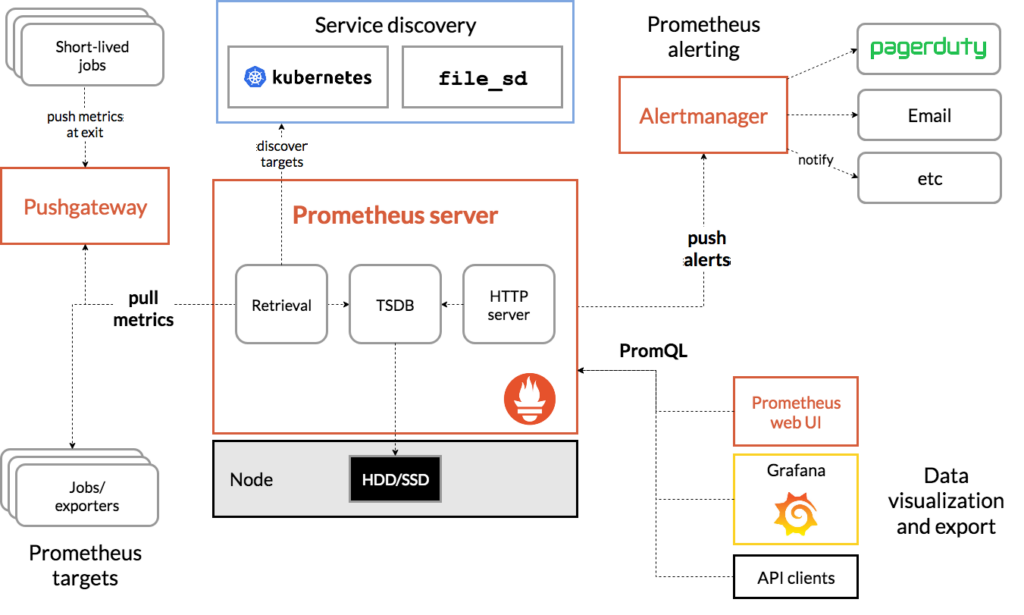
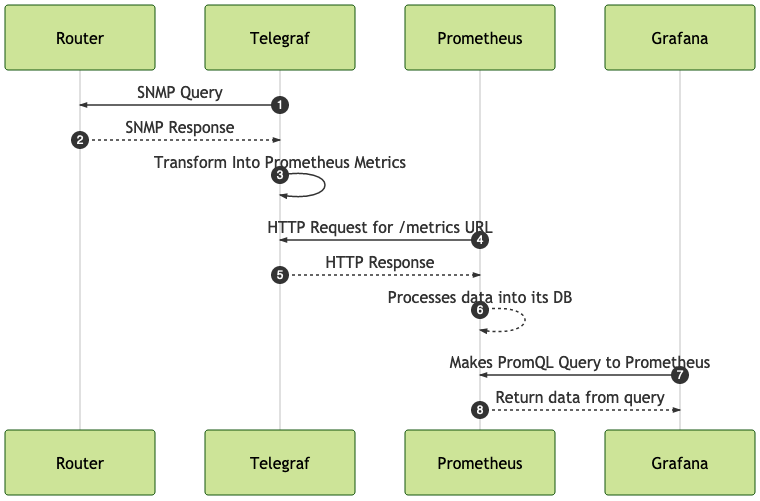
Prometheus is an open source systems monitoring and alerting toolkit. As you can see in the figure below, the heart of Prometheus includes a Time Series Database (TSDB) and the PromQL Engine. Exporters run locally on monitored hosts and export local metrics related to device health, such as CPU and memory utilization, and services, such as HTTP. The alert mechanism implemented with Prometheus, triggers alerts based on events and predefined thresholds. Prometheus has a web UI that we will be using in the examples of this post. In addition, the Prometheus measurements can be visualized using Grafana dashboards.
In simple words, it is a database that stores time series. Then, what is a time series? It is a set of time-stamps and their corresponding data. A TSDB is optimized to store these time series data efficiently, measure changes, and perform calculations over time. PromQL is the language that was built to retrieve data from the Prometheus TSDB. In networking, this could mean tracking the state of an interface or bandwidth utilization over time.
Why PromQL?
There are several other TSDBs, one of the most well known is InfluxDB. Both Prometheus TSDB and InfluxDB are excellent tools for telemetry and time series data manipulation. PromQL’s popularity has been growing fast because it is a comprehensive language to consume time series data. Multiple other solutions are starting to support PromQL, such as NewRelic that recently added support for PromQL and Timescale with Promscale.
Now that we have all the prerequisite knowledge we can dive deep into the PromQL data model and dissect language queries.
Prometheus Data Model
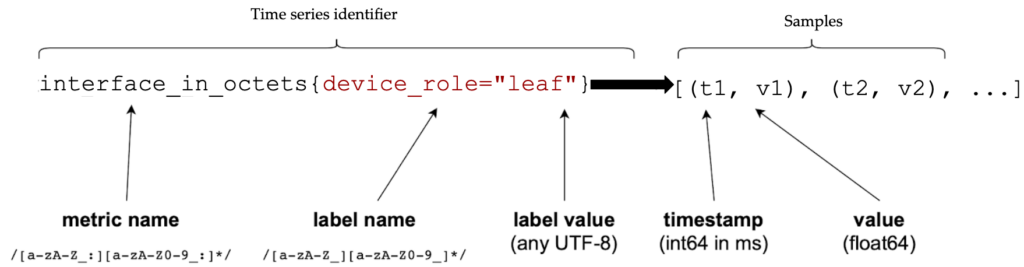
The first part of the Prometheus data model is the metric name. A metric name is uniquely identified, and it indicates what is being measured. A metric is a dimension of a specific feature. Labels are the second part of the data model. A label is a key-value pair that differentiates sub-dimensions in a metric.
Think of a metric, ex. interface_in_octets, as an object with multiple characteristics, ex., device_role. As you can see in the figure below, each label can pick a value for this characteristic, i.e. device_role="leaf". The combination of metrics and labels return a time series identifier, i.e., a list of tuples that provide the (timestamp, value) of the object with the specific characteristic. The timestamps are given in Unix time, milliseconds precision and the values that correspond to them are floating point type.
As a Network Automation Engineer you can think of many examples of metrics, such as interface_speed, bgp_hold_time, packets_dropped, etc. All these metrics can be characterized by a variety of labels, such as device_platform, host, instance, interface_name etc.
With that data model in mind, let us next dissect a query in PromQL.
The anatomy of a query
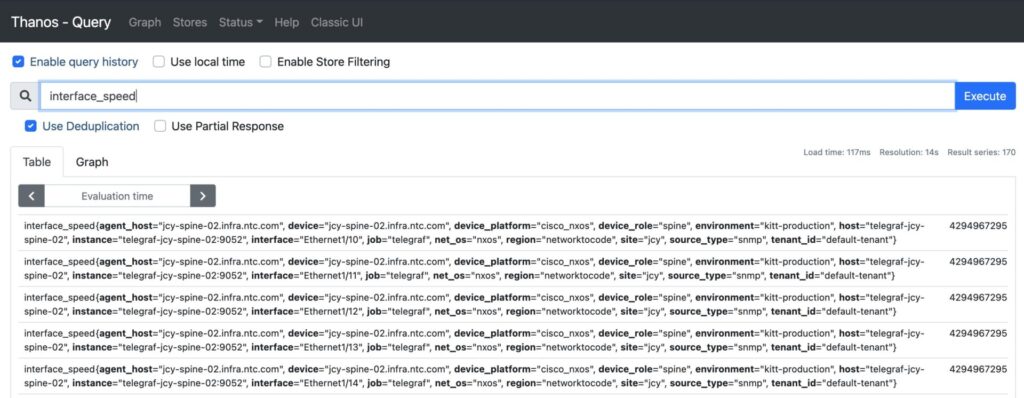
The simplest form of a PromQL query may include just a metric. This query returns multiple single value vectors, as you can see below. All the applicable labels and value combinations that these labels can be assigned are given as a result of this simple query.
Metrics
What kind of metrics does PromQL support? There are four kinds of metrics:
Counters: these are metrics that can only increase, for example: interface counters, API call counters, etc.
Gauges: the values of these metrics can go up and down, for example: bandwidth, latency, packets dropped, etc. Gauges and counters are useful for network engineers because they can measure already existent features of a system.
Summaries: this metric is useful to data scientists and if your application includes data analytics. To use this metric you need have control of what you can measure and drill into additional details. A summary metric aggregates thousands of events to one metric. Specifically it counts observations and sums all the observed values. It can also calculate quantiles of these values. If you have an application that is being monitored, you can use the summaries for API request durations.
Histograms: this is another metric that is more useful to a data scientist than a network engineer. Histogram metrics can be defined as summaries that are “bucketized”. Specifically they count observations and place them in configurable buckets. A histogram can be used to measure response sizes on an application.
Label Filtering
Now that we know what kinds of metrics we can include in our query, let us review how we can filter the query to retrieve more specific and meaningful results. This can be done with label filtering that includes the following operations:
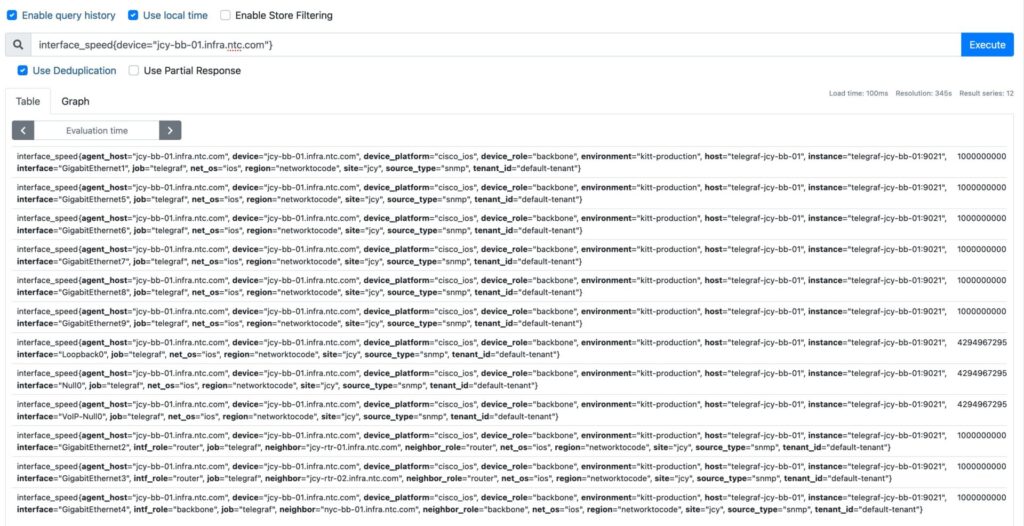
# equal, returns interfacespeedfordevicewithnamejcy-bb-01interface_speed{device="jcy-bb-01.infra.ntc.com"}# not equal, returns the opposite of the above queryinterface_speed{device!="jcy-bb-01.infra.ntc.com"}# regex-match, matches interfaceEthernet{1,2,3,4,5,6,7}interface_speed{interface=~"Ethernet1/[1-7]"}# not regex-match, returns the opposite of the above queryinterface_speed{interface!~"Ethernet1/[1-7]"}
Not only can you use the equal and not equal signs to filter your queries, but you can filter using regular expressions. To learn more about regular expressions for network engineers, check our previous blog.
Functions
One of my favorite parts of PromQL are the functions that can manipulate the time series identifiers. Below, I include an example of the function rate(), that is useful for network metrics, and the function predict_linear(), that is useful if you perform data analytics.
How fast does a counter change?
The function rate() can be used with counter metrics to demonstrate how fast a counter increases. Specifically, it calculates the per second increase for a time period. This is a useful function to the network engineer, since counters are a common metric applied in networks. For example packet counting, interface octets counting are counters and the rate() function offers useful insights on how these counters increase.
#per second increase of counter averaged over 5 minsrate(interface_in_octets{device_role="leaf"}[5m])
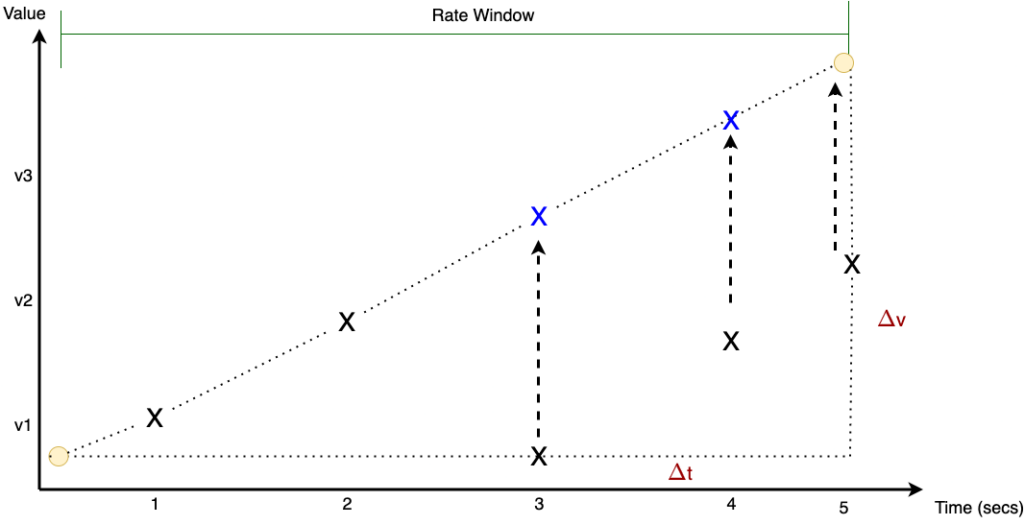
The next figure will help you understand the details of how the rate() function is calculated. The interval $\Delta$t indicates the time interval during which we want to calculate the rate. The X marks indicate the per second samples that are used to calculate multiple rates per second. The rate() function averages these calculations during the interval $\Delta$t. If the counter is reset to 0, the rate() function will extrapolate the sample as can be seen with the blue X marks.
Instance vs. Range Vectors
You probably have noticed that the example of the rate() function above, uses a different type of syntax. Specifically it identifies the time series during an interval, from the example above the interval is 5 minutes ([5m]). This results to a range vector, where the time-series identifier returns the values for a given period, in this case 5 minutes. On the other hand, an instance vector returns one value, specifically the single latest value of a time series. The figures below shows the differences in the results of an instance vector versus a range vector.
In the first figure, only one value per vector is returned whereas in the second, multiple values that span in the range of 5 minutes are returned for each vector. The format of these values is: value@timestamp.
Offsets
You may be wondering: all of this is great, but where is the “time” in my “time-series”? The offset part of the query can retrieve data for a specific time interval. For example:
Here we combine the function rate(), that samples the interface_in_octets counter every second for five minutes, with offset that gives us historical data for the past 24 hours.
Can I predict the next 24 hours?
Of course! PromQL provides the function predict_linear(), a simple machine learning model that predicts the value of a gauge in a given amount of time in the future, by using linear regression. This function is of more interest to a data scientist that wants to create forecasting models. For example, if you want to predict the disk usage in bytes within the next hour based on historic data, you would use the following query:
#predict disk usage bytes in an hour,using the last 15 mins of datapredict_linear(demo_disk_usage_bytes{job="demo"}[15m],3600)
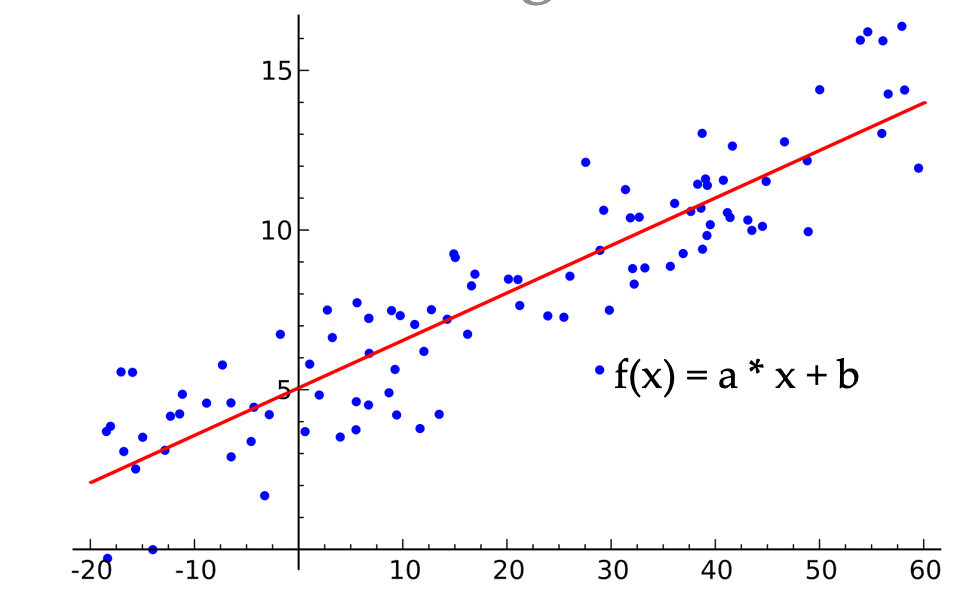
Linear regression fits a linear function to a set of random data points. This is achieved by searching for all possible values for the variables a, b that define a linear function f(x)=ax+b. The line that minimizes the mean Euclidean distance of all these data points is the result of the linear regression model, as you can see in the image below:
Aggregation
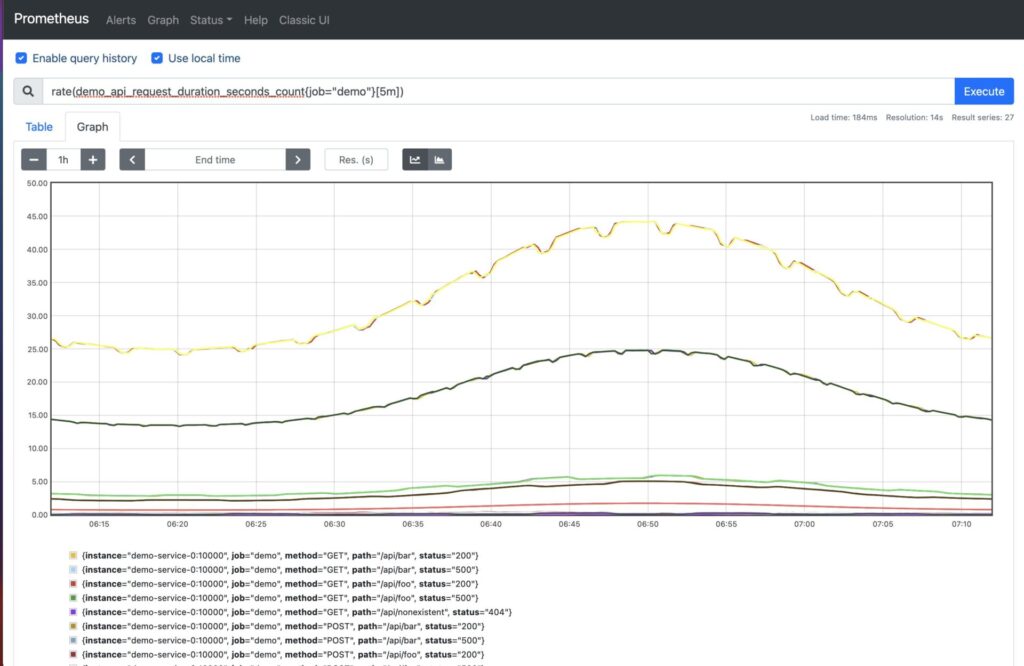
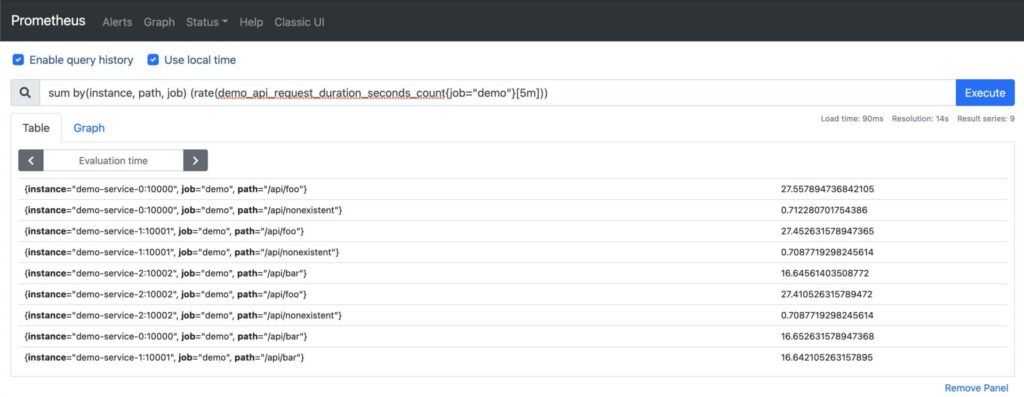
PromQL queries can be highly dimensional. This means that one query can return a set of time series identifiers for all the combinations of labels, as you can see below:
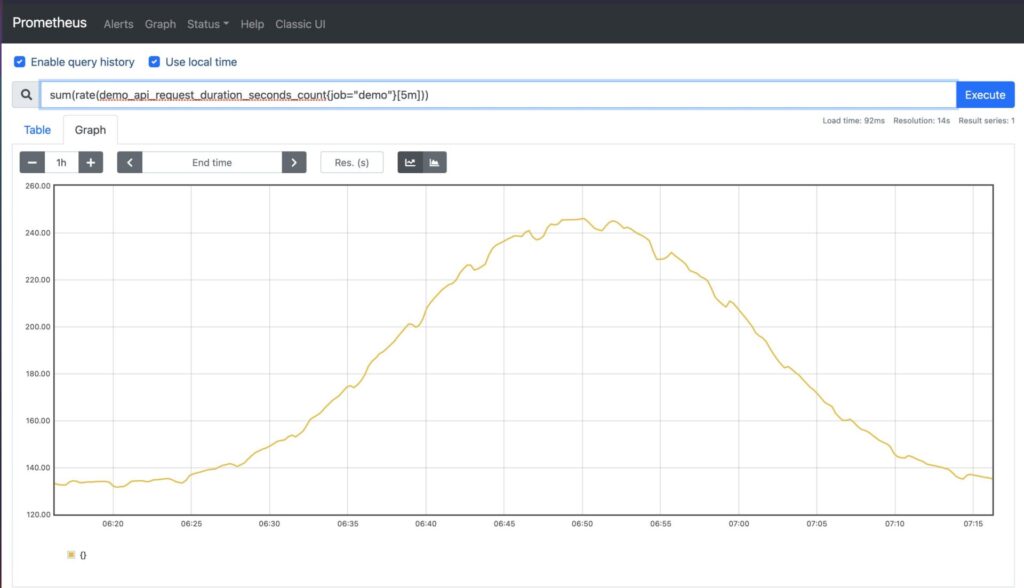
What if you want to reduce the dimensions to a more meaningful result, for example the sum of all the API request durations in seconds? This would result in a single-dimension query that is the result of adding multiple instance vectors together:
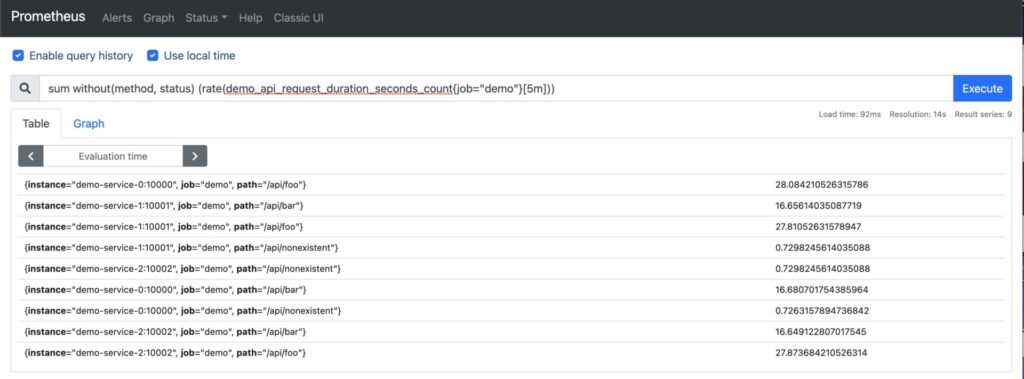
You may choose to aggregate over specific dimensions using labels and the function by(). In the example below, we perform a sum over all instances, paths, and jobs. Note the reduction of the number of vectors returned:
Thank you for taking this journey with me, learning about the time series query language, PromQL. There are many more features to this language such as arithmetic, sorting, set functions etc. I hope that this post has given you the opportunity to understand the basics of PromQL, see the value of telemetry and TSDBs, and that it has increased your curiosity to learn more.
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
This is going to be the first in a multipart series where I will be taking a look at a method to get telemetry data from network devices into a modern Time Series Database (TSDB).
In this particular post I will be working through adding SNMP based device data into the Prometheus TSDB. I will be using Telegraf from InfluxData to gather the SNMP data from Cisco devices on an emulation platform. Prometheus will then scrape the data from Telegraf and store the metrics. I will then show in how to start building out graphs within Grafana.
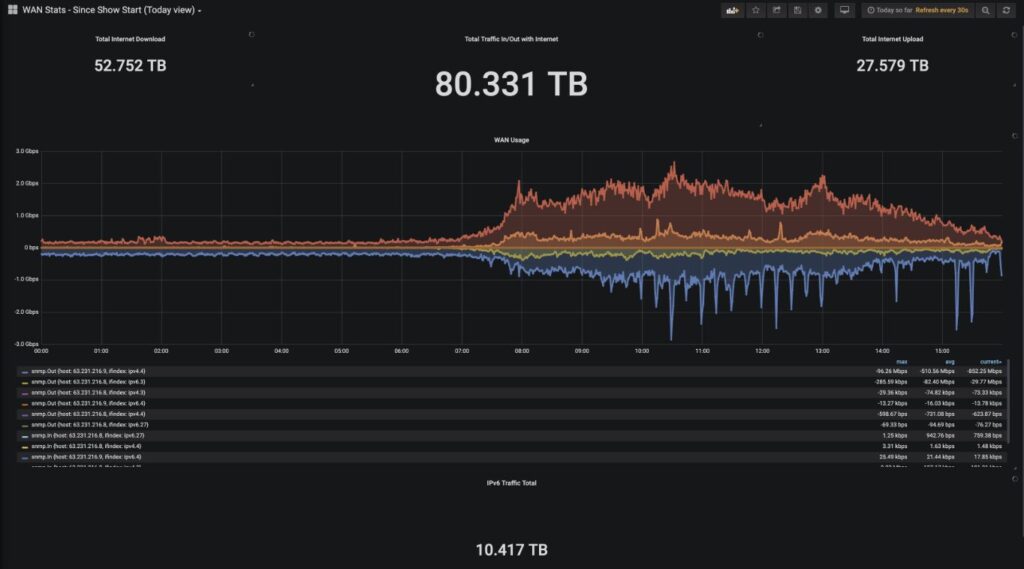
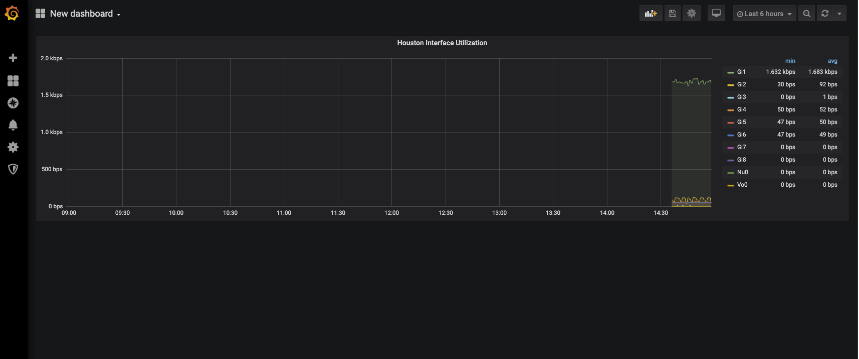
Here is an example of a Grafana dashboard that could be made:
At this point there are many advertisements that Streaming Telemetry is a must have in this day and age for gathering network device metrics. However, there are still quite a few network devices that do not support Streaming Telemetry in networks today. If you have a large deployment of these types of devices are you out of luck if you want to use a modern TSDBs? No you are not. Gathering data into a TSDB is all about just that, gathering data. If you gather the data via Streaming Telemetry or SNMP, either way, you are gathering the data. Streaming Telemetry is generally thought of as less intensive of a process on devices and has some other benefits. So if you can gather the data with Streaming Telemetry, then you should. But if you must use SNMP, this article is here to help you out.
Gathering Data – CLI Parsing
Through this post you will see information gathered via SNMP. If you wish to look at using CLI parsing as a method to get metrics, take a look at our previous post.
Gathering Data via SNMP
This post will outline what Telegraf has to offer when it comes to gathering data. Telegraf is an application made available by InfluxData that will gather data from various places. The gathering of information is known as an input. Then you will see how to send or make the data available for TSDB – Prometheus. These are known as the outputs. You can take a look at the plugins list to see the list of plugins for Telegraf 1.14, which as of this writing (2020-04-21) is the latest version.
Telegraf has the capability to also transform, tag, and modify data as needed. Portions of that will be covered in a follow-up post.
Within the configuration files you can setup to have a single Telegraf process poll multiple devices or you can have multiple Telegraf processes or containers, with each one polling one device. In this post I will be showing how to configure a single device to be polled by Telegraf. By this nature you can have your Telegraf agents centralized or distributed as needed.
A Prometheus nuance is that Prometheus will assume a device is down if Prometheus is unable to scrape the device’s metric page. But collecting SNMP data, the collection will be of the Telegraf process, which should get tied to its ability to poll the device. So additional configuration will be needed for Prometheus alerting in respects to reading metrics from a Telegraf plugin.
The SNMP configuration is made within the Telegraf configuration. This configuration may look like the following:
[[inputs.snmp]] agents = ["minneapolis.ntc"] version =2 community ="SecuredSNMPString" interval ="60s" timeout ="10s" retries =3 [[inputs.snmp.field]] name ="hostname" oid =".1.3.6.1.2.1.1.5.0" is_tag =true [[inputs.snmp.field]] name ="uptime" oid ="1.3.6.1.2.1.1.3.0" [[inputs.snmp.field]] name ="cpmCPUTotal1min" oid =".1.3.6.1.4.1.9.9.109.1.1.1.1.4.7" ##################################################### # # Gather Interface Statistics via SNMP # ##################################################### # IF-MIB::ifTable contains counters on input and output traffic aswellaserrorsanddiscards. [[inputs.snmp.table]] name ="interface" inherit_tags = [ "hostname" ] oid ="IF-MIB::ifTable" # Interface tag - used to identify interfaceinmetricsdatabase [[inputs.snmp.table.field]]name = "name"oid = "IF-MIB::ifDescr"is_tag = true # IF-MIB::ifXTablecontainsnewerHighCapacity (HC) countersthatdonotoverflowasfastforafewoftheifTablecounters [[inputs.snmp.table]]name = "interface"inherit_tags = [ "hostname" ]oid = "IF-MIB::ifXTable" # Interfacetag - usedtoidentifyinterfaceinmetricsdatabase [[inputs.snmp.table.field]]name = "name"oid = "IF-MIB::ifDescr"is_tag = true # EtherLike-MIB::dot3StatsTablecontainsdetailedethernet-levelinformationaboutwhatkindoferrorshavebeenloggedonaninterface (suchasFCSerror, frametoolong, etc) [[inputs.snmp.table]]name = "interface"inherit_tags = [ "hostname" ]oid = "EtherLike-MIB::dot3StatsTable" # Interfacetag - usedtoidentifyinterfaceinmetricsdatabase [[inputs.snmp.table.field]]name = "name"oid = "IF-MIB::ifDescr"is_tag = true
Note: In testing I have found that the Cisco CPU query can be different per device. I recommend testing per platform and perhaps per OS version to verify that the SNMP polling works properly. I have found that issuing the command snmpwalk -v 2c -c SecuredSNMPString minneapolis.ntc .1.3.6.1.4.1.9.9.109.1.1.1.1.4 to find the response. You can also look at some other SNMP OIDs available as well for Cisco at their doc page
Difference Between snmp.table and snmp.field
Now, we’ll briefly dig in to what each of the lines are doing here. When an SNMP field is defined, this is going to act like an snmpget on a device. The first section that we call hostname is getting the hostname of the device.
What is a Tag?
The is_tag will be used as a tag on the data that is called later. Tags are data points that will help to classify other pieces of information. This can be helpful in filtering data points, or associating data points with a particular query or other data point.
Tags will be covered in more detail in a subsequent post, but note that by leveraging tags in your templates that build the Telegraf configuration you are able to identify key components in the environment that will enhance the monitoring capabilities.
Jumping ahead, and using the Prometheus output you can see some of these tags and fields in action. snmp_ is added to the front of the name as a part of the Prometheus export. You are able see the result of the query on the right most, outside of the {}. Inside of the {} you have the various tags that are being applied.
# HELP snmp_cpmCPUTotal1min Telegraf collected metric# TYPE snmp_cpmCPUTotal1min untypedsnmp_cpmCPUTotal1min{agent_host="minneapolis.ntc",device="minneapolis",host="225bb1fc7f4c",hostname="minneapolis.ntc",}31# HELP snmp_uptime Telegraf collected metric# TYPE snmp_uptime untypedsnmp_uptime{agent_host="minneapolis.ntc",device="minneapolis",host="225bb1fc7f4c",hostname="minneapolis.ntc",}1.2636057e+07
Exporting the SNMP Data
There are two majority leaders in my opinion in the open source TSDB market, InfluxDB and Prometheus. Both have outputs that you can leverage with Telegraf to get the data into the TSDB. I will focus on the Prometheus methodology here. By exporting data with the Prometheus output there are a couple of benefits. One, the data is able to be scraped by the Prometheus system. The second is you can get a very good visual representation of the data for troubleshooting your connections.
If you are using InfluxDB as your DB and need to troubleshoot, I find setting up a Prometheus exporter as a helpful step to be able to see what tags are being defined and what data is being gathered from an SNMP standpoint.
Output to Prometheus Configuration
The configuration for Telegraf to use the Prometheus metrics exporter is relatively short and sweet. Telegraf handles the heavy lifting once you set the configuration file.
####################################################### Export SNMP Information to Prometheus######################################################[[outputs.prometheus_client]] listen =":9012" metric_version =2
Here you see that the section begins with [[outputs.prometheus_client]]. This is with no indentation within the configuration file. It sets the metric_version to 2, and then sets a port that the metrics will be exposed at on, here tcp/9012. The url is then http://<server_url/ip>:<listen_port>/metrics. Note the /metrics as defined is a best practice of Prometheus.
Let’s take a look at the output from the metrics page below. There are many more metrics that get exposed than just what is shown. This will show only the one related to octets inbound on the interface.
Prometheus Output
Within the tags you see the main metric name begins with interface_. This is added by the client exporter to assist in classification of the metric. You then see the actual metric name as collected by SNMP. Here it is appended to the end of interface_ to get the metric name.
You also see the tags that are assigned to the metric being presented. Below is a table of the tag and where it came from:
Tag
Came From
agent_host
Created by Telegraf
host
Host that is collecting the data, here the name of the Docker container
hostname
Tag defined within the input section for gathering the hostname, the input section specifies inherit_tags to inherit the hostname
ifName
Within the inputs.snmp.table.field section of the ifTable, noted by is_tag
name
The name of the interface, defined in the input section
After the tags, the Prometheus metric definition indicates that this is where the actual measurement is to be placed. The Prometheus engine will “scrape” this information from the HTTP page and then ingest the data appropriately into its DB.
# HELP interface_ifHCInOctets Telegraf collected metric# TYPE interface_ifHCInOctets untypedinterface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Gi1",name="GigabitEthernet1"}2.4956199e+07interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Gi7",name="GigabitEthernet7"}0interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Gi8",name="GigabitEthernet8",}0interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Nu0",name="Null0",}0interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Vo0",name="VoIP-Null0",}0interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Gi3",name="GigabitEthernet3",}1.092917e+08interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Gi2",name="GigabitEthernet2",}1.477766e+06interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Gi4",name="GigabitEthernet4",}1.9447063e+07interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Gi5",name="GigabitEthernet5",}1.2468643e+07interface_ifHCInOctets{agent_host="minneapolis.ntc",host="225bb1fc7f4c",hostname="minneapolis.ntc",ifName="Gi6",name="GigabitEthernet6",}1.6549974e+07
Prometheus
After getting the data into a format that Prometheus can read, you need to install Prometheus. You will get a link for the long lived installation, but the best part about Prometheus is that you can get up and running by just executing the binary file.
Installation – Binary Execution
Link: Prometheus installation provides for documentation on getting Prometheus up and running on your system.
Installation – Download, Decompress, and Copy Binary to Local Folder
josh@prometheus_demo:~$ tar -xvzf prometheus-2.16.0.linux-amd64.tar.gzprometheus-2.16.0.linux-amd64/prometheus-2.16.0.linux-amd64/LICENSEprometheus-2.16.0.linux-amd64/promtoolprometheus-2.16.0.linux-amd64/NOTICEprometheus-2.16.0.linux-amd64/consoles/prometheus-2.16.0.linux-amd64/consoles/node.htmlprometheus-2.16.0.linux-amd64/consoles/index.html.exampleprometheus-2.16.0.linux-amd64/consoles/prometheus-overview.htmlprometheus-2.16.0.linux-amd64/consoles/node-disk.htmlprometheus-2.16.0.linux-amd64/consoles/node-overview.htmlprometheus-2.16.0.linux-amd64/consoles/node-cpu.htmlprometheus-2.16.0.linux-amd64/consoles/prometheus.htmlprometheus-2.16.0.linux-amd64/console_libraries/prometheus-2.16.0.linux-amd64/console_libraries/menu.libprometheus-2.16.0.linux-amd64/console_libraries/prom.libprometheus-2.16.0.linux-amd64/prometheusprometheus-2.16.0.linux-amd64/prometheus.ymlprometheus-2.16.0.linux-amd64/tsdb
cp prometheus-2.16.0.linux-amd64/prometheus .
Create a Base Configuration on Host
You can use this as a start of the configuration, it will be stored in the same local directory that you are working in. It is setting a default scrape interval for other jobs that do not have a scrape_interval set to 15s. The example will use prometheus_config.yml for the file name.
Now that there is a configuration file ready to go, you can start the local server. This will start up without polling anything other than the local Prometheus instance.
josh@prometheus_demo:~$ ./prometheus --config.file="prometheus_config.yml"level=info ts=2020-03-14T18:29:50.782Z caller=main.go:295 msg="no time or size retention was set so using the default time retention" duration=15dlevel=info ts=2020-03-14T18:29:50.783Z caller=main.go:331 msg="Starting Prometheus" version="(version=2.16.0, branch=HEAD, revision=b90be6f32a33c03163d700e1452b54454ddce0ec)"level=info ts=2020-03-14T18:29:50.783Z caller=main.go:332 build_context="(go=go1.13.8, user=root@7ea0ae865f12, date=20200213-23:50:02)"level=info ts=2020-03-14T18:29:50.783Z caller=main.go:333 host_details="(Linux 4.15.0-88-generic #88-Ubuntu SMP Tue Feb 11 20:11:34 UTC 2020 x86_64 prometheus_demo (none))"level=info ts=2020-03-14T18:29:50.783Z caller=main.go:334 fd_limits="(soft=1024, hard=1048576)"level=info ts=2020-03-14T18:29:50.783Z caller=main.go:335 vm_limits="(soft=unlimited, hard=unlimited)"level=info ts=2020-03-14T18:29:50.784Z caller=web.go:508 component=web msg="Start listening for connections" address=0.0.0.0:9090level=info ts=2020-03-14T18:29:50.784Z caller=main.go:661 msg="Starting TSDB ..."level=info ts=2020-03-14T18:29:50.788Z caller=head.go:577 component=tsdb msg="replaying WAL, this may take awhile"level=info ts=2020-03-14T18:29:50.788Z caller=head.go:625 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=2level=info ts=2020-03-14T18:29:50.788Z caller=head.go:625 component=tsdb msg="WAL segment loaded" segment=1 maxSegment=2level=info ts=2020-03-14T18:29:50.788Z caller=head.go:625 component=tsdb msg="WAL segment loaded" segment=2 maxSegment=2level=info ts=2020-03-14T18:29:50.789Z caller=main.go:676 fs_type=EXT4_SUPER_MAGIClevel=info ts=2020-03-14T18:29:50.789Z caller=main.go:677 msg="TSDB started"level=info ts=2020-03-14T18:29:50.790Z caller=main.go:747 msg="Loading configuration file" filename=prometheus_config.ymllevel=info ts=2020-03-14T18:29:50.790Z caller=main.go:775 msg="Completed loading of configuration file" filename=prometheus_config.ymllevel=info ts=2020-03-14T18:29:50.790Z caller=main.go:630 msg="Server is ready to receive web requests."
At the end you should see a message that states that the Server is ready to receive web requests.
Prometheus
With a web browser, open to the URL: http://<server_ip>:9090 or if using a local installation http://localhost:9090 which should add a redirect to /graph and bring you to a screen like this:
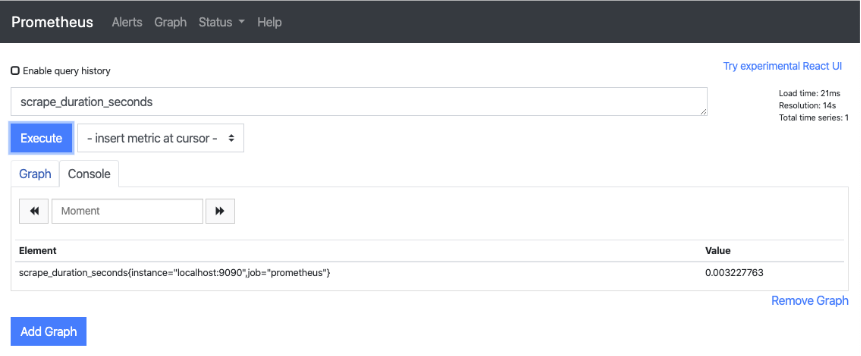
Once you have Prometheus loaded, you can start to use PromQL to do a few searches. The system currently only has one metric source, about itself. This is where a query to see what the process looks like can be done. In the search box enter the query scrape_duration_seconds and click Execute. A response is given back in text form that has an Element and a Value to it.
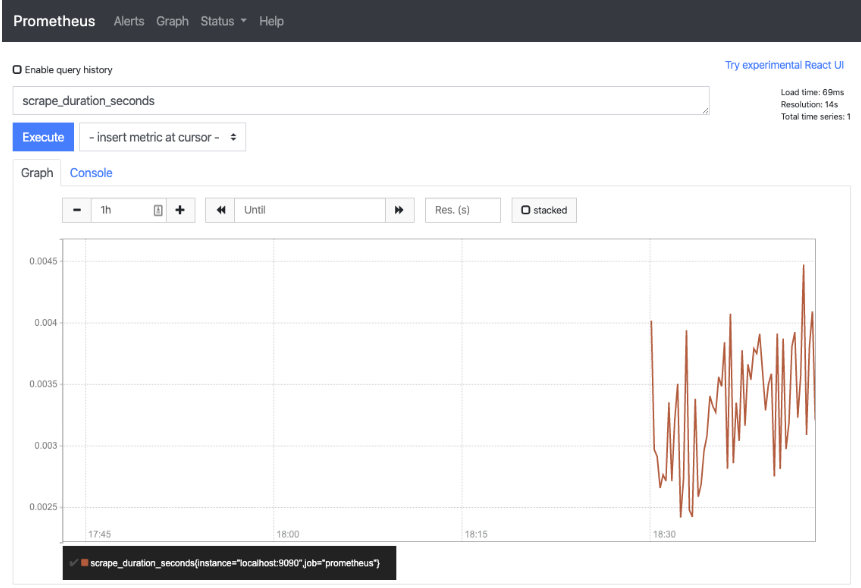
When changing to view the graph of these queries you start to see what may be possible within this time series DB.
Update and Add Network URLs to the Prometheus Config
Now the configuration will get updated to poll two hosts that have SNMP working on it. You see that the http:// and /metrics portions are removed. If not supplied these are applied by default. The prometheus_config.yml file will now look like below:
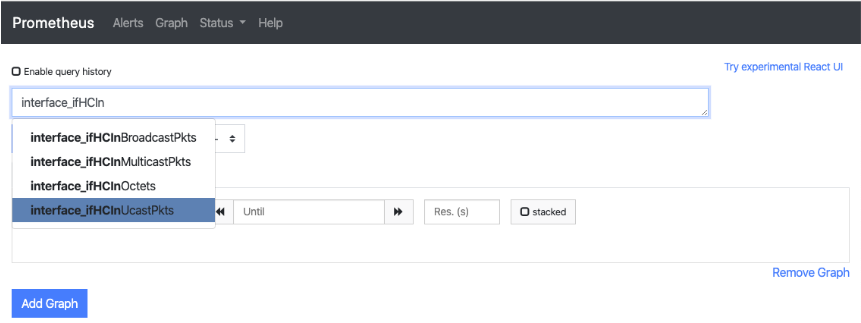
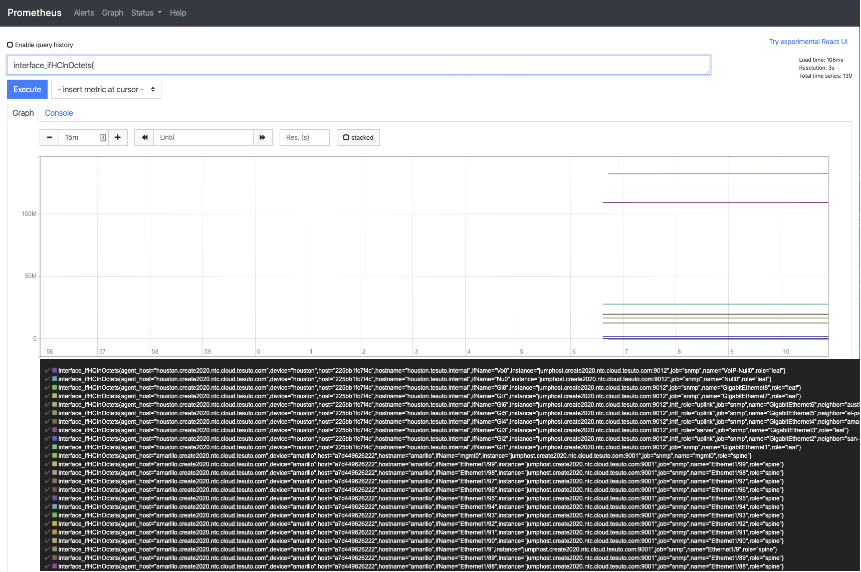
After updating the Prometheus configuration and starting the Prometheus server you can now start to get SNMP data into the graph form. Now updating the PromQL to query for interface_ifHCInOctets you can start to see what the data is that Prometheus is getting from the SNMP data that Telegraf is presenting.
This is all nice, but it is hardly a system that will have a lot of graphs and be something to present to others. This is the role that Grafana will play as a graphing engine.
josh@prometheus_demo:~$ wget https://dl.grafana.com/oss/release/grafana_6.6.2_amd64.debjosh@prometheus_demo:~$ wget https://dl.grafana.com/oss/release/grafana_6.6.2_amd64.deb--2020-03-1519:21:08--https://dl.grafana.com/oss/release/grafana_6.6.2_amd64.debResolving dl.grafana.com (dl.grafana.com)... 2a04:4e42:3b::729,151.101.250.217Connecting to dl.grafana.com (dl.grafana.com)|2a04:4e42:3b::729|:443... connected.HTTP request sent, awaiting response...200 OKLength:63232320 (60M) [application/x-debian-package]Saving to: ‘grafana_6.6.2_amd64.deb’grafana_6.6.2_amd64.deb 100%[==========================================================================================>] 60.30M 19.8MB/s in 3.1s2020-03-1519:21:12 (19.8 MB/s) - ‘grafana_6.6.2_amd64.deb’ saved [63232320/63232320]josh@prometheus_demo:~$ sudo dpkg -i grafana_6.6.2_amd64.debSelecting previously unselected package grafana.(Reading database ...67127 files and directories currently installed.)Preparing to unpack grafana_6.6.2_amd64.deb ...Unpacking grafana (6.6.2) ...Setting up grafana (6.6.2) ...Adding system user `grafana' (UID 111) ...Adding new user `grafana' (UID 111) with group `grafana'...Not creating home directory `/usr/share/grafana'.### NOT starting on installation, please execute the following statements to configure grafana to start automatically using systemd sudo /bin/systemctl daemon-reload sudo /bin/systemctl enable grafana-server### You can start grafana-server by executing sudo /bin/systemctl start grafana-serverProcessing triggers for systemd (237-3ubuntu10.39) ...Processing triggers for ureadahead (0.100.0-21) ...
Enable Grafana to Start on Boot and Start Grafana Server
josh@prometheus_demo:~$ sudo /bin/systemctl daemon-reloadjosh@prometheus_demo:~$ sudo systemctl enable grafana-serverSynchronizing state of grafana-server.service with SysV service script with/lib/systemd/systemd-sysv-install.Executing:/lib/systemd/systemd-sysv-install enable grafana-serverCreated symlink /etc/systemd/system/multi-user.target.wants/grafana-server.service → /usr/lib/systemd/system/grafana-server.service.josh@prometheus_demo:~$ sudo systemctl start grafana-server
Verify Grafana is Running
I like to verify that Grafana is in fact running by checking for the listening ports. You can do this by using the ss -lt command to get the output, and checking that there is a *:3000 entry in the output. TCP/3000 is the default port for Grafana.
josh@prometheus_demo:~$ ss -ltState Recv-Q Send-Q Local Address:Port Peer Address:PortLISTEN 0128127.0.0.53%lo:domain 0.0.0.0:*LISTEN 01280.0.0.0:ssh 0.0.0.0:*LISTEN 0128 [::]:ssh [::]:*LISTEN 0128*:3000*:*
Verify – Navigate to the Default Page
The default login is admin/admin. When you first log in you will be prompted for a new admin password.
Getting to the Graphing
Re-start Prometheus
Before you add in additional data sources that are needed, you need to restart the service on your Linux host.
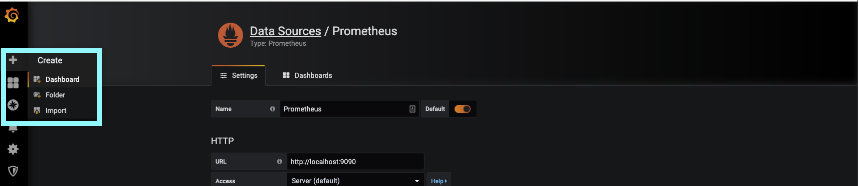
Now that you are in you need to add a data source for Grafana. In this demo you are going to see us add a localhost connection to Prometheus. Going back to the web interface on the main menu that you started into you can click on Add datasource.
In this instance of 6.6.x Grafana had Prometheus on the top of the list. Navigate to where you see Prometheus and click select.
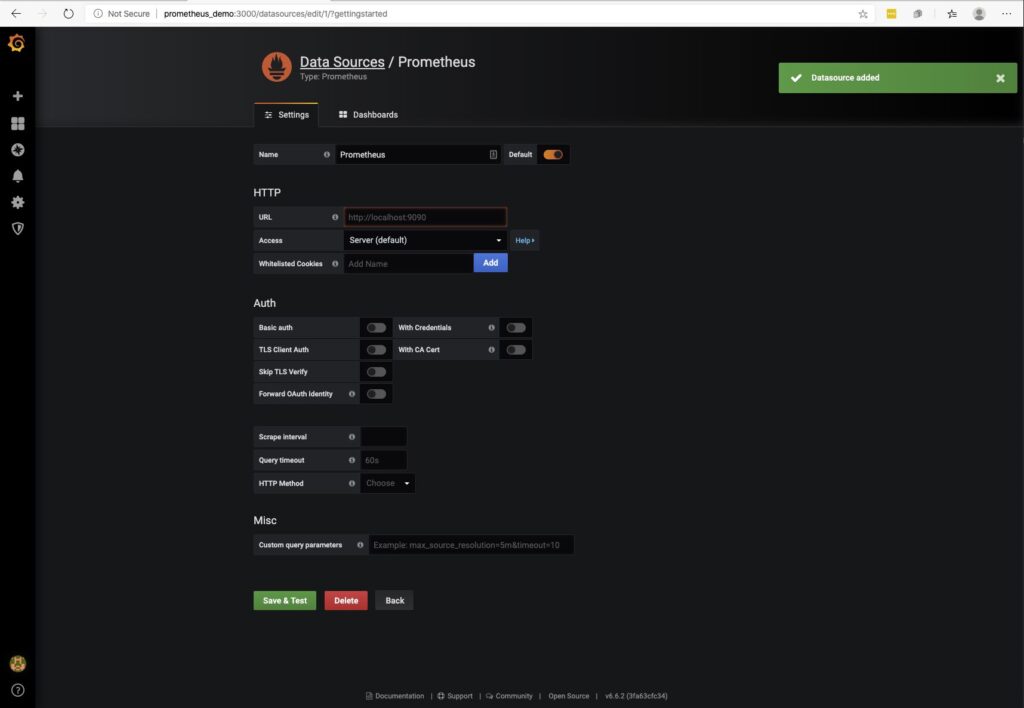
The data source will bring you to a configuration screen.
Here make the following changes:
Field Changes from Default
Field
Setting
URL
http://localhost:9090
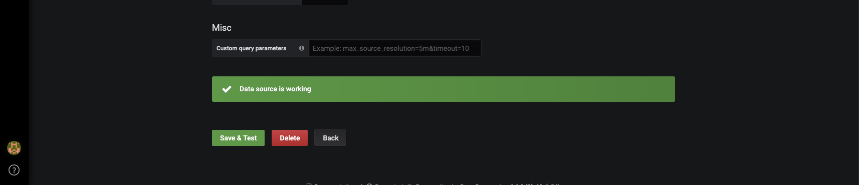
Once modified, click Save and Test to test and verify connectivity to the DB. If you setup a different host as the Prometheus server, then you would enter the hostname/IP address combination that corresponds to the Prometheus host.
When you get the message Data source is working you have successfully connected.
Grafana Dashboard Creation
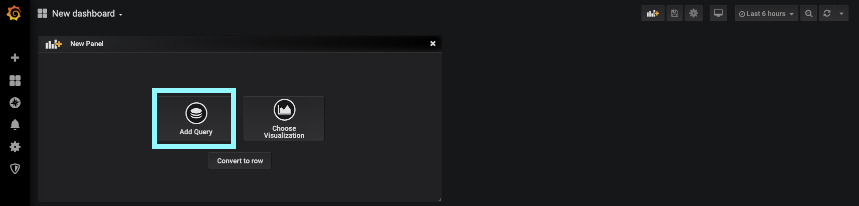
Now navigate to the left hand navigation and select the plus icon, select Dashboard to get a new dashboard created.
You get a new panel page, and then select Add Query.
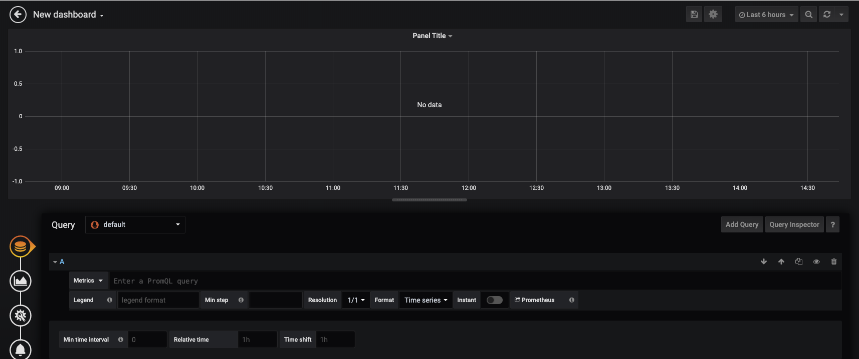
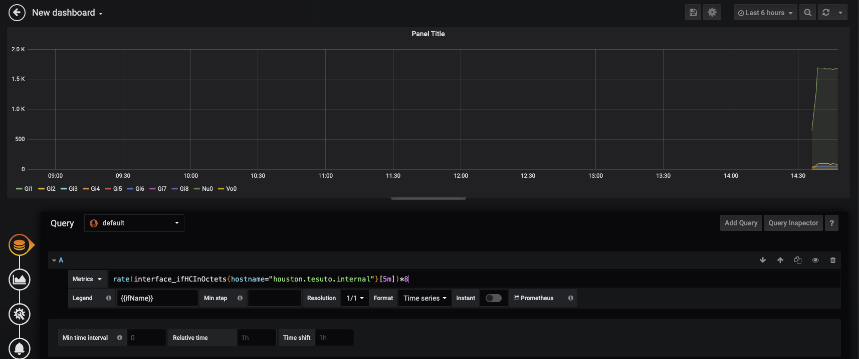
Once on the new query page we will set a search to get the Inbound utilization on an interface. Set up the query as follows:
Note that the queries used on this Grafana example are going to be of PromQL – the Prometheus Query Langague. In this graphic, the {{ifName}} is telling Grafana that ifName is the variable to lookup to add to the legend for each measurement.
If your data source for Grafana is Graphite or InfluxDB, you would use the same query language used by the database system of the data source.
To explain what each item is doing to help generate your own queries. Given the following PromQL query:
The rate query from Prometheus covers the rate of change. With SNMP, the number gathered for Interface utilization is an increasing number, not a rate. So the Prometheus system needs to calculate what that rate is. The [2m] indicates to calculate the per-second rate measured over the past 2 minutes.
Metric Name
The metric name in the query is interface_ifHCInOctets. This is the metric that was taken a look at earlier in the post. This is the exact measurement.
Query Tags
The tags in the search is to help filter out what is being searched upon to give the proper graph. In this instance you will only see interfaces on the device hostname houston.tesuto.internal.
Math
In the query there is a *8 at the end. This is to convert the measurement from octets as defined in the metric over to bits. An octet is 8 bits, thus the multiplication by 8.
Visualization Changes
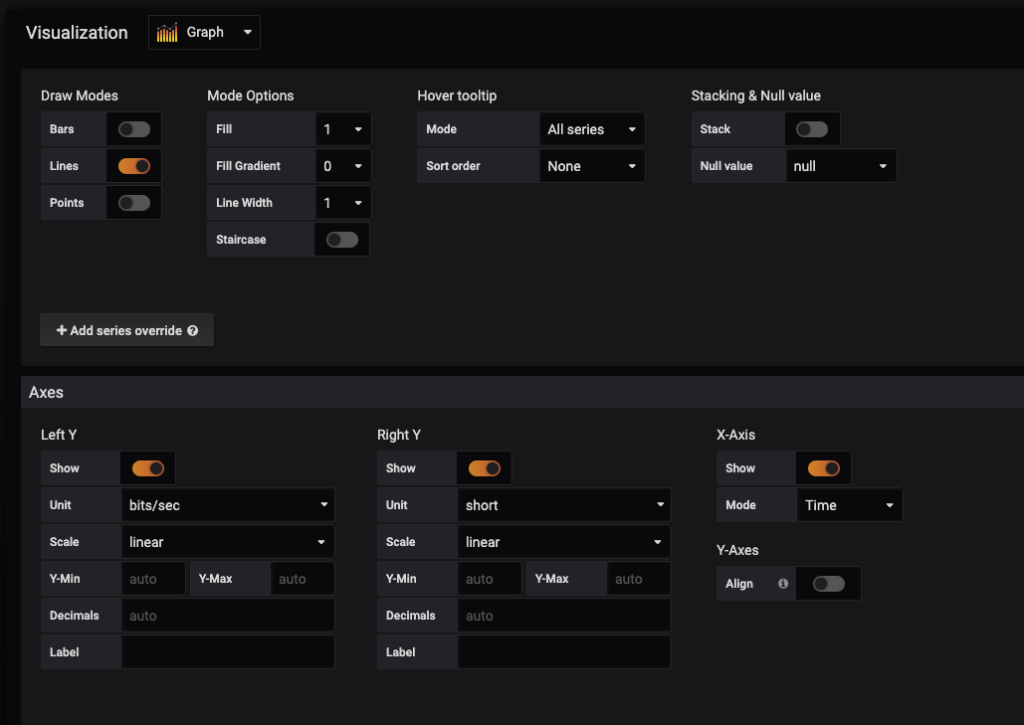
Now we’re going to make a few more updates on the graph. Here are the changes being made on the Visualization section (2nd of four items on the left hand side of the panel configuration). Specifically, the changes being made are in the Axis subsection. You can play around with settings in the upper section to get some changes made to the graphs.
Setting
Modification
Left Y: Unit
bits/sec (under Data Rate)
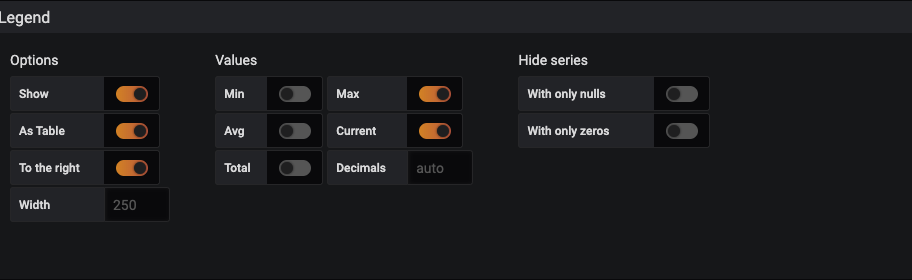
Legend Values: Min
Checked
Legend Values: Avg
Checked
As Table
Checked
To Right
Checked
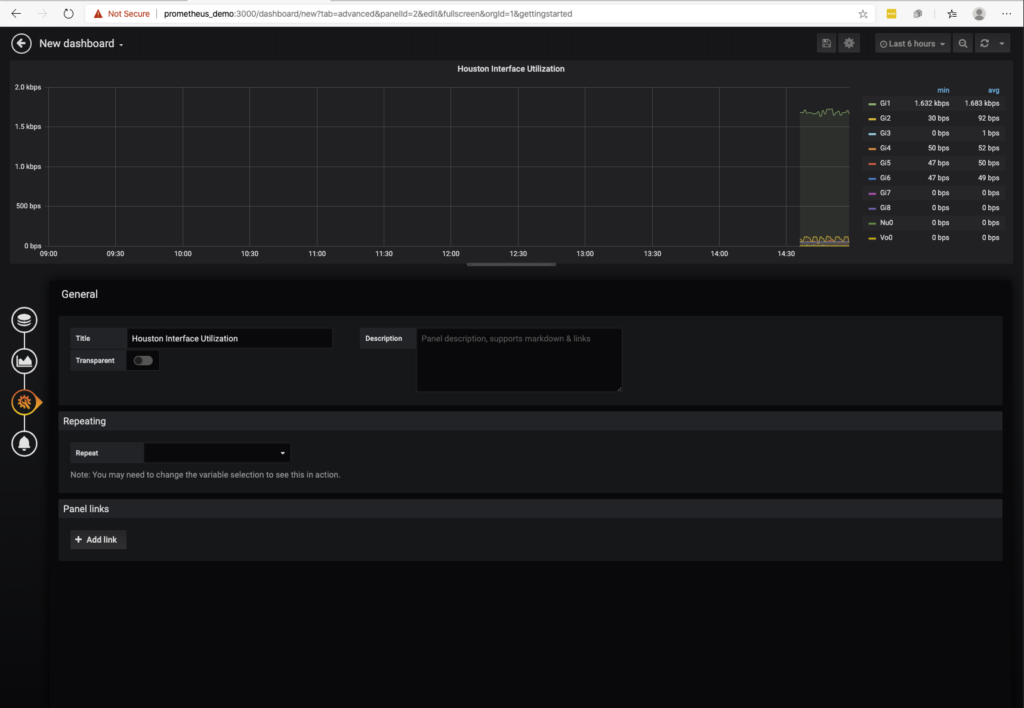
General Section Changes
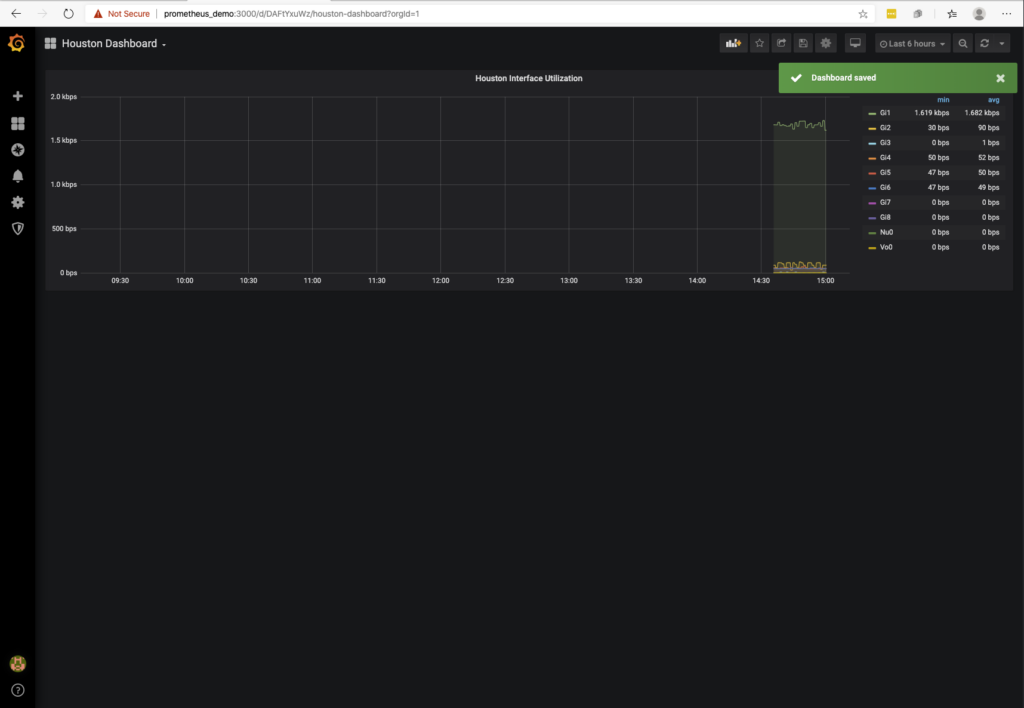
Here is where you can set the title of the panel. Let’s change that to Houston Interface Utilization. After making the update, click on the upper left to go back to the dashboard.
The panel size can be adjusted in size by dragging the corners as you see fit to make your dashboard.
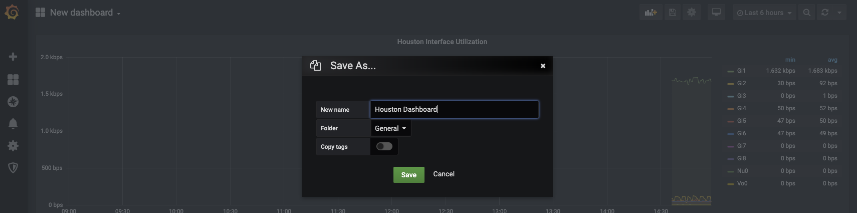
Update Dashboard Name
On the main dashboard page to change the name on the dashboard select the Save icon on the upper right. This will give you a prompt with a New Name and Folder to save the dashboard into. This allows you to add heirarchy to your dashboarding system.
Important Note – if you make changes you do need to save the changes. Grafana as of this version does not save changes after a change. It does require you to save your changes once you are done making changes.
After you save the changes you get a visual confirmation that the changes are saved and that you now have a title on dashboard!
Conclusion
Hopefully this will help on your journey! In a follow-up post I will take a look at a few more capabilities within Telegraf, Prometheus, and Grafana.
Does this all sound amazing? Want to know more about how Network to Code can help you do this, reach out to our sales team. If you want to help make this a reality for our clients, check out our careers page.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. In case of sale of your personal information, you may opt out by using the link Do not sell my personal information. Privacy | Cookies
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
__hssc
30 minutes
HubSpot sets this cookie to keep track of sessions and to determine if HubSpot should increment the session number and timestamps in the __hstc cookie.
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie records the user consent for the cookies in the "Advertisement" category.
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
CookieYes sets this cookie to record the default button state of the corresponding category and the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Cookie
Duration
Description
__cf_bm
30 minutes
Cloudflare set the cookie to support Cloudflare Bot Management.
li_gc
5 months 27 days
Linkedin set this cookie for storing visitor's consent regarding using cookies for non-essential purposes.
lidc
1 day
LinkedIn sets the lidc cookie to facilitate data center selection.
UserMatchHistory
1 month
LinkedIn sets this cookie for LinkedIn Ads ID syncing.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__hstc
5 months 27 days
Hubspot set this main cookie for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
1 year 1 month 4 days
Google Analytics sets this cookie to calculate visitor, session and campaign data and track site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognise unique visitors.
_gat_gtag_UA_*
1 minute
Google Analytics sets this cookie to store a unique user ID.
_gid
1 day
Google Analytics sets this cookie to store information on how visitors use a website while also creating an analytics report of the website's performance. Some of the collected data includes the number of visitors, their source, and the pages they visit anonymously.
AnalyticsSyncHistory
1 month
Linkedin set this cookie to store information about the time a sync took place with the lms_analytics cookie.
CONSENT
2 years
YouTube sets this cookie via embedded YouTube videos and registers anonymous statistical data.
hubspotutk
5 months 27 days
HubSpot sets this cookie to keep track of the visitors to the website. This cookie is passed to HubSpot on form submission and used when deduplicating contacts.
ln_or
1 day
Linkedin sets this cookie to registers statistical data on users' behaviour on the website for internal analytics.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
bcookie
1 year
LinkedIn sets this cookie from LinkedIn share buttons and ad tags to recognize browser IDs.
bscookie
1 year
LinkedIn sets this cookie to store performed actions on the website.
li_sugr
3 months
LinkedIn sets this cookie to collect user behaviour data to optimise the website and make advertisements on the website more relevant.
VISITOR_INFO1_LIVE
5 months 27 days
YouTube sets this cookie to measure bandwidth, determining whether the user gets the new or old player interface.
YSC
session
Youtube sets this cookie to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the user's video preferences using embedded YouTube videos.
yt-remote-device-id
never
YouTube sets this cookie to store the user's video preferences using embedded YouTube videos.
yt.innertube::nextId
never
YouTube sets this cookie to register a unique ID to store data on what videos from YouTube the user has seen.
yt.innertube::requests
never
YouTube sets this cookie to register a unique ID to store data on what videos from YouTube the user has seen.